nyu-visionx/CV-Bench
收藏Hugging Face2025-07-20 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/nyu-visionx/CV-Bench
下载链接
链接失效反馈官方服务:
资源简介:
Cambrian Vision-Centric Benchmark (CV-Bench)数据集旨在解决现有视觉中心基准测试规模有限的问题,包含2638个手动检查的示例,这些示例来源于ADE20k、COCO和OMNI3D等标准视觉基准测试。数据集通过自然语言问题评估模型在2D和3D理解方面的能力,包括空间关系、物体计数、深度顺序和相对距离等任务。数据集包含多个字段,如任务类型、图像、问题、答案选择、正确答案等,用于全面评估模型的多模态理解能力。
The Cambrian Vision-Centric Benchmark (CV-Bench) addresses the limited size of existing vision-centric benchmarks, containing 2638 manually-inspected examples sourced from standard vision benchmarks such as ADE20k, COCO, and OMNI3D. The dataset evaluates models abilities in 2D and 3D understanding through natural language questions, including tasks such as spatial relationships, object counting, depth order, and relative distance. The dataset includes multiple fields such as task type, image, question, answer choices, correct answer, etc., to comprehensively assess the multimodal understanding capabilities of models.
提供机构:
nyu-visionx
原始信息汇总
Cambrian Vision-Centric Benchmark (CV-Bench)
概述
- 名称: Cambrian Vision-Centric Benchmark (CV-Bench)
- 任务类别: 视觉问答 (Visual Question Answering)
- 语言: 英语 (en)
- 许可证: Apache 2.0
文件结构
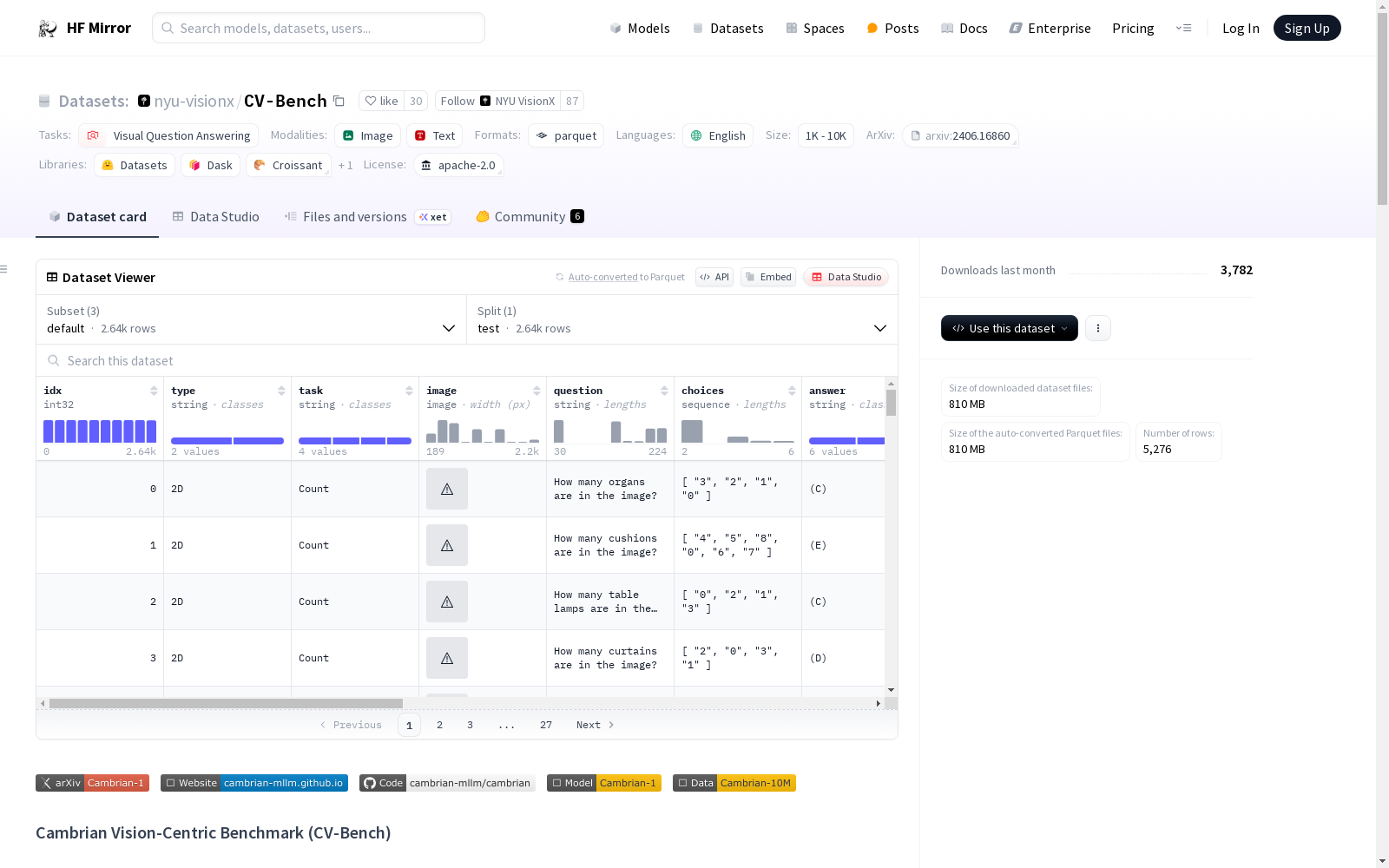
test.parquet: 包含完整数据集注释和预加载的图像,适用于HF Datasets处理。test.jsonl: 文本注释。img/: 包含与注释中filename字段对应的图像。
数据集描述
- 规模: 包含2638个手动检查的示例。
- 来源: 重用标准视觉基准数据集,包括
ADE20k,COCO, 和OMNI3D。 - 任务: 评估模型在多模态上下文中的经典视觉任务,包括2D理解(空间关系和对象计数)和3D理解(深度顺序和相对距离)。
数据字段
| 字段名 | 描述 |
|---|---|
idx |
数据集中条目的全局索引 |
type |
任务类型:2D 或 3D |
task |
与条目相关的任务 |
image |
图像对象 |
question |
关于图像的问题 |
choices |
问题的答案选项 |
answer |
问题的正确答案 |
prompt |
预格式化的问题和选项提示 |
filename |
img/目录中图像的路径 |
source |
图像来源:ADE20K, COCO, 或 Omni3D |
source_dataset |
图像的更详细来源 |
source_filename |
源数据集中图像的文件名 |
target_class |
图像的目标类别(仅适用于COCO图像) |
target_size |
图像的目标大小(仅适用于COCO图像) |
bbox |
图像的边界框(仅适用于Omni3D图像) |
准确性计算
- 公式: [ ext{CV-Bench Accuracy} = frac 1 2 left( frac{ ext{accuracy}{2D{ade}} + ext{accuracy}{2D{coco}}}{2} + ext{accuracy}{3D{omni}} ight) ]
- 示例代码: 提供了一个Python代码示例,用于计算不同来源的准确性并计算综合准确性。
引用
bibtex @misc{tong2024cambrian1, title={Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs}, author={Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie}, year={2024}, eprint={2406.16860}, }
搜集汇总
数据集介绍
构建方式
CV-Bench数据集的构建,是通过整合并重新利用现有的视觉基准测试,如ADE20k、COCO和OMNI3D,以此在多模态环境中评估模型在经典视觉任务上的表现。该数据集包含2638个经过人工检查的示例,每个示例均包含丰富的地面真实标注,用于构建针对模型二维和三维理解能力的自然语言问题。
特点
CV-Bench的特点在于其专注于视觉中心的基准测试,不仅涵盖了二维空间关系和物体计数,还涉及三维深度顺序和相对距离的理解评估。数据集以Parquet文件格式存储注释和预加载的图像,便于处理,同时提供分离的文本注释和图像文件,支持不同任务配置的需求。
使用方法
使用CV-Bench数据集,用户可以通过HuggingFace的datasets库加载整个数据集或特定任务配置的数据集。数据集提供了清晰的字段结构,包括全局索引、任务类型、图像、问题、答案选项、正确答案等,方便研究者进行视觉问答等任务的研究和模型评估。
背景与挑战
背景概述
Cambrian Vision-Centric Benchmark (CV-Bench)是由纽约大学视觉研究团队于2024年推出的一项视觉中心的多模态大型语言模型探索成果。该数据集的核心研究问题在于提升模型在视觉任务中的理解能力,特别是2D和3D空间理解。CV-Bench选取了2638个经过人工检查的示例,重用了标准的视觉基准测试如ADE20k、COCO和OMNI3D,并在多模态环境中对这些任务进行评估。该数据集不仅对视觉理解领域产生了重要影响,也为多模态模型的研究与开发提供了新的视角。
当前挑战
CV-Bench在构建过程中面临的挑战主要包括:一是如何在有限的样本量下确保模型能够学习到丰富的视觉特征;二是如何精确地构建自然语言问题以评估模型在2D和3D理解方面的能力;三是如何高效地整合和利用不同来源的图像和标注数据。此外,该数据集在解决视觉领域问题时,还需面对模型在空间关系和距离估计方面的固有挑战。
常用场景
经典使用场景
在视觉问答领域,Cambrian Vision-Centric Benchmark (CV-Bench) 数据集被广泛用于评估多模态大型语言模型在处理视觉信息方面的能力。该数据集通过精心设计的自然语言问题,探究模型在理解和解释二维与三维视觉场景方面的表现,为研究者提供了一个全面的测试平台。
实际应用
在实际应用中,CV-Bench 数据集的应用场景广泛,包括但不限于智能视觉助手、自动图像理解系统以及增强现实与虚拟现实技术中的交互式场景理解。它为开发能够理解和响应用户视觉查询的应用程序提供了重要的数据支持。
衍生相关工作
基于CV-Bench数据集,研究者们已经衍生出一系列相关工作,如探索多模态学习的新方法、开发更为精确的视觉问答模型以及针对特定视觉任务的高效算法。这些工作不仅推动了视觉问答领域的进步,也为相关领域的交叉融合研究提供了新的视角和工具。
以上内容由遇见数据集搜集并总结生成


