linxy/LaTeX_OCR
收藏Hugging Face2024-06-11 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/linxy/LaTeX_OCR
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
dataset_info:
- config_name: full
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 392478490.025
num_examples: 76319
- name: validation
num_bytes: 43364061.55
num_examples: 8475
- name: test
num_bytes: 47643036.303
num_examples: 9443
download_size: 473618552
dataset_size: 483485587.878
- config_name: human_handwrite
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 16181778
num_examples: 1200
- name: validation
num_bytes: 962283
num_examples: 68
- name: test
num_bytes: 906906
num_examples: 70
download_size: 18056029
dataset_size: 18050967
- config_name: human_handwrite_print
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 3152122.8
num_examples: 1200
- name: validation
num_bytes: 182615
num_examples: 68
- name: test
num_bytes: 181698
num_examples: 70
download_size: 1336052
dataset_size: 3516435.8
- config_name: small
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 261296
num_examples: 50
- name: validation
num_bytes: 156489
num_examples: 30
- name: test
num_bytes: 156489
num_examples: 30
download_size: 588907
dataset_size: 574274
- config_name: synthetic_handwrite
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 496610333.066
num_examples: 76266
- name: validation
num_bytes: 63147351.515
num_examples: 9565
- name: test
num_bytes: 62893132.805
num_examples: 9593
download_size: 616418996
dataset_size: 622650817.3859999
configs:
- config_name: full
data_files:
- split: train
path: full/train-*
- split: validation
path: full/validation-*
- split: test
path: full/test-*
- config_name: human_handwrite
data_files:
- split: train
path: human_handwrite/train-*
- split: validation
path: human_handwrite/validation-*
- split: test
path: human_handwrite/test-*
- config_name: human_handwrite_print
data_files:
- split: train
path: human_handwrite_print/train-*
- split: validation
path: human_handwrite_print/validation-*
- split: test
path: human_handwrite_print/test-*
- config_name: small
data_files:
- split: train
path: small/train-*
- split: validation
path: small/validation-*
- split: test
path: small/test-*
- config_name: synthetic_handwrite
data_files:
- split: train
path: synthetic_handwrite/train-*
- split: validation
path: synthetic_handwrite/validation-*
- split: test
path: synthetic_handwrite/test-*
task_categories:
- image-to-text
tags:
- code
size_categories:
- 100K<n<1M
---
# LaTeX OCR 的数据仓库
本数据仓库是专为 [LaTeX_OCR](https://github.com/LinXueyuanStdio/LaTeX_OCR) 及 [LaTeX_OCR_PRO](https://github.com/LinXueyuanStdio/LaTeX_OCR) 制作的数据,来源于 `https://zenodo.org/record/56198#.V2p0KTXT6eA` 以及 `https://www.isical.ac.in/~crohme/` 以及我们自己构建。
如果这个数据仓库有帮助到你的话,请点亮 ❤️like ++
后续追加新的数据也会放在这个仓库 ~~
> 原始数据仓库在github [LinXueyuanStdio/Data-for-LaTeX_OCR](https://github.com/LinXueyuanStdio/Data-for-LaTeX_OCR).
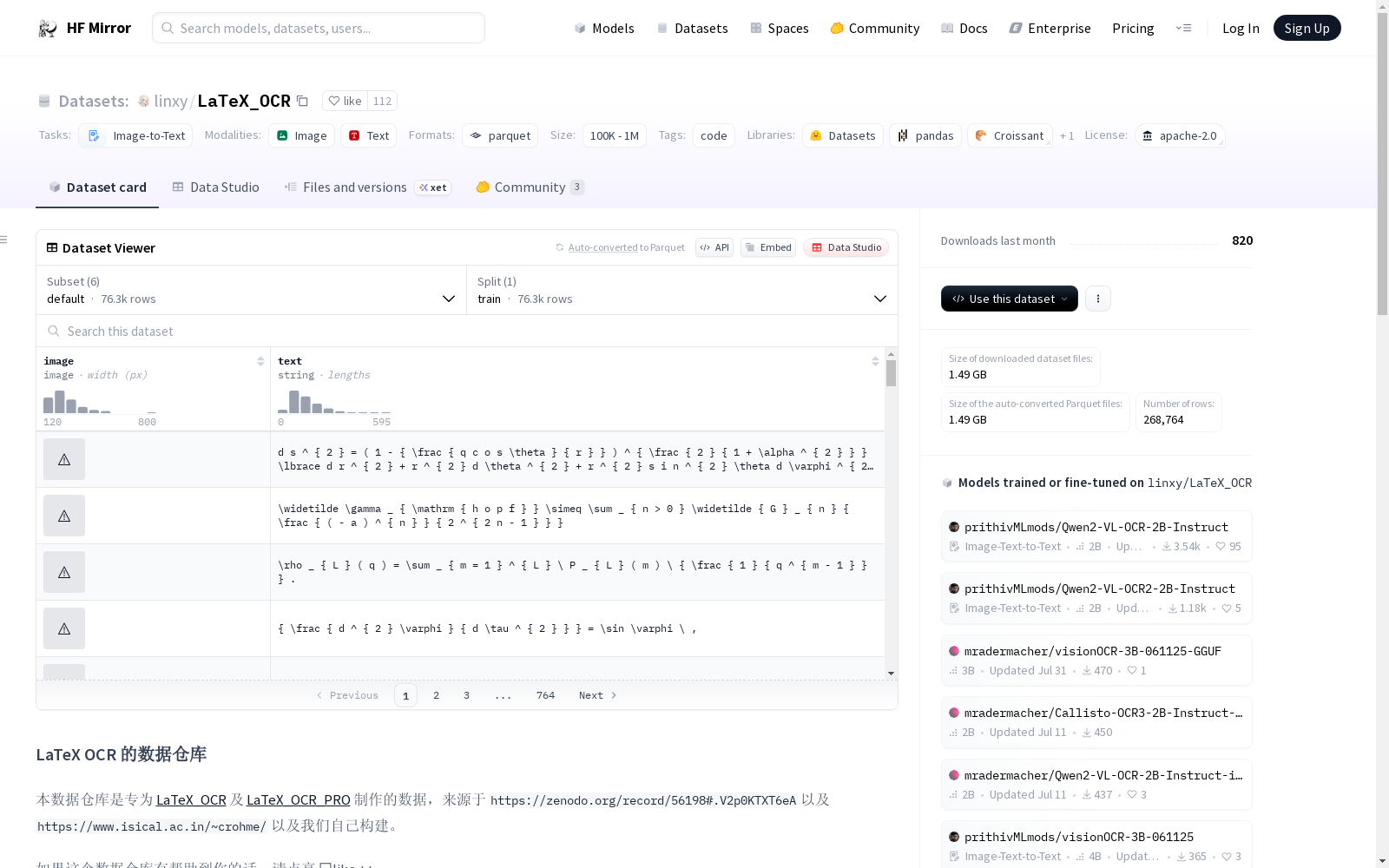
## 数据集
本仓库有 5 个数据集
1. `small` 是小数据集,样本数 110 条,用于测试
2. `full` 是印刷体约 100k 的完整数据集。实际上样本数略小于 100k,因为用 LaTeX 的抽象语法树剔除了很多不能渲染的 LaTeX。
3. `synthetic_handwrite` 是手写体 100k 的完整数据集,基于 `full` 的公式,使用手写字体合成而来,可以视为人类在纸上的手写体。样本数实际上略小于 100k,理由同上。
4. `human_handwrite` 是手写体较小数据集,更符合人类在电子屏上的手写体。主要来源于 `CROHME`。我们用 LaTeX 的抽象语法树校验过了。
5. `human_handwrite_print` 是来自 `human_handwrite` 的印刷体数据集,公式部分和 `human_handwrite` 相同,图片部分由公式用 LaTeX 渲染而来。
## 使用
加载训练集
- name 可选 small, full, synthetic_handwrite, human_handwrite, human_handwrite_print
- split 可选 train, validation, test
```python
>>> from datasets import load_dataset
>>> train_dataset = load_dataset("linxy/LaTeX_OCR", name="small", split="train")
>>> train_dataset[2]["text"]
\rho _ { L } ( q ) = \sum _ { m = 1 } ^ { L } \ P _ { L } ( m ) \ { \frac { 1 } { q ^ { m - 1 } } } .
>>> train_dataset[2]
{'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=200x50 at 0x15A5D6CE210>,
'text': '\\rho _ { L } ( q ) = \\sum _ { m = 1 } ^ { L } \\ P _ { L } ( m ) \\ { \\frac { 1 } { q ^ { m - 1 } } } .'}
>>> len(train_dataset)
50
```
加载所有
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("linxy/LaTeX_OCR", name="small")
>>> dataset
DatasetDict({
train: Dataset({
features: ['image', 'text'],
num_rows: 50
})
validation: Dataset({
features: ['image', 'text'],
num_rows: 30
})
test: Dataset({
features: ['image', 'text'],
num_rows: 30
})
})
```
许可证:Apache-2.0
数据集信息:
- 配置项:full
特征:
- 图像(image):数据类型为图像
- 文本(text):数据类型为字符串
划分集:
- 训练集(train):数据字节数392478490.025,样本数76319
- 验证集(validation):数据字节数43364061.55,样本数8475
- 测试集(test):数据字节数47643036.303,样本数9443
下载大小:473618552,数据集总大小:483485587.878
- 配置项:human_handwrite
特征:
- 图像(image):数据类型为图像
- 文本(text):数据类型为字符串
划分集:
- 训练集(train):数据字节数16181778,样本数1200
- 验证集(validation):数据字节数962283,样本数68
- 测试集(test):数据字节数906906,样本数70
下载大小:18056029,数据集总大小:18050967
- 配置项:human_handwrite_print
特征:
- 图像(image):数据类型为图像
- 文本(text):数据类型为字符串
划分集:
- 训练集(train):数据字节数3152122.8,样本数1200
- 验证集(validation):数据字节数182615,样本数68
- 测试集(test):数据字节数181698,样本数70
下载大小:1336052,数据集总大小:3516435.8
- 配置项:small
特征:
- 图像(image):数据类型为图像
- 文本(text):数据类型为字符串
划分集:
- 训练集(train):数据字节数261296,样本数50
- 验证集(validation):数据字节数156489,样本数30
- 测试集(test):数据字节数156489,样本数30
下载大小:588907,数据集总大小:574274
- 配置项:synthetic_handwrite
特征:
- 图像(image):数据类型为图像
- 文本(text):数据类型为字符串
划分集:
- 训练集(train):数据字节数496610333.066,样本数76266
- 验证集(validation):数据字节数63147351.515,样本数9565
- 测试集(test):数据字节数62893132.805,样本数9593
下载大小:616418996,数据集总大小:622650817.3859999
配置项映射:
- 配置项full:数据文件路径分别为full/train-*(训练集)、full/validation-*(验证集)、full/test-*(测试集)
- 配置项human_handwrite:数据文件路径分别为human_handwrite/train-*(训练集)、human_handwrite/validation-*(验证集)、human_handwrite/test-*(测试集)
- 配置项human_handwrite_print:数据文件路径分别为human_handwrite_print/train-*(训练集)、human_handwrite_print/validation-*(验证集)、human_handwrite_print/test-*(测试集)
- 配置项small:数据文件路径分别为small/train-*(训练集)、small/validation-*(验证集)、small/test-*(测试集)
- 配置项synthetic_handwrite:数据文件路径分别为synthetic_handwrite/train-*(训练集)、synthetic_handwrite/validation-*(验证集)、synthetic_handwrite/test-*(测试集)
任务类别:图像到文本(image-to-text)
标签:代码(code)
样本规模区间:100K < n < 1M
# LaTeX OCR(LaTeX_OCR)数据集仓库
本数据集仓库专为LaTeX OCR(LaTeX_OCR)及LaTeX_OCR_PRO(LaTeX_OCR_PRO)打造,数据来源包括`https://zenodo.org/record/56198#.V2p0KTXT6eA`、`https://www.isical.ac.in/~crohme/`以及自主构建的数据集。
若本仓库对你的研究有所帮助,请点亮❤️点赞。后续新增数据也将上传至本仓库。
> 原始数据集仓库位于GitHub:[LinXueyuanStdio/Data-for-LaTeX_OCR](https://github.com/LinXueyuanStdio/Data-for-LaTeX_OCR)。
## 数据集详情
本仓库共包含5个数据集:
1. `small`:小型测试数据集,总计110条样本,用于快速验证实验流程
2. `full`:完整印刷体数据集,样本规模约10万条。由于通过LaTeX抽象语法树剔除了无法正常渲染的LaTeX公式,实际样本数略少于10万
3. `synthetic_handwrite`:完整合成手写体数据集,基于`full`中的公式,通过手写字体合成生成,效果近似于纸质手写笔迹。同样因LaTeX语法校验,实际样本数略少于10万
4. `human_handwrite`:小型人类手写体数据集,更贴合电子屏幕上的真实手写笔迹,主要来源于CROHME(CROHME)数据集,所有样本均通过LaTeX抽象语法树完成校验
5. `human_handwrite_print`:基于`human_handwrite`生成的印刷体数据集,其对应的LaTeX公式与`human_handwrite`完全一致,图像部分通过LaTeX渲染生成。
## 使用方法
加载训练集:
- `name`参数可选值:small、full、synthetic_handwrite、human_handwrite、human_handwrite_print
- `split`参数可选值:train、validation、test
python
>>> from datasets import load_dataset
>>> train_dataset = load_dataset("linxy/LaTeX_OCR", name="small", split="train")
>>> train_dataset[2]["text"]
\rho _ { L } ( q ) = \sum _ { m = 1 } ^ { L } \ P _ { L } ( m ) \ { \frac { 1 } { q ^ { m - 1 } } } .
>>> train_dataset[2]
{'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=200x50 at 0x15A5D6CE210>,
'text': '\rho _ { L } ( q ) = \sum _ { m = 1 } ^ { L } \ P _ { L } ( m ) \ { \frac { 1 } { q ^ { m - 1 } } } .'}
>>> len(train_dataset)
50
加载全部分割集:
python
>>> from datasets import load_dataset
>>> dataset = load_dataset("linxy/LaTeX_OCR", name="small")
>>> dataset
DatasetDict({
train: Dataset({
features: ['image', 'text'],
num_rows: 50
})
validation: Dataset({
features: ['image', 'text'],
num_rows: 30
})
test: Dataset({
features: ['image', 'text'],
num_rows: 30
})
})
提供机构:
linxy
原始信息汇总
数据集概述
本数据集包含多个配置,每个配置具有不同的特征和数据划分。以下是各配置的详细信息:
配置详情
1. full
- 特征:
image: 图像类型text: 字符串类型
- 数据划分:
train: 392478490.025 字节, 76319 个样本validation: 43364061.55 字节, 8475 个样本test: 47643036.303 字节, 9443 个样本
- 下载大小: 473618552 字节
- 数据集大小: 483485587.878 字节
2. human_handwrite
- 特征:
image: 图像类型text: 字符串类型
- 数据划分:
train: 16181778 字节, 1200 个样本validation: 962283 字节, 68 个样本test: 906906 字节, 70 个样本
- 下载大小: 18056029 字节
- 数据集大小: 18050967 字节
3. human_handwrite_print
- 特征:
image: 图像类型text: 字符串类型
- 数据划分:
train: 3152122.8 字节, 1200 个样本validation: 182615 字节, 68 个样本test: 181698 字节, 70 个样本
- 下载大小: 1336052 字节
- 数据集大小: 3516435.8 字节
4. small
- 特征:
image: 图像类型text: 字符串类型
- 数据划分:
train: 261296 字节, 50 个样本validation: 156489 字节, 30 个样本test: 156489 字节, 30 个样本
- 下载大小: 588907 字节
- 数据集大小: 574274 字节
5. synthetic_handwrite
- 特征:
image: 图像类型text: 字符串类型
- 数据划分:
train: 496610333.066 字节, 76266 个样本validation: 63147351.515 字节, 9565 个样本test: 62893132.805 字节, 9593 个样本
- 下载大小: 616418996 字节
- 数据集大小: 622650817.3859999 字节
数据集使用
数据集可以通过以下方式加载:
python from datasets import load_dataset
加载训练集
train_dataset = load_dataset("linxy/LaTeX_OCR", name="small", split="train")
加载所有数据
dataset = load_dataset("linxy/LaTeX_OCR", name="small")
搜集汇总
数据集介绍
构建方式
LaTeX OCR 数据集的构建基于对图像和对应 LaTeX 文本配对的方式,涵盖了从印刷体到手写体等多种书写风格的数学公式。数据集通过从不同来源汇集图像和文本,经过严格的筛选和校验,确保每个样本都能准确反映 LaTeX 公式的视觉表示和其文本描述。构建过程包括数据清洗、格式统一和抽象语法树校验等多个步骤,以保证数据质量和可用性。
特点
本数据集的特点在于其多样性、全面性和准确性。它包含了从小规模测试集到大规模训练集的不同规模配置,能够满足不同研究需求。数据集中的图像涵盖了从标准印刷体到模拟手写体,再到真实人类手写体,为模型训练提供了丰富的学习材料。每个图像都与 LaTeX 格式的文本精确对应,便于模型学习和评估。
使用方法
使用该数据集时,用户可以根据需求选择不同的配置,如 'small' 用于快速测试,'full' 提供了丰富的训练样本。通过 HuggingFace 的 datasets 库,用户可以轻松加载和访问数据集,支持多种数据处理和加载方式,如按比例划分训练集、验证集和测试集,以及按需加载特定样本。数据集的加载和预处理过程简单直观,便于研究者快速开展相关研究。
背景与挑战
背景概述
LaTeX OCR数据集,由LinXueyuanStdio构建,旨在推进数学公式识别领域的研究。该数据集的创建时间为近年,主要研究人员为LinXueyuanStdio团队,其核心研究问题是如何准确地将图像中的LaTeX格式数学公式转化为可编辑的文本形式。该数据集汇集了从Zenodo、ISICAL等多个来源的数据,并对数据进行了严格的抽象语法树校验,以剔除无法渲染的LaTeX公式,对相关领域产生了重要影响。
当前挑战
数据集在构建过程中遇到的挑战主要包括:如何确保数学公式的多样性和准确性,以及如何处理手写体与印刷体之间的差异。此外,数据集在解决图像到文本转换的领域问题中,面临的挑战是如何提高识别准确率,尤其是在手写体识别方面,以及如何优化算法以处理大量数据。
常用场景
经典使用场景
在光学字符识别(OCR)领域,linxy/LaTeX_OCR数据集的典型应用场景是训练深度学习模型,以实现对LaTeX格式数学公式的识别和转换。该数据集提供了大量的图像与对应的LaTeX文本,为模型提供了丰富的学习材料,从而在识别数学公式时,模型能够更加精确地理解和还原复杂的数学符号和结构。
实际应用
在实际应用中,linxy/LaTeX_OCR数据集的应用场景广泛,包括但不限于学术论文数字化、在线教育平台中数学公式的识别与展示、科研人员对学术资料的快速检索与重用等。它为各种OCR工具和应用程序提供了高质量的训练数据,从而提升了这些工具在实际使用中的准确性和可靠性。
衍生相关工作
linxy/LaTeX_OCR数据集的发布促进了相关领域的研究,衍生出了一系列经典工作。研究者基于该数据集,开发了多种高效的数学公式识别算法,并在各项评测中取得了显著成果。此外,该数据集还激发了更多关于OCR技术在数学公式识别上的创新研究,进一步拓宽了OCR技术的应用边界。
以上内容由遇见数据集搜集并总结生成


