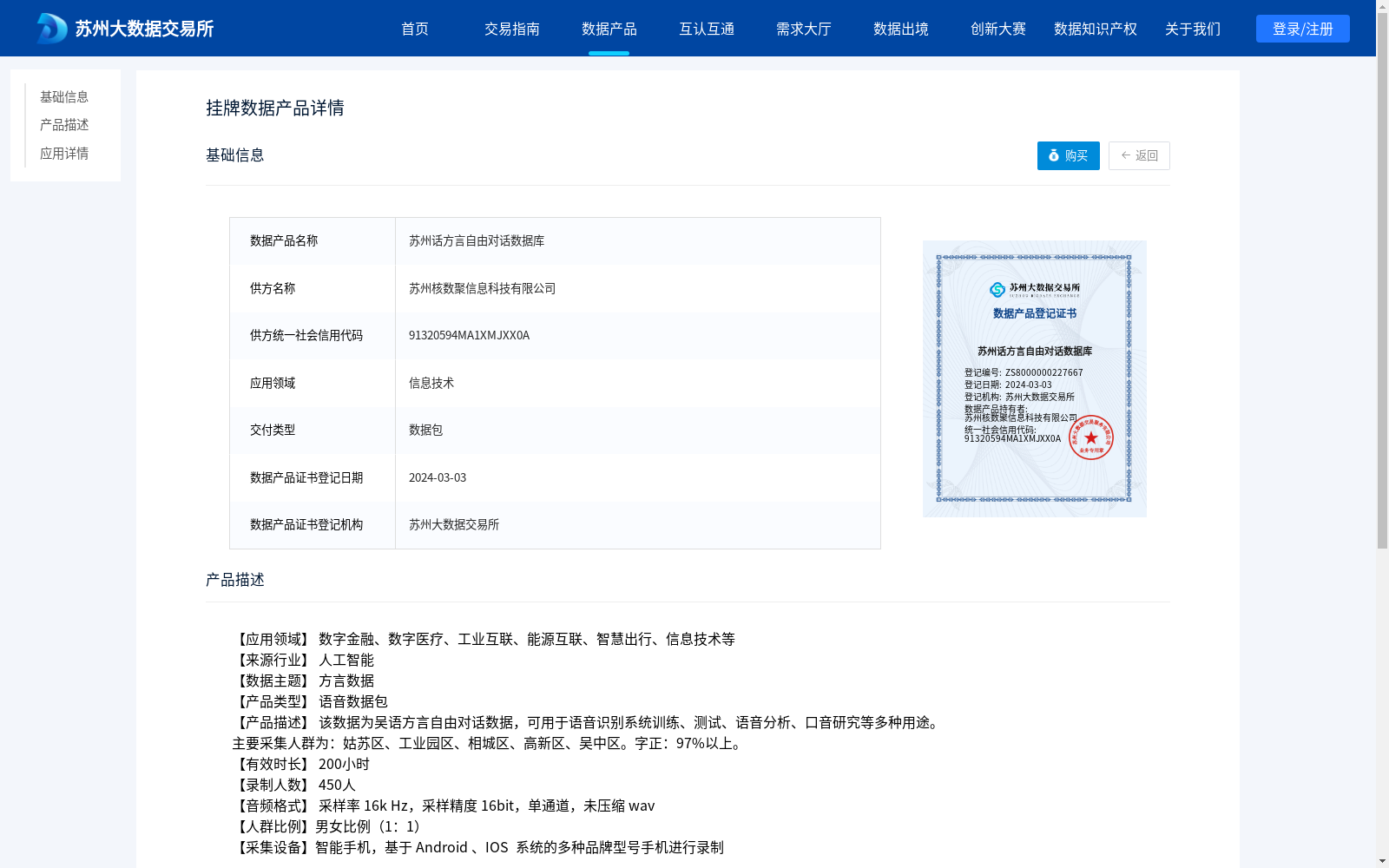
苏州话方言自由对话数据库
收藏苏州大数据交易所2024-03-03 更新2024-04-26 收录
下载链接:
https://jy.suzhou.com.cn/#/product-detail/730
下载链接
链接失效反馈官方服务:
资源简介:
【应用领域】 数字金融、数字医疗、工业互联、能源互联、智慧出行、信息技术等 【来源行业】 人工智能 【数据主题】 方言数据 【产品类型】 语音数据包 【产品描述】 该数据为吴语方言自由对话数据,可用于语音识别系统训练、测试、语音分析、口音研究等多种用途。 主要采集人群为:姑苏区、工业园区、相城区、高新区、吴中区。字正:97%以上。 【有效时长】 200小时 【录制人数】 450人 【音频格式】 采样率 16k Hz,采样精度 16bit,单通道,未压缩 wav 【人群比例】男女比例(1:1) 【采集设备】智能手机,基于 Android 、IOS 系统的多种品牌型号手机进行录制
Application Domains: Digital finance, digital healthcare, industrial internet, energy internet, smart mobility, information technology, etc.
Source Industry: Artificial Intelligence
Data Theme: Dialect Data
Product Type: Voice Data Package
Product Description: This dataset comprises free conversational data in Wu dialect, which can be applied to multiple scenarios including speech recognition system training, testing, speech analysis, accent research and more. The primary speakers are recruited from Gusu District, Suzhou Industrial Park, Xiangcheng District, High-tech Zone and Wuzhong District, with an articulation accuracy rate of over 97%.
Valid Duration: 200 hours
Number of Speakers: 450
Audio Format: Sampling rate of 16 kHz, sampling precision of 16-bit, single-channel, uncompressed WAV
Gender Proportion: Male-to-female ratio is 1:1
Collection Equipment: Smartphones, with recordings performed using multiple branded and model-specific mobile phones based on Android and iOS operating systems.
提供机构:
苏州核数聚信息科技有限公司
创建时间:
2024-03-03
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个包含200小时苏州话自由对话的语音数据库,采集自450名说话者,男女比例均衡,音频质量高,适用于语音识别和方言研究。
以上内容由遇见数据集搜集并总结生成


