Food_Reccomendation
收藏Hugging Face2025-08-08 更新2025-08-09 收录
下载链接:
https://huggingface.co/datasets/AnjaliNV/Food_Reccomendation
下载链接
链接失效反馈官方服务:
资源简介:
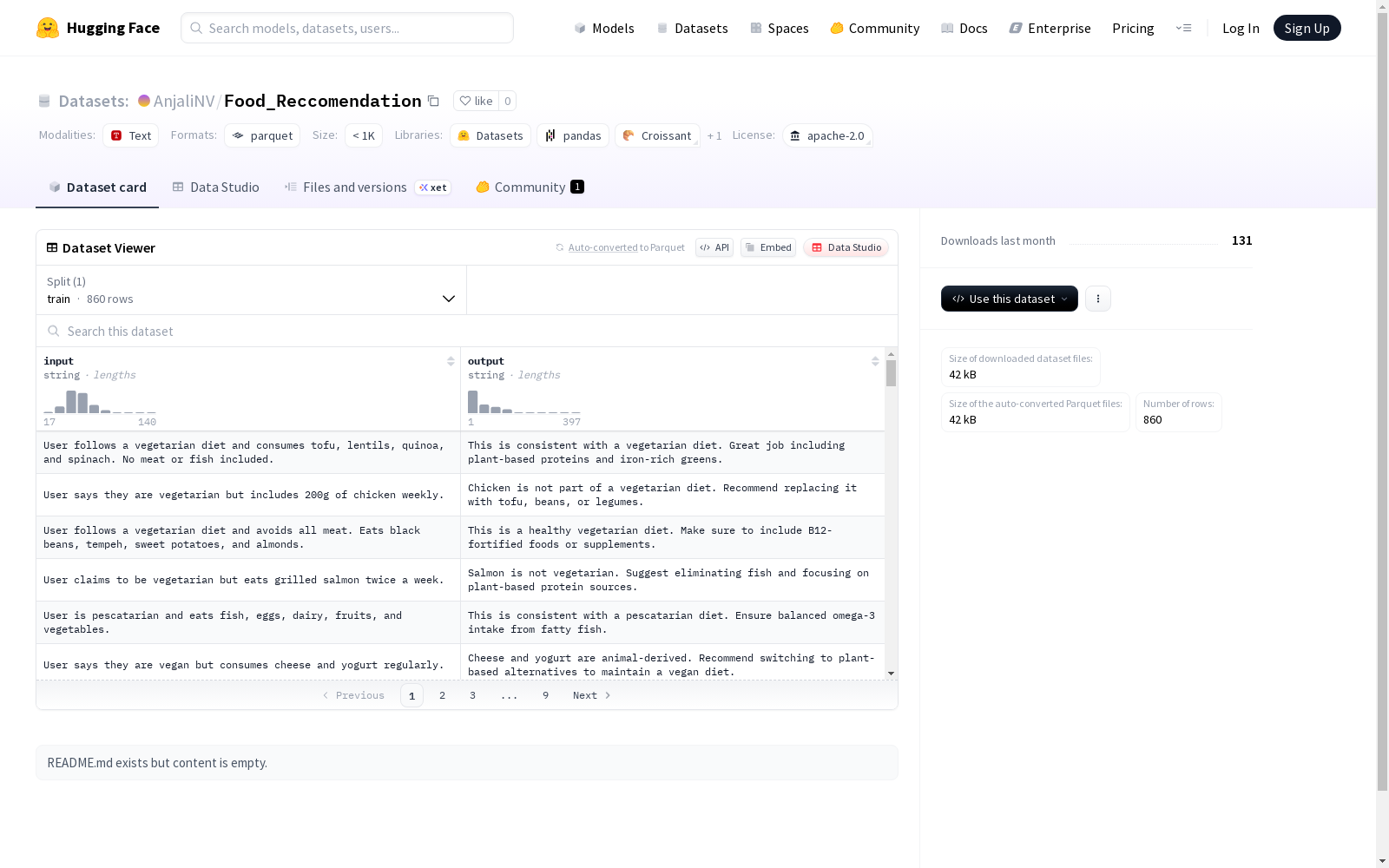
该数据集包含输入和输出两个字符串类型的特征,适用于训练文本生成或文本处理模型。数据集分为训练集,共有93个样本,数据集大小为17505字节。
This dataset includes two string-type features: input and output, and is suitable for training text generation or text processing models. The dataset is split into a training set, which contains a total of 93 samples with an overall size of 17505 bytes.
创建时间:
2025-07-30
搜集汇总
数据集介绍
构建方式
在食品推荐这一交叉学科领域,数据集的构建采用了结构化数据采集方法。该数据集通过收集用户饮食偏好与营养需求的对应关系,形成了包含输入查询和推荐输出的文本对。训练集包含860个高质量样本,每个样本经过人工校验确保推荐内容的合理性和准确性,数据以Apache 2.0许可协议开放使用。
特点
该数据集呈现显著的实用特征,其文本字段采用字符串格式存储,确保了数据的灵活性和扩展性。样本规模精炼而具有代表性,102KB的紧凑尺寸兼顾了处理效率与信息密度。数据分割仅包含训练集,这为推荐系统模型的训练与验证提供了专门化的数据基础,适合用于饮食推荐场景的算法开发。
使用方法
使用者可通过HuggingFace数据集库直接加载该资源,利用默认配置即可访问训练分割下的数据文件。数据以input-output配对形式组织,输入字段代表饮食需求描述,输出字段对应推荐内容。研究人员可据此训练序列到序列的推荐模型,或通过微调现有语言模型来开发个性化的食品推荐系统。
背景与挑战
背景概述
随着个性化推荐系统在数字消费领域的广泛应用,食品推荐数据集应运而生。该数据集由研究团队基于Apache 2.0许可协议构建,专注于解决饮食偏好与营养需求的智能匹配问题。通过860条训练样本,它记录了用户输入与系统推荐食品之间的对应关系,为餐饮服务、健康管理等领域提供了数据支撑。这类数据集的出现推动了基于自然语言处理的食品推荐算法发展,帮助研究者探索多模态数据在饮食决策中的应用潜力。
当前挑战
食品推荐领域面临用户口味多样性、文化差异及营养均衡等多重复杂性,要求模型兼顾个性化与科学性。数据集构建过程中,需克服真实场景数据稀疏性、标注一致性问题,以及饮食禁忌与过敏原等安全信息的精确捕捉。此外,如何平衡数据规模与标注质量,确保推荐结果既符合用户偏好又满足健康需求,仍是当前研究的核心难点。
常用场景
经典使用场景
在饮食推荐系统研究中,Food_Reccomendation数据集常被用于训练和评估基于自然语言处理的个性化推荐模型。通过分析用户的输入描述与推荐食物输出之间的映射关系,研究者能够探索如何精准捕捉用户的饮食偏好与情境需求,进而优化推荐算法的准确性与实用性。
实际应用
实际应用中,该数据集可支撑智能餐饮助手、健康管理平台及外卖推荐系统的开发。通过理解用户的自然语言请求,如“想要低热量的早餐选择”,系统能够提供符合特定需求的饮食建议,提升用户体验并促进健康饮食文化的普及。
衍生相关工作
基于该数据集,研究者已开展多项经典工作,包括基于序列到序列模型的饮食推荐生成、结合知识图谱的个性化推荐框架探索,以及多模态输入下的饮食建议系统研究。这些工作显著丰富了饮食推荐领域的技术路线与应用范式。
以上内容由遇见数据集搜集并总结生成


