MEET-MR
收藏MEET-MR: English-Thai MQM Ranking Dataset 数据集概述
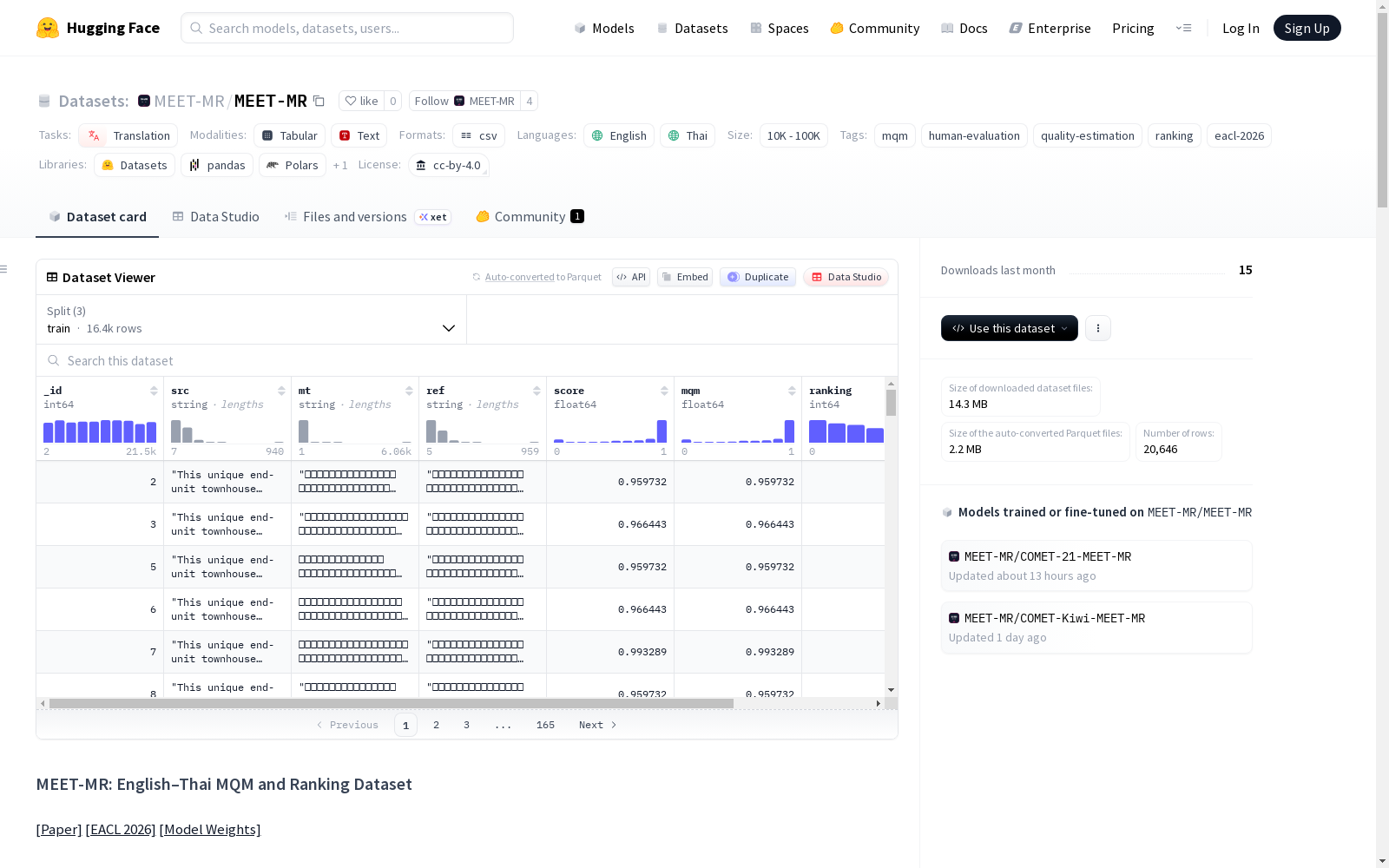
数据集基本信息
- 数据集名称: MEET-MR: English-Thai MQM Ranking Dataset
- 许可协议: Creative Commons Attribution 4.0 International License (CC-BY-4.0)
- 任务类别: 翻译
- 涉及语言: 英语 (en)、泰语 (th)
- 标签: mqm、human-evaluation、quality-estimation、ranking、eacl-2026
- 数据规模: 10K<n<100K
- 总样本数: 20,646 个片段
数据内容与结构
- 数据字段:
_id: 样本标识符 (int64)src: 源文本 (英语) (string)mt: 机器翻译文本 (泰语) (string)ref: 参考译文 (泰语) (string)score: 分数 (float64)mqm: MQM分数 (float64)ranking: 排名 (int64)domain: 领域 (string)
- 数据划分:
- 训练集 (train): 16,447 个样本
- 验证集 (validation): 2,050 个样本
- 测试集 (test): 2,149 个样本
数据集特点与目标
- 领域: 多样化,涵盖教育、医疗、条约、图像描述、技术等。
- 评估方式: 提供细粒度MQM错误标签(轻微、重大、严重)和整体10向人工偏好排名。
- MQM分数范围: 0.0(不可用)至 1.0(完美)。
- 目标: 实现精确的翻译质量估计以及模型与人类判断的对齐。
数据构成与统计
- 划分策略: 采用分层80:10:10比例划分,以保持各划分间的领域一致性。
- 领域分布:
- 教育 (Education): 2,897
- 对话 (Conversation): 2,840
- 社交 (Social): 2,730
- 新闻 (News): 2,460
- 医疗 (Medical): 2,043
- 条约 (Treaty): 1,901
- 电子商务 (E-commerce): 1,780
- COCO (图像描述): 1,337
- 手册 (Manuals): 1,065
- Bunny (预训练/微调): 1,503
- 智慧城市 (Smart City): 90
- 文本特征:
- 平均机器翻译文本长度: 98.56 字符
- 平均参考译文长度: 96.00 字符
性能基准
在MEET-MR上微调评估模型,相比标准预训练检查点,能显著提升其与人类判断的相关性。
- 评估指标: 肯德尔τ系数(与人类评估的一致性)
- 关键结果:
- 微调后的COMET-kiwi模型在MQM和排名任务上分别达到0.402和0.415的τ分数。
- LLM零样本评估中,Gemini-2.5-Pro表现最佳,τ分数分别为0.463(MQM)和0.455(排名)。
数据格式示例
数据以JSON格式存储,示例如下: json { "_id": 291, "src": "Better jobs lead to better pay, better pay to better possessions...", "mt": "งานที่ดีกว่านำไปสู่เงินเดือนที่ดีขึ้น...", "ref": "งานที่ดีกว่านำไปสู่ค่าแรงที่ดีขึ้น...", "score": 1.0, "ranking": 0, "domain": "education" }
注:排名0表示在候选集中为顶级偏好(最佳)。
引用信息
如需引用,请使用以下BibTeX条目: bibtex @inproceedings{phuangrot2026meetmr, title={Machine Translation Evaluation English-Thai MQM Ranking Dataset}, author={Phuangrot, Phichet and Trintawat, Natdanai and Vilasri, Kanawat and Patcharawiwatpong, Yanapat and Boonsarngsuk, Pachara and Pavasant, Nat and Chuangsuwanich, Ekapol}, booktitle={Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL)}, year={2026}, url={https://openreview.net/forum?id=0IbK0VeN8y} }