CrowdHuman 人脸检测数据集
收藏超神经2023-09-08 更新2024-05-15 收录
下载链接:
https://hyper.ai/cn/datasets/17239
下载链接
链接失效反馈官方服务:
资源简介:
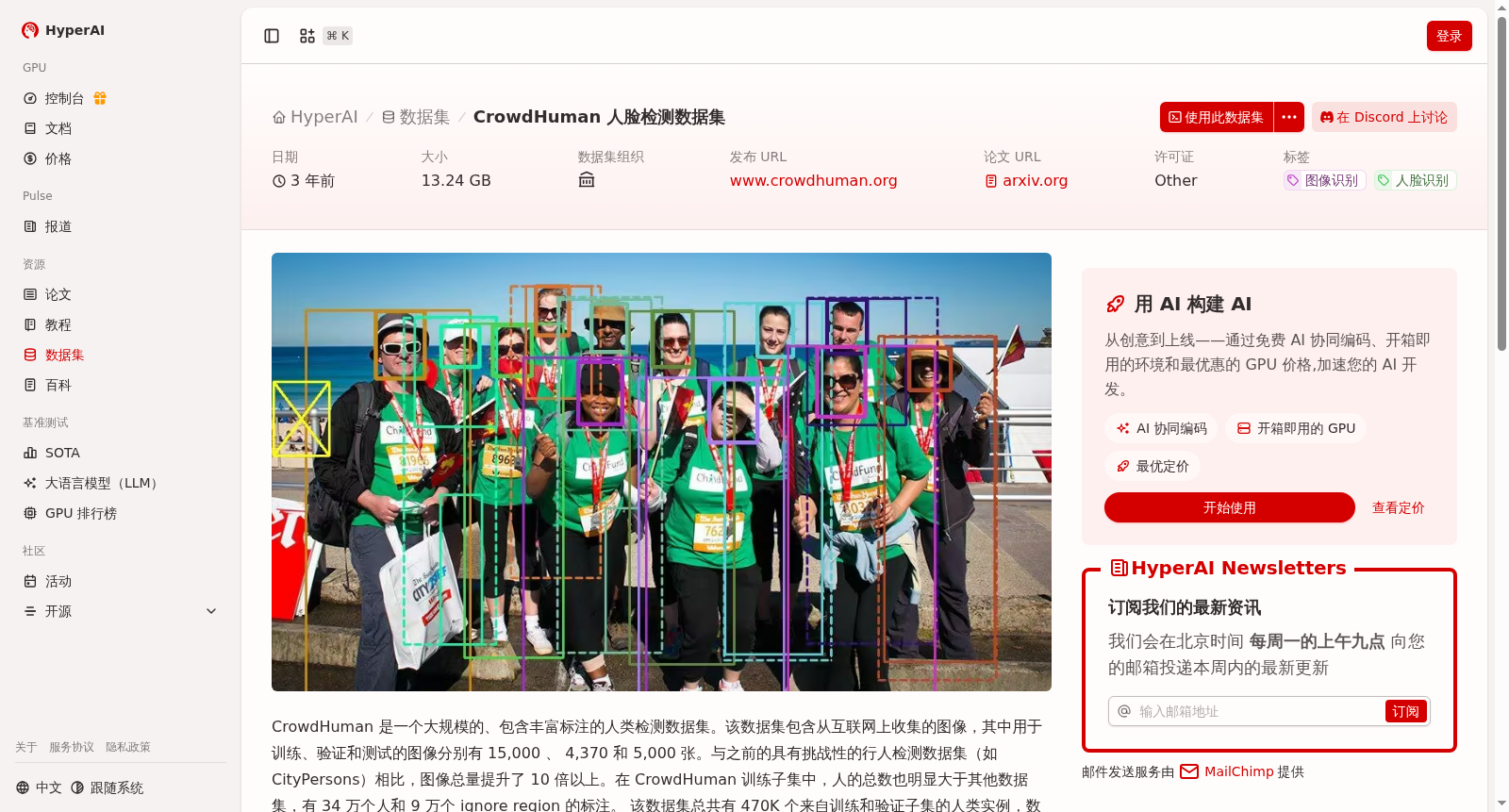
CrowdHuman 是一个大规模的、包含丰富标注的人类检测数据集。该数据集包含从互联网上收集的图像,其中用于训练、验证和测试的图像分别有 15,000 、 4,370 和 5,000 张。与之前的具有挑战性的行人检测数据集(如 CityPersons)相比,图像总量提升了 10 倍以上。在 CrowdHuman 训练子集中,人的总数也明显大于其他数据集,有 34 万个人和 9 万个 ignore region 的标注。
CrowdHuman is a large-scale, richly annotated human detection dataset. This dataset comprises images collected from the Internet, with 15,000, 4,370 and 5,000 images allocated for training, validation and testing respectively. Compared with prior challenging pedestrian detection datasets such as CityPersons, the total number of images in CrowdHuman is more than 10 times larger. In the training subset of CrowdHuman, the total number of human instances is also significantly larger than that of other datasets, with 340,000 human instances and 90,000 annotated ignore regions.
创建时间:
2023-05-06
搜集汇总
数据集介绍
背景与挑战
背景概述
CrowdHuman是一个大规模的人脸检测数据集,包含15,000张训练图像、4,370张验证图像和5,000张测试图像,总计标注了470K个人类实例。该数据集以高密度人群和多样遮挡场景为特点,每张图片平均包含23个人,并提供了头部、可见区域和全身三种bounding-box标注。
以上内容由遇见数据集搜集并总结生成


