Open-Sora-Plan-v1.3.0
收藏Hugging Face2024-10-22 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/LanguageBind/Open-Sora-Plan-v1.3.0
下载链接
链接失效反馈官方服务:
资源简介:
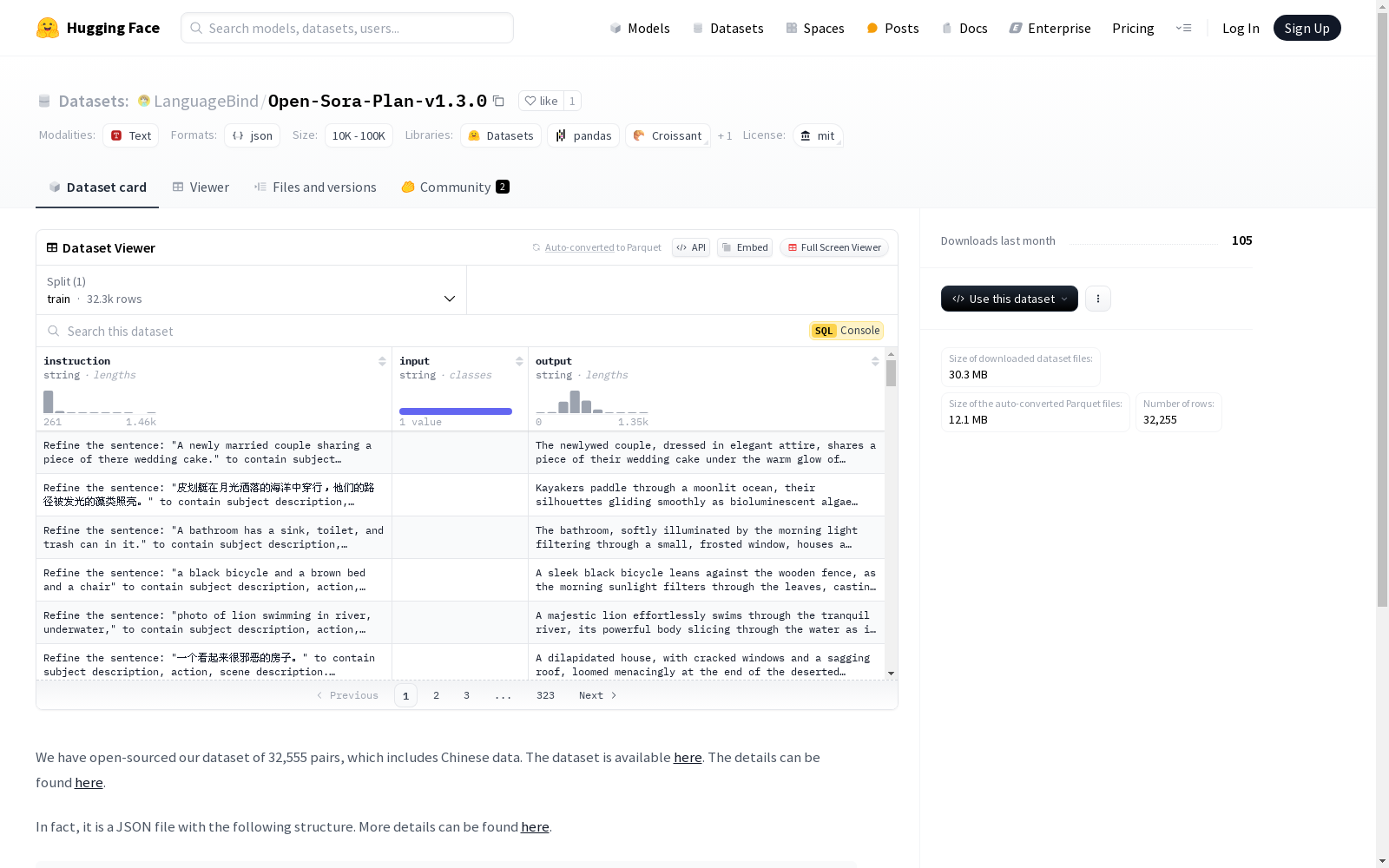
该数据集包含32,555对数据,其中包括中文数据。数据集是一个JSON文件,结构包括'instruction'、'input'和'output'字段。'instruction'字段描述了如何细化句子,'input'字段通常为空,'output'字段包含细化后的句子。
创建时间:
2024-10-22
原始信息汇总
Open-Sora-Plan-v1.3.0 数据集概述
数据集信息
- 数据集名称: Open-Sora-Plan-v1.3.0
- 数据集大小: 32,555 对数据
- 数据集语言: 包含中文数据
- 数据集格式: JSON
- 数据集结构: json [ { "instruction": "Refine the sentence: "A newly married couple sharing a piece of there wedding cake." to contain subject description, action, scene description. (Optional: camera language, light and shadow, atmosphere) and conceive some additional actions to make the sentence more dynamic. Make sure it is a fluent sentence, not nonsense.", "input": "", "output": "The newlywed couple, dressed in elegant attire..." }, ... ]
数据集链接
搜集汇总
数据集介绍
构建方式
Open-Sora-Plan-v1.3.0数据集的构建基于32,555对中英双语数据,涵盖了丰富的语言表达场景。数据集的生成过程通过精心设计的提示词优化任务,确保每对数据包含指令、输入和输出三个部分。指令部分要求对句子进行细化,包含主体描述、动作、场景描述等要素,并可选添加相机语言、光影和氛围等细节。输入部分为空,输出部分则是对指令的详细回应,形成流畅且动态的句子。
特点
该数据集的特点在于其多样性和精细化的语言处理任务。每对数据均经过精心设计,旨在提升语言表达的丰富性和动态性。数据集不仅包含基础的语言描述,还融入了相机语言、光影和氛围等高级元素,使得生成的句子更具画面感和表现力。此外,数据集中文数据的加入,进一步扩展了其应用场景,为多语言处理任务提供了有力支持。
使用方法
使用Open-Sora-Plan-v1.3.0数据集时,用户可通过加载JSON文件获取数据。每对数据包含指令、输入和输出三个字段,用户可根据指令部分的要求进行语言优化任务。数据集适用于自然语言处理、机器翻译、文本生成等领域的研究和开发。通过分析输出部分的详细回应,用户可以深入理解如何将基础句子转化为更具表现力的语言表达,从而提升模型的语言生成能力。
背景与挑战
背景概述
Open-Sora-Plan-v1.3.0数据集由PKU-YuanGroup于近期发布,旨在推动自然语言处理领域中的文本生成与优化研究。该数据集包含32,555对中英文数据,主要用于文本提示的精细化处理任务。其核心研究问题在于如何通过指令引导模型生成更加流畅、动态且符合场景描述的文本。该数据集的发布为文本生成模型的训练与评估提供了丰富的资源,特别是在多语言环境下,进一步推动了跨语言文本生成技术的发展。
当前挑战
Open-Sora-Plan-v1.3.0数据集在解决文本生成与优化问题时面临多重挑战。首先,如何确保生成的文本在语法正确的同时,能够准确捕捉场景描述、动作细节以及氛围渲染,是一个复杂的任务。其次,数据集的构建过程中,需要处理大量中英文对照数据,这对数据清洗、对齐与标注提出了较高要求。此外,如何在多语言环境下保持生成文本的一致性与流畅性,也是该数据集需要克服的关键问题。这些挑战不仅考验了数据集的构建质量,也对后续模型的训练与优化提出了更高的标准。
常用场景
经典使用场景
Open-Sora-Plan-v1.3.0数据集在自然语言处理领域中被广泛用于文本生成与优化任务。其经典使用场景包括通过指令对文本进行精细化处理,生成更具描述性和动态感的句子。研究人员和开发者可以利用该数据集中的指令-输出对,训练模型以提升文本生成的质量和多样性,尤其在涉及场景描述、动作构思和语言流畅性方面表现出色。
实际应用
在实际应用中,Open-Sora-Plan-v1.3.0数据集被广泛应用于内容创作、广告文案生成以及影视剧本辅助写作等领域。例如,广告公司可以利用该数据集生成更具吸引力的产品描述,而影视编剧则可以通过模型优化场景描述和角色动作,提升剧本的生动性和表现力。此外,该数据集还可用于教育领域,帮助学生提升写作能力和语言表达能力。
衍生相关工作
基于Open-Sora-Plan-v1.3.0数据集,衍生了一系列经典研究工作。例如,研究人员开发了基于指令的文本生成模型,能够根据用户需求生成高质量的文本内容。此外,该数据集还被用于多模态学习的研究,结合视觉和文本信息,生成更具表现力的多模态内容。这些工作不仅推动了自然语言处理领域的发展,也为相关应用场景提供了技术支持。
以上内容由遇见数据集搜集并总结生成


