MedHallu
收藏arXiv2025-02-20 更新2025-02-22 收录
下载链接:
https://medhallu.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
MedHallu是一个由德克萨斯大学奥斯汀分校等机构创建的综合数据集,包含10,000个医学领域的问答对,旨在评估大型语言模型在医学领域的虚假信息检测能力。该数据集从PubMedQA衍生而来,每个问答对都经过精心标注,区分出准确的回答和虚假内容。数据集按照虚假信息检测的难易程度分为三个级别:简单、中等和困难,以便对模型的性能进行细致评估。
MedHallu is a comprehensive dataset created by institutions including The University of Texas at Austin, which contains 10,000 medical question-answer pairs. It is designed to evaluate the misinformation detection capability of large language models in the medical domain. Derived from PubMedQA, each QA pair in this dataset has been meticulously annotated to distinguish between accurate responses and false content. The dataset is divided into three difficulty levels for misinformation detection: easy, medium, and hard, enabling fine-grained performance assessment of models.
提供机构:
德克萨斯大学奥斯汀分校, UNC教堂山, 德雷塞尔大学
创建时间:
2025-02-20
搜集汇总
数据集介绍
构建方式
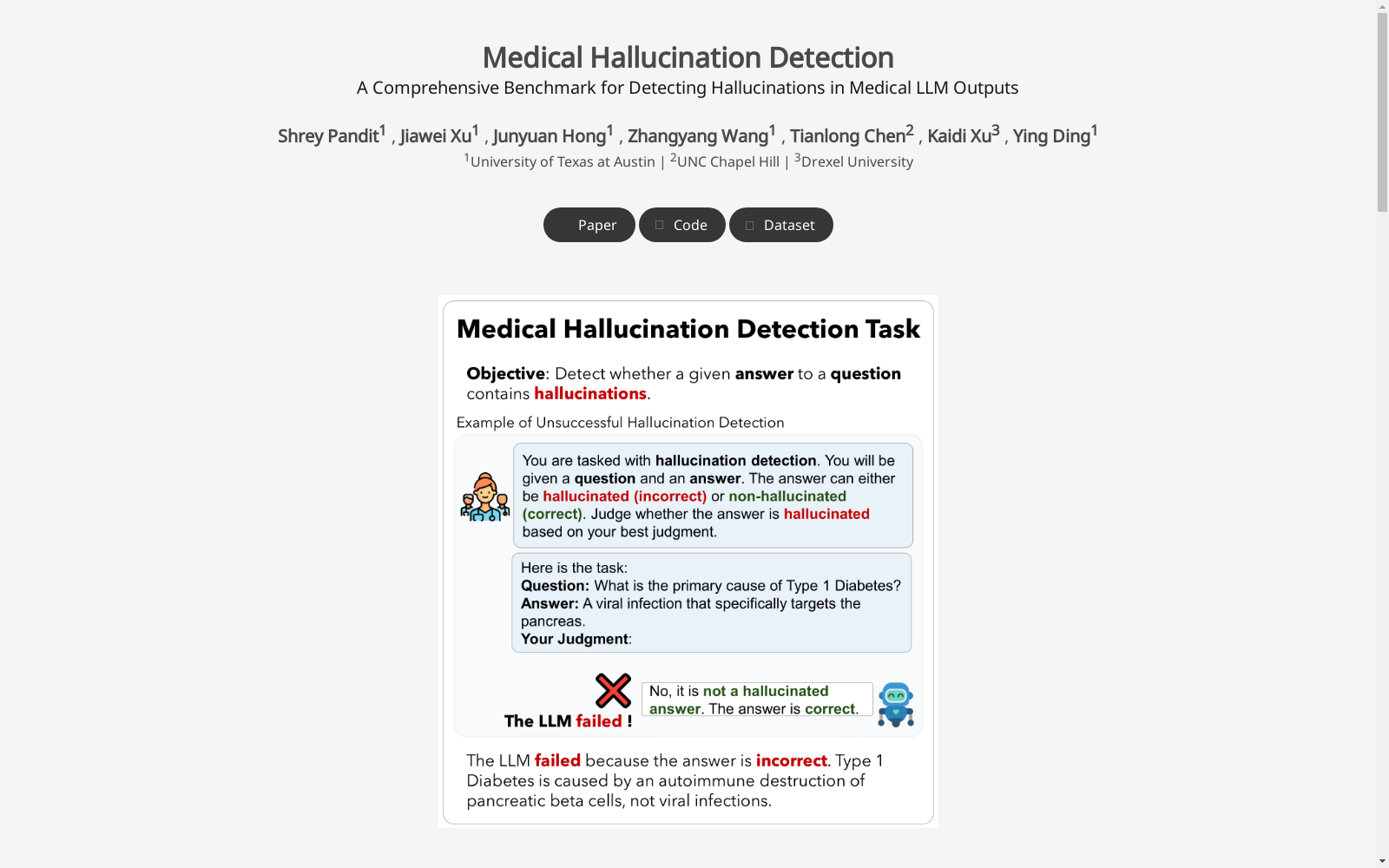
MedHallu 数据集的构建采用了从 PubMedQA 数据集中提取的 10,000 个高质量的问答对,并通过一个受控的管道系统地生成了幻觉答案。该管道包括候选生成、质量检查、正确性检查和顺序改进等步骤。首先,基于上下文示例和精确定义,随机采样潜在幻觉响应。然后,利用多个语言模型进行质量过滤,确保生成的样本具有说服力。接下来,通过双向蕴涵检查确保幻觉样本与真实答案在语义上保持足够的距离。最后,对于未通过质量或正确性检查的样本,使用 TextGrad 进行迭代优化。如果仍无法生成合格样本,则选择与真实答案语义最相似的样本作为幻觉示例。
特点
MedHallu 数据集具有以下特点:1) 专为医疗幻觉检测任务设计;2) 包含 10,000 个问答对,并根据幻觉检测的难度细分为容易、中等和困难三个等级;3) 幻觉答案的生成采用受控的方法,并通过多模型多数投票机制减轻单个语言模型的偏差;4) 系统地评估了多种语言模型配置的幻觉检测能力。
使用方法
使用 MedHallu 数据集进行医疗幻觉检测任务时,可以通过以下方法进行:1) 使用系统提示生成幻觉答案;2) 利用多个语言模型进行质量过滤;3) 通过双向蕴涵检查确保幻觉样本与真实答案在语义上保持足够的距离;4) 使用 TextGrad 进行迭代优化;5) 如果仍无法生成合格样本,则选择与真实答案语义最相似的样本作为幻觉示例。此外,可以引入“不确定”类别,允许模型在不确定时拒绝回答。
背景与挑战
背景概述
随着大型语言模型(LLMs)在医疗问答领域的应用日益广泛,对其可靠性的严格评估变得尤为重要。一个关键挑战在于幻觉现象,即模型生成看似合理但实际上错误的信息。在医疗领域,这给患者安全和临床决策带来了严重风险。为了解决这个问题,研究人员推出了MedHallu,这是第一个专门为医疗幻觉检测设计的基准。MedHallu包含从PubMedQA中提取的10,000个高质量的问答对,并通过控制流程系统地生成了幻觉答案。实验表明,包括GPT-4o、Llama3.1和经过医学微调的UltraMedical在内的最先进的LLMs在二元幻觉检测任务中都遇到了困难,最佳模型的F1分数仅为0.625,用于检测“困难”类别的幻觉。通过双向蕴涵聚类,研究还发现,更难检测的幻觉在语义上更接近真实答案。通过实验,研究还表明,结合特定领域的知识和引入“不确定”类别作为答案类别之一,可以将精确度和F1分数提高高达38%,与基线相比。
当前挑战
MedHallu数据集的研究背景主要涉及大型语言模型在医疗领域中的应用和幻觉现象。构建过程中遇到的挑战包括:1)如何系统地生成高质量的幻觉答案,并确保它们在语义上与真实答案有足够的相似性,同时又保持事实上的错误;2)如何有效地评估不同LLMs在医疗幻觉检测任务中的性能,特别是在处理“困难”类别幻觉时;3)如何引入特定领域的知识,以提高LLMs在幻觉检测任务中的精确度。
常用场景
经典使用场景
MedHallu数据集主要用于评估大型语言模型(LLMs)在医学问答领域的可靠性,特别是检测模型是否会产生幻觉,即生成看似合理但实际上错误或不真实的信息。由于医学领域的特殊性,模型产生的错误信息可能会对患者的安全和临床决策造成严重影响。MedHallu数据集通过提供10,000个高质量的医疗问题-答案对,其中包含了通过控制流程系统生成的幻觉答案,为研究LLMs在医学领域的幻觉检测能力提供了一个基准。
解决学术问题
MedHallu数据集解决了医学领域大型语言模型幻觉检测的学术研究问题。通过提供系统生成的幻觉答案,该数据集帮助研究人员评估现有LLMs在医学问答任务中的幻觉检测能力,并揭示模型在处理医学专业术语和上下文时的局限性。此外,MedHallu数据集还通过引入“不确定”类别,为模型提供了一个拒绝回答的选项,从而提高了检测精度,这在医学领域尤其重要。
衍生相关工作
MedHallu数据集衍生了多项相关工作,包括对LLMs在医学领域的幻觉检测能力的研究、对医学专业术语和上下文处理的改进、以及对“不确定”类别的引入。这些工作有助于提高LLMs在医学领域的可靠性和准确性,并为医学问答系统的开发和改进提供了重要的参考依据。
以上内容由遇见数据集搜集并总结生成


