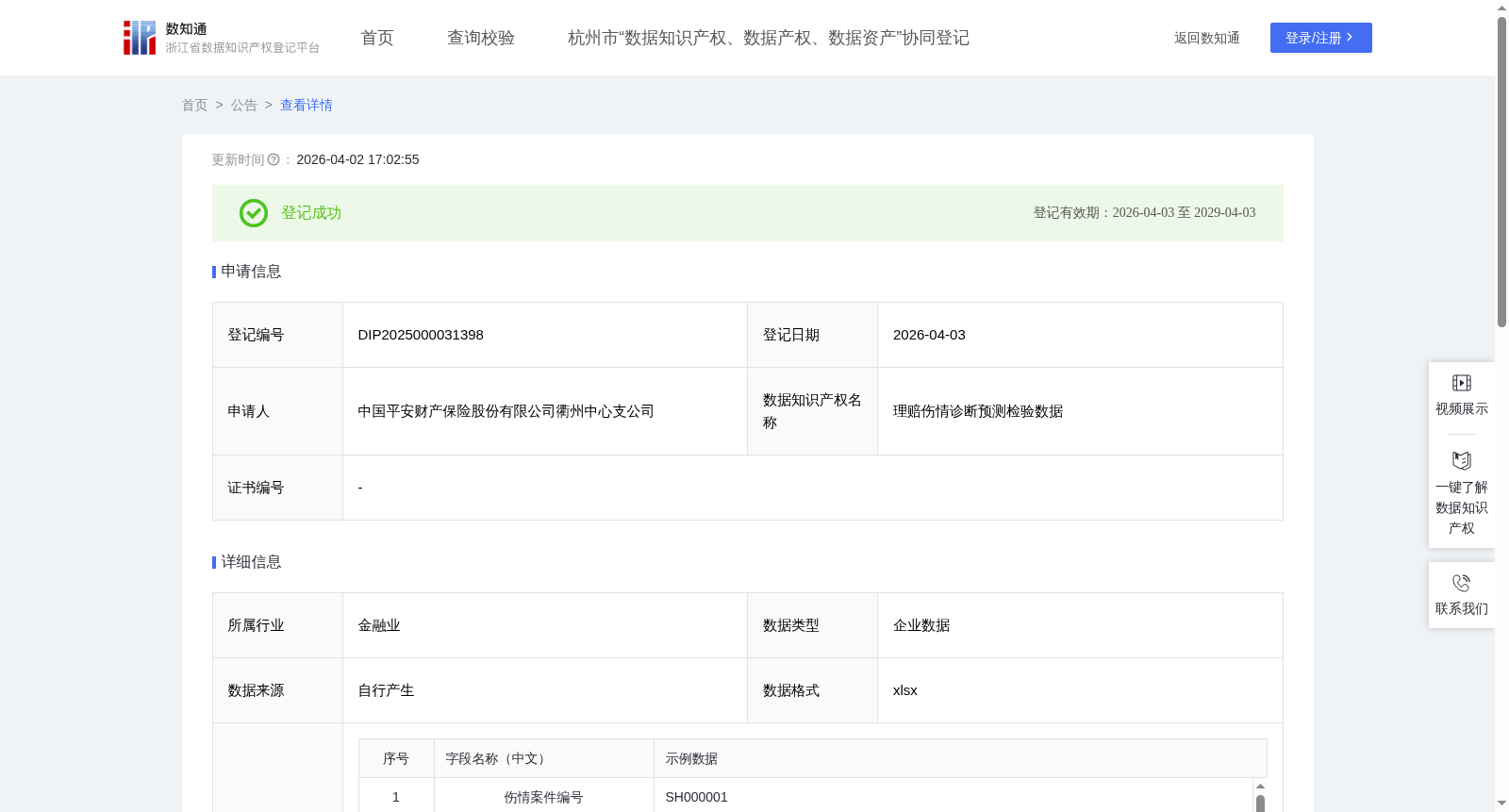
理赔伤情诊断预测检验数据
收藏浙江省数据知识产权登记平台2026-04-02 更新2026-04-03 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8436847
下载链接
链接失效反馈官方服务:
资源简介:
通过手术名称及伤残系数,获取该术式的 “加权伤残系数 + 置信度权重”,建立伤残系数预测模型,在人伤理赔中使用伤残系数预测模型,了解每一个手术名称下对应预测出的合理伤残系数区间,应用于理赔场景中,降低因人工判断导致的伤残预判偏差,鉴定人员判定伤残系数后,通过模型查询同术式的统计值以及预估值,校验伤残预估结果是否偏离合理区间,当前伤残系数是否需要人工核验;结合伤残系数高低合理制定保费,降低人工判断伤残系数带来的风险。此外,该预测数据还能为相关保险理赔企业提供伤情诊断预测信息,支持其在人伤理赔场景上针对伤情鉴定做出更合理的判断。一、数据来源:伤残系数是理赔部门在人伤场景下,出现伤情定性难的问题,为便于伤情定性,将手术名称(伤情的恢复手术名称,如颅内减压术)可量化界定的系数,一般情况下,手术越严重,伤残系数越高;伤残系数从0-100可以客观表明伤情的严重程度从轻微到严重,伤残系数由理赔部门在人伤场景下,参考过往相同或类似手术场景的伤残系数,结合实际理赔场景,人工判定产生一个0-100的伤残系数,并通过内部系统存储至企业数据库;二、数据采集:通过本企业合法自有数据库平台采集最新量数据;三、建立理赔伤残系数预测模型,基于采集数据进行数据处理:内部处理:1. 处理缺失值:对缺失的手术名称、伤残系数字段进行填充;2. 移除重复行:确保数据不重复;3. 标准化处理:对伤残系数数值型特征进行标准化处理。二、数据加工:1. 按surgical_name(手术名称)分组,计算每组的伤残系数统计特征;2. 统计特征包括:每一组手术名称的对应的伤残系数的平均值、中位数、标准差、最小值、最大值和样本数,其中平均值由手术名称聚合后的伤残系数总和/样本数(count)获取;3. 计算置信度权重:样本数越多,权重越高,具体公式为:conf_weight = 1 - (1 / (1 + sample_count));4.预测伤残系数区间:若置信度权重>0.8则表明该手术名称的样本多,该手术名称计算所的伤残系数均值较为准确,则该手术名称的预测伤残系数为平均值特征(取平均值上下浮动25%区间),若0.6<置信度权重<0.8,则该手术名称的预测伤残系数为该术下伤残系数中位数特征(取中位数上下浮动25%区间);若置信度权重<0.6,则说明该手术名称现存伤残系数的样本数量少,需要人工介入,以确保伤残系数准确性;5.判断伤残系数合理性:如果已判定伤残系数在预测伤残系数区间内则为合理伤残系数,如果在预测区间外则需经人工核验,如果置信度权重<0.6则直接判断为需经人工核验。
提供机构:
中国平安财产保险股份有限公司衢州中心支公司
创建时间:
2025-11-11
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个用于保险理赔伤情诊断预测的检验数据,包含2257条记录,每年更新,涉及手术名称、伤残系数统计特征和预测区间等字段。它通过建立伤残系数预测模型,帮助校验人工判断的伤残系数是否偏离合理区间,旨在降低理赔过程中因人工判断导致的偏差和风险,提升伤情鉴定的准确性和效率。
以上内容由遇见数据集搜集并总结生成


