AVED-Bench
收藏arXiv2025-03-27 更新2025-03-28 收录
下载链接:
https://genjib.github.io/project_page/AVED/index.html
下载链接
链接失效反馈官方服务:
资源简介:
AVED-Bench数据集是由北卡罗来纳大学教堂山分校和微软共同创建的,专门为零样本音视频编辑任务而设计。该数据集包含110个各具特色的10秒视频,涵盖了11个类别,每个视频都配有人工注释的源提示和目标提示。它提供了丰富的自然音视频事件,旨在评估零样本音视频编辑任务的性能。
AVED-Bench dataset was co-created by the University of North Carolina at Chapel Hill and Microsoft, specifically designed for zero-shot audio-visual editing tasks. The dataset contains 110 distinct 10-second videos across 11 categories, with each video paired with manually annotated source prompts and target prompts. It provides a rich corpus of natural audio-visual events, aiming to evaluate the performance of zero-shot audio-visual editing tasks.
提供机构:
北卡罗来纳大学教堂山分校, 微软
创建时间:
2025-03-27
搜集汇总
数据集介绍
构建方式
AVED-Bench数据集的构建基于VGGSound数据集,精心挑选了110段10秒时长的视频,覆盖11个不同的类别。这些视频被人工标注了源提示和目标提示,以确保音频和视觉元素之间的精确对齐。构建过程中特别关注了多样性和挑战性,涵盖了动物、人类行为和环境声音等多种场景,为音频-视频编辑任务提供了全面的评估基准。
使用方法
AVED-Bench数据集的使用方法主要包括加载视频和对应的提示信息,然后通过音频-视频编辑模型进行处理。用户可以根据目标提示对原始视频进行编辑,并通过数据集提供的评估指标(如CLIP-F、CLIP-T、DINO等)来评估编辑效果。数据集还支持跨模态对比损失的应用,以进一步提升编辑的同步性和一致性。
背景与挑战
背景概述
AVED-Bench是由微软研究院和北卡罗来纳大学教堂山分校的研究团队于2025年提出的一个专门用于零样本音视频编辑任务的基准数据集。该数据集包含来自VGGSound的110段10秒视频,涵盖11个不同类别,每段视频均配有精确标注的文本提示。该数据集的建立旨在解决现有单模态编辑方法在跨模态同步和一致性方面的不足,为音视频联合编辑研究提供了重要的评估基准。其创新性在于首次系统性地定义了零样本音视频编辑任务,并通过精心设计的标注体系推动了多模态生成模型的发展。
当前挑战
AVED-Bench面临的核心挑战体现在两个方面:在领域问题层面,需解决音视频跨模态编辑中的时序同步难题,包括声画对齐、动作-声音匹配等复杂场景;在构建过程层面,数据收集需确保音视频对的高质量匹配,标注工作需要处理跨模态语义对齐的复杂性。具体挑战包括:1)保持编辑后音频与视频的时序一致性;2)处理不同模态间的特征表示差异;3)构建具有多样性的编辑提示对;4)确保跨模态评估指标的可靠性。这些挑战使得该数据集成为测试音视频联合编辑方法鲁棒性的严格基准。
常用场景
经典使用场景
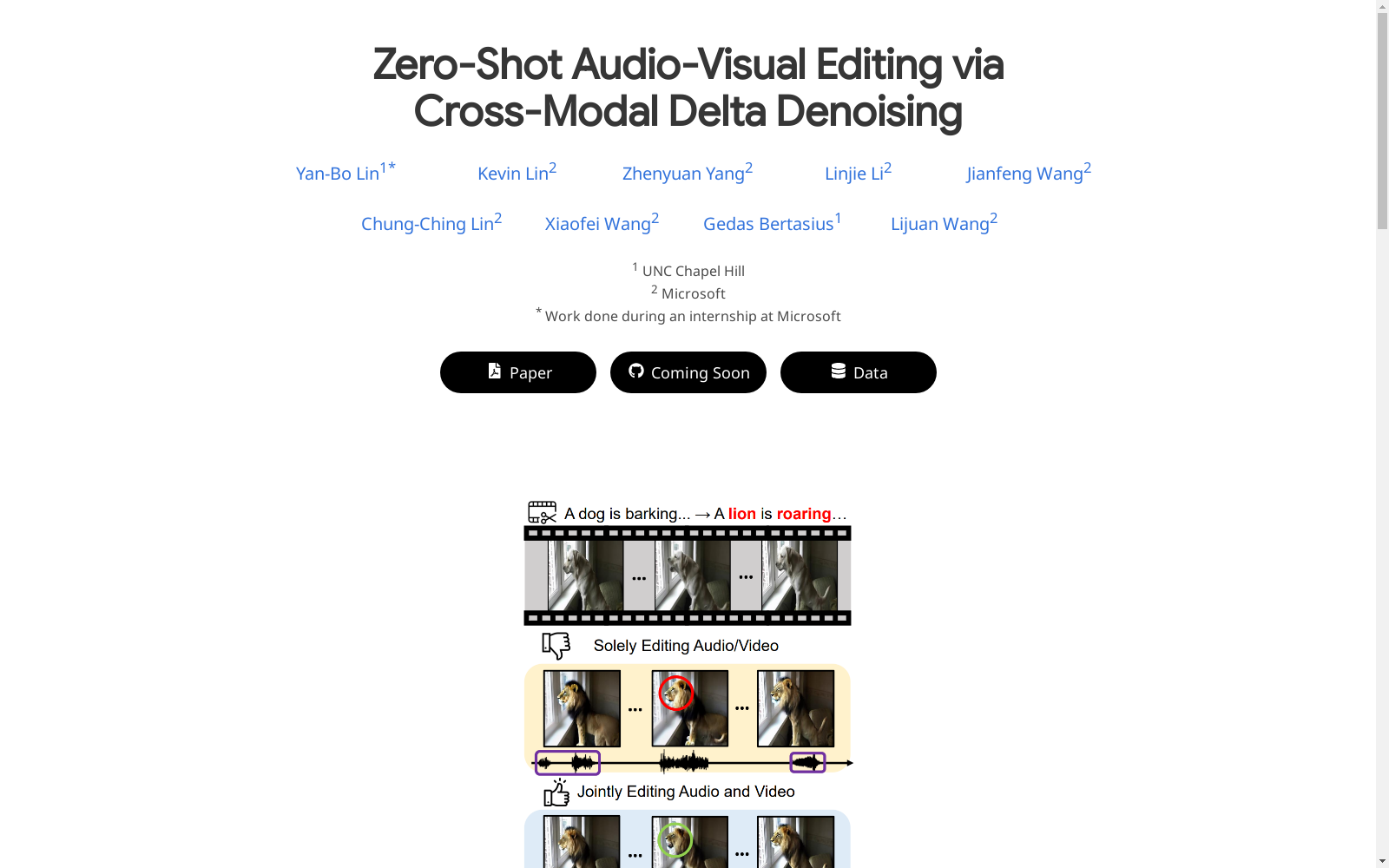
在多媒体内容生成与编辑领域,AVED-Bench数据集为研究者提供了一个标准化的测试平台,用于评估零样本音频-视频联合编辑算法的性能。该数据集包含来自VGGSound的110段10秒视频,覆盖11个不同类别,每段视频均配有精确标注的源提示与目标提示文本。研究者可利用该数据集验证算法在跨模态同步编辑任务中的表现,例如将视频中的狗吠声与视觉内容同步替换为狮吼场景,从而检验模型在保持音画时序一致性与语义连贯性方面的能力。
解决学术问题
AVED-Bench有效解决了多模态生成模型中长期存在的跨模态对齐难题。传统方法往往独立处理音频或视频编辑,导致音画不同步(如视觉已切换为狮子但音频仍保留狗吠声)。该数据集通过提供严格标注的跨模态样本,使研究者能够量化评估编辑后内容的同步指标(如AV-Align)和语义一致性(如CLIP-T)。其提出的Delta去噪分数框架首次实现了无需额外训练的跨模态联合编辑,为扩散模型在多媒体领域的可控生成提供了新范式。
实际应用
在影视后期制作与数字内容创作中,AVED-Bench支持的技术可大幅降低专业级音画编辑门槛。制作人仅需输入文本指令(如'将烟花爆炸替换为海浪拍打'),系统即可自动生成同步修改的视听内容,避免传统流程中音画分层处理的繁琐操作。该数据集验证的方法已应用于广告快速定制、无障碍内容生成等场景,其跨模态编辑能力特别适合需要保持口型同步的配音替换或特效场景音画联动等专业需求。
数据集最近研究
最新研究方向
近年来,随着多模态生成模型的快速发展,音频-视频联合编辑任务逐渐成为研究热点。AVED-Bench作为首个专注于零样本音频-视频编辑的基准数据集,为这一新兴领域提供了重要的评估平台。该数据集包含11个类别的110段10秒视频片段,涵盖动物、环境音效等多样化场景,并配备人工标注的源提示和目标提示,为研究跨模态同步编辑提供了丰富素材。当前研究主要聚焦于解决音频与视觉内容在编辑过程中的同步性和一致性挑战,例如通过提出的跨模态Delta去噪框架(AVED)来实现无需额外训练的联合编辑。这一方向的发展不仅为影视后期制作、数字艺术创作等应用场景提供了高效工具,也推动了扩散模型在多模态内容生成领域的边界拓展。
相关研究论文
- 1Zero-Shot Audio-Visual Editing via Cross-Modal Delta Denoising北卡罗来纳大学教堂山分校, 微软 · 2025年
以上内容由遇见数据集搜集并总结生成


