aozorabunko-chunked
收藏Hugging Face2025-06-13 更新2025-06-14 收录
下载链接:
https://huggingface.co/datasets/if001/aozorabunko-chunked
下载链接
链接失效反馈官方服务:
资源简介:
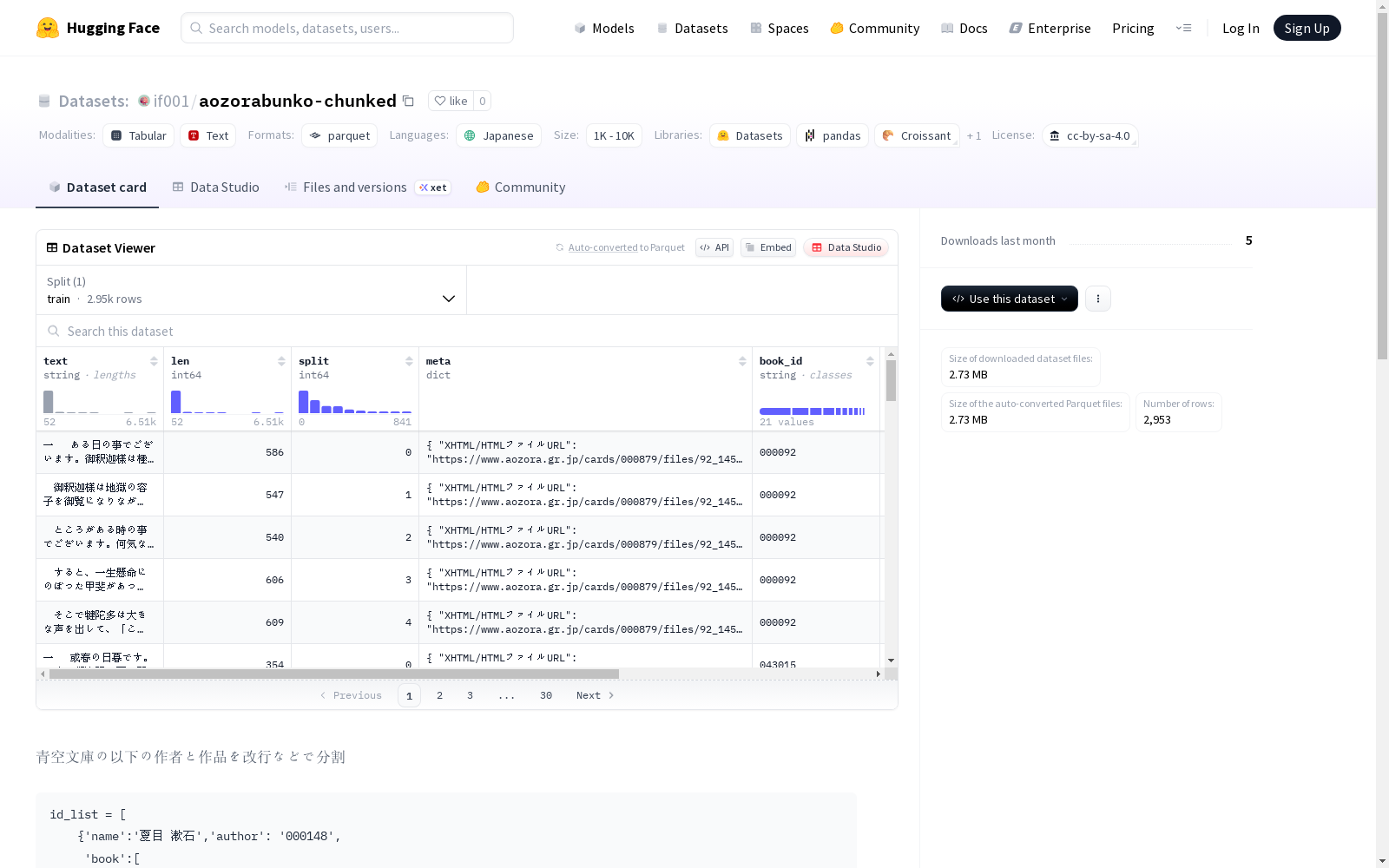
这是一个包含日语文本的数据集,主要字段包括文本内容、文本长度、数据集分割信息以及丰富的元数据信息,如文件的URL、更新日期、编码方式、作者和作品的详细信息等。数据集分为训练集,并提供了配置文件。数据集涵盖了多位知名作者及其作品,如夏目漱石、芥川龙之介等。
创建时间:
2025-06-13
搜集汇总
数据集介绍
构建方式
该数据集源自日本青空文库的精选文学作品,通过系统化处理流程构建而成。原始文本经过格式转换与清洗,保留完整的XHTML及文本文件元数据,包括作品版本信息、作者生平数据及版权标识。文本内容按预定义规则进行语义段落分割,形成结构化的数据块,每个数据块均附带多层次元数据标注,确保数据来源可追溯且格式统一。
特点
数据集涵盖夏目漱石、芥川龙之介等日本近代文学巨匠的代表作,包含文本内容、长度标记及训练分割标识。其核心特征在于丰富的元数据体系,覆盖作品版本、作者信息、出版历史及字符编码等46个结构化字段,为文学计算研究提供多维分析基础。文本采用标准日语书写,兼具文学价值与语言规范性,适用于自然语言处理与数字人文研究。
使用方法
研究者可通过加载数据集直接获取文本块及对应元数据,支持基于作者、作品或时间维度的数据筛选。文本字段适用于语言模型训练、风格分析及生成任务,元数据可用于作者 attribution 研究或文献计量分析。数据集采用CC-BY-SA-4.0许可,允许学术与商业用途的二次开发,但需遵循署名及相同方式共享条款。
背景与挑战
背景概述
青空文庫分块数据集源于日本著名的数字图书馆青空文库,该文库致力于收录版权过期的日本文学作品并将其数字化。此特定数据集由研究团队精心构建,聚焦于夏目漱石、芥川龙之介等七位代表性作家的经典作品,旨在为自然语言处理领域提供高质量的日语文本资源。其核心研究问题在于解决日语古典文学文本的机器可读性与结构化处理,为语言模型训练、文本生成及文学计算研究奠定数据基础,对推动日语自然语言处理技术的发展具有重要学术价值。
当前挑战
该数据集主要应对日语古典文学文本标准化处理的挑战,包括历史假名遣与现代假名遣的转换、旧汉字表记的规范化以及文学修辞特性的机器识别难题。在构建过程中面临多重技术障碍:需要精确处理原始文本的分块与标注,确保不同版本底本的元数据一致性,同时解决数字化过程中字符编码多样性和文本结构异质性问题。这些挑战要求开发专门的文本清洗管道和元数据整合框架,以保持文学作品的原始风貌与机器可读性之间的平衡。
常用场景
经典使用场景
在自然语言处理领域,aozorabunko-chunked数据集作为日本近现代文学经典文本的标准化语料库,主要应用于语言模型的预训练与微调。其文本经过规范化的分块处理,既保留了完整的文学语境,又符合机器学习模型对输入长度的要求,为研究者提供了高质量的日语语言资源。
实际应用
在实际应用层面,该数据集支撑了日语智能写作辅助系统、文学风格仿写工具和自动摘要生成器的开发。教育机构利用其构建日语语法教学系统,数字人文领域则基于该数据集进行作家风格量化分析和文学流派特征挖掘,为文化传承与创新提供数据支撑。
衍生相关工作
基于该数据集衍生的经典工作包括日语BERT预训练模型、文学文本风格迁移系统和作家身份识别算法。这些研究不仅推动了日语计算语言学的发展,还催生了跨语言的文学计算研究范式,为东亚语言处理领域树立了重要的基准参照体系。
以上内容由遇见数据集搜集并总结生成


