tytodd/sim-50k
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/tytodd/sim-50k
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: go_emotions
features:
- name: text
dtype: string
- name: row_id
dtype: string
- name: ground_truth
struct:
- name: labels
list: int64
splits:
- name: train
num_bytes: 2540496
num_examples: 22500
- name: val
num_bytes: 276436
num_examples: 2500
download_size: 1698773
dataset_size: 2816932
- config_name: or_bench_80k
features:
- name: prompt
dtype: string
- name: row_id
dtype: string
- name: ground_truth
struct:
- name: or_bench_category
dtype: string
splits:
- name: train
num_bytes: 3771579
num_examples: 22500
- name: val
num_bytes: 420064
num_examples: 2500
download_size: 2077836
dataset_size: 4191643
configs:
- config_name: go_emotions
data_files:
- split: train
path: go_emotions/train-*
- split: val
path: go_emotions/val-*
- config_name: or_bench_80k
data_files:
- split: train
path: or_bench_80k/train-*
- split: val
path: or_bench_80k/val-*
---
提供机构:
tytodd
搜集汇总
数据集介绍
构建方式
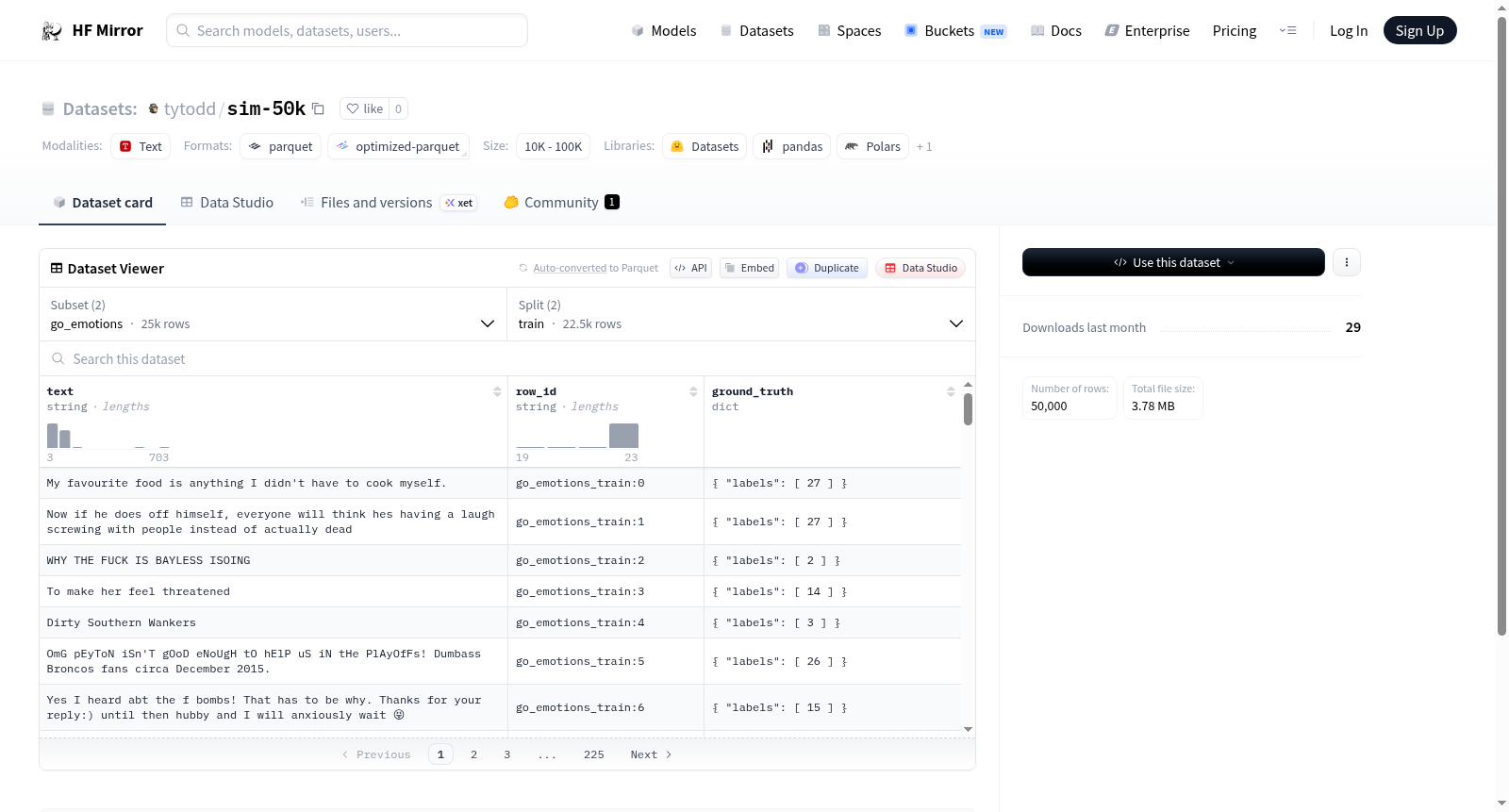
sim-50k数据集通过汇聚go_emotions与or_bench_80k两大子集构建而成,以多任务学习为导向整合情感识别与开放式基准评估能力。go_emotions子集包含2.5万条训练样本及2500条验证样本,每条样本由文本内容、行号及情感标签构成;or_bench_80k子集同样配备2.5万训练样本与2500验证样本,每条样本包含提示文本、行号及基准类别字段。数据以分片形式存储于HuggingFace仓库,通过config配置实现子集灵活加载。
特点
该数据集的核心优势在于其双任务融合特性,go_emotions提供多标签情感分类能力,覆盖28种细粒度情感维度;or_bench_80k则专注于开放式问答的基准评估,支持对模型生成质量的系统性评判。双子集独立配置设计使研究者能根据需求选择单任务或联合训练,2.5万级样本量在保证数据多样性的同时避免过拟合风险,验证分割的标准化设计便于模型性能的可靠评估。
使用方法
研究者可通过HuggingFace datasets库轻松调用sim-50k,通过指定config_name参数('go_emotions'或'or_bench_80k')加载对应子集,并利用split参数切换训练集与验证集。训练时可针对情感识别任务采用多标签分类损失函数,或结合or_bench_80k的类别标注进行生成质量优化。数据已预设行号字段便于追踪与过滤,可直接接入PyTorch或TensorFlow的DataLoader进行批处理训练。
背景与挑战
背景概述
sim-50k数据集诞生于情感计算与自然语言处理交叉领域的前沿探索中,由相关研究机构于近年来构建,旨在解决细粒度情感识别与多标签分类的核心问题。该数据集整合了go_emotions与or_bench_80k两大子集,分别涵盖人类情感标签及开放式指令分类,为模型在复杂语义环境下的情感理解与任务泛化能力提供了标准化评测基准。其发布丰富了多标签情感数据资源,推动了情感人工智能在对话系统、用户意图分析等应用场景的学术研究与技术落地,显著提升了领域内对细微情感差异的建模水平。
当前挑战
领域层面,sim-50k应对的是传统情感数据集仅覆盖粗粒度类别(如正负向)的局限性,需解决情感标签高度重叠、语义边界模糊及多标签关联性建模的挑战,这对模型的特征提取与层次化分类能力提出严苛要求。构建过程中,数据标注面临主观性差异与标签稀疏性问题,需平衡标注一致性、类别平衡性与样本代表性;同时,源自不同来源的子集需在格式与粒度上对齐,增加了跨域融合与噪声处理的复杂程度,对数据集的质量控制与可复现性构成了系统性考验。
常用场景
经典使用场景
在情感计算与自然语言处理的交汇领域,sim-50k数据集以其精妙的双配置设计脱颖而出。该数据集整合了go_emotions与or_bench_80k两大子集,前者聚焦于多标签情感识别任务,涵盖2.25万条训练样本与0.25万条验证样本,适用于细粒度情感分析模型的训练与评估;后者则围绕开放性指令理解与基准分类展开,同样包含2.25万条训练样本与0.25万条验证样本,专为探究大语言模型在多样化指令下的响应质量而构建。经典使用场景包括利用go_emotions子集进行情绪标签的联合预测,以及通过or_bench_80k子集评估生成式模型的指令遵循能力,从而为跨任务学习与多模态情感理解的研究提供坚实的实验基础。
解决学术问题
该数据集精准回应了学术领域中的两大核心难题:其一是多标签情感分类中标签稀疏性与类别不平衡问题,go_emotions子集通过丰富的标签层次,为训练能够捕捉微妙情绪差异的模型提供了高质量范例;其二是开放式指令基准测试中缺乏标准化评估体系的困境,or_bench_80k子集通过明确的分类维度,为衡量模型在自由形式生成任务中的可靠性开创了可量化的研究路径。其意义在于,它推动了情感智能从粗粒度向细粒度的演进,同时助力了指令理解这一前沿方向的方法论创新,深刻影响了人机交互中系统对复杂语义的解读能力。
衍生相关工作
基于sim-50k数据集,学术界涌现出一系列影响深远的衍生工作。许多研究以其go_emotions子集为基石,探索了图神经网络在情感标签结构化编码中的应用,提出了如情感层级感知的分类器设计;而以or_bench_80k为蓝本的工作则催生了指令微调策略的革新,其中强化学习与提示工程相结合的方法,显著提升了模型在零样本场景下的泛化能力。这些衍生经典不仅加深了对情感语义与指令逻辑内在关联的理解,也为未来构建更智能、更具同理心的人机对话系统指明了方向。
以上内容由遇见数据集搜集并总结生成


