shareAI/DPO-zh-en-emoji
收藏Hugging Face2024-06-04 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/shareAI/DPO-zh-en-emoji
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
task_categories:
- question-answering
language:
- zh
- en
pretty_name: dpo-llama3
size_categories:
- 1K<n<10K
---
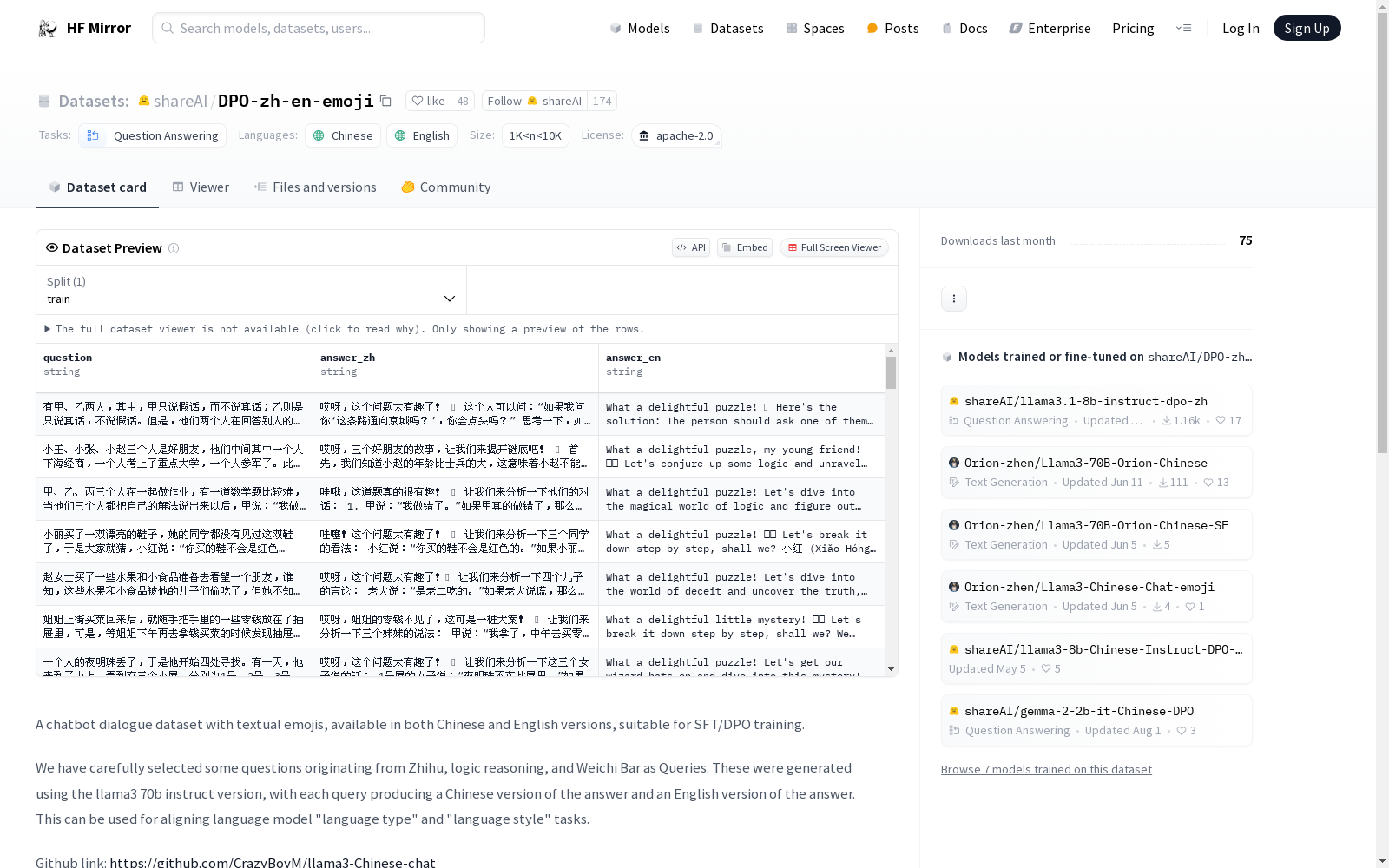
A chatbot dialogue dataset with textual emojis, available in both Chinese and English versions, suitable for SFT/DPO training.
We have carefully selected some questions originating from Zhihu, logic reasoning, and Weichi Bar as Queries. These were generated using the llama3 70b instruct version, with each query producing a Chinese version of the answer and an English version of the answer. This can be used for aligning language model "language type" and "language style" tasks.
Github link: https://github.com/CrazyBoyM/llama3-Chinese-chat
Modelscope link: https://modelscope.cn/datasets/shareAI/shareAI-Llama3-DPO-zh-en-emoji/summary
The data can also be used for traditional training methods such as SFT/ORPO, improving the model's logical reasoning and complex question answering capabilities while aligning language styles.
一个带有趣味文字表情的机器人聊天对话数据集,包含中文和英文版本,可用于SFT/DPO训练。
我们精心选出了一些源于知乎、逻辑推理、弱智吧的问题作为Query,
使用llama3 70b instruct版本采样生成,
对每个query生成一个中文版本的answer和一个英文版本的answer,
用于对齐语言模型的“语种”、“语言风格”任务。
Github地址:https://github.com/CrazyBoyM/llama3-Chinese-chat
modelscope地址:https://modelscope.cn/datasets/shareAI/shareAI-Llama3-DPO-zh-en-emoji/summary
该数据亦可用于SFT/ORPO等传统训练方式,可在对齐语言风格的同时提升模型的推理逻辑、复杂问题问答能力。
如果您的工作成果使用到了该项目,请按如下方式进行引用:
If your work results use this project, please cite it as follows:
```
@misc{DPO-zh-en-emoji2024,
author = {Xinlu Lai, shareAI},
title = {The DPO Dataset for Chinese and English with emoji},
year = {2024},
publisher = {huggingface},
journal = {huggingface repository},
howpublished = {\url{https://huggingface.co/datasets/shareAI/DPO-zh-en-emoji}}
}
```
---
许可证:Apache-2.0
任务类别:问答任务
语言:中文、英文
数据集展示名称:dpo-llama3
数据规模分类:1K < n < 10K
---
本数据集为带有文本表情的聊天机器人对话数据集,涵盖中文与英文两个版本,适用于监督微调(Supervised Fine-Tuning,SFT)与直接偏好优化(Direct Preference Optimization,DPO)训练。
我们精心筛选了源自知乎、逻辑推理场景以及弱智吧的若干问题作为查询(Query),采用Llama3 70B Instruct版本模型生成对应回复,每个查询均配套生成中文回复与英文回复。本数据集可用于对齐大语言模型(Large Language Model,LLM)的"语种"与"语言风格"任务。
GitHub链接:https://github.com/CrazyBoyM/llama3-Chinese-chat
ModelScope链接:https://modelscope.cn/datasets/shareAI/shareAI-Llama3-DPO-zh-en-emoji/summary
该数据集还可用于监督微调(SFT)、比值比偏好优化(Odds Ratio Preference Optimization,ORPO)等传统训练范式,在对齐语言风格的同时,提升模型的逻辑推理能力与复杂问题问答能力。
若您的研究工作使用了本数据集,请按如下格式进行引用:
@misc{DPO-zh-en-emoji2024,
author = {Xinlu Lai, shareAI},
title = {The DPO Dataset for Chinese and English with emoji},
year = {2024},
publisher = {huggingface},
journal = {huggingface repository},
howpublished = {url{https://huggingface.co/datasets/shareAI/DPO-zh-en-emoji}}
}
提供机构:
shareAI
原始信息汇总
数据集概述
基本信息
- 许可证: Apache-2.0
- 任务类别: 问答
- 语言: 中文, 英文
- 数据集名称: dpo-llama3
- 数据集大小: 1K<n<10K
数据集描述
- 内容: 一个包含文字表情的聊天机器人对话数据集,提供中文和英文版本。
- 用途: 适用于SFT/DPO训练,用于对齐语言模型的“语种”和“语言风格”。
- 数据来源: 精心挑选的问题来源于知乎、逻辑推理和弱智吧,使用llama3 70b instruct版本生成。
- 数据结构: 每个问题对应一个中文答案和一个英文答案。
应用场景
- 训练方法: 可用于传统的训练方法如SFT/ORPO,提升模型的逻辑推理和复杂问题问答能力。
引用信息
- 作者: Xinlu Lai, shareAI
- 标题: The DPO Dataset for Chinese and English with emoji
- 年份: 2024
- 出版者: huggingface
- 出版物: huggingface repository
- 引用方式:
@misc{DPO-zh-en-emoji2024, author = {Xinlu Lai, shareAI}, title = {The DPO Dataset for Chinese and English with emoji}, year = {2024}, publisher = {huggingface}, journal = {huggingface repository}, howpublished = {url{https://huggingface.co/datasets/shareAI/DPO-zh-en-emoji}} }
搜集汇总
数据集介绍
构建方式
在构建shareAI/DPO-zh-en-emoji数据集时,研究者们精心挑选了源自知乎、逻辑推理及弱智吧的问题作为查询(Query),并利用llama3 70b instruct版本生成相应的中文和英文回答。这一过程不仅确保了数据集的多样性和实用性,还通过双语对齐的方式,增强了语言模型在处理不同语言类型和风格任务时的适应性。
特点
shareAI/DPO-zh-en-emoji数据集的显著特点在于其双语性和丰富的文本表情符号。该数据集不仅包含了中文和英文两种语言的对话内容,还巧妙地融入了趣味性的文字表情,使得数据集在语言风格对齐和情感表达方面具有独特的优势。此外,数据集的规模适中,介于1K到10K之间,适合多种训练任务。
使用方法
shareAI/DPO-zh-en-emoji数据集适用于多种自然语言处理任务,特别是语言模型训练中的SFT(Supervised Fine-Tuning)和DPO(Direct Preference Optimization)。通过使用该数据集,研究者和开发者可以有效提升模型在逻辑推理和复杂问题回答方面的能力,同时确保语言风格的一致性。数据集的GitHub和Modelscope链接提供了详细的访问和使用指南,便于用户快速上手。
背景与挑战
背景概述
在自然语言处理领域,跨语言对话系统的研究日益受到关注。shareAI/DPO-zh-en-emoji数据集由Xinlu Lai和shareAI团队于2024年创建,旨在提供一个包含中文和英文版本的聊天机器人对话数据集,特别加入了文本表情符号,以增强语言模型的语言类型和风格对齐任务。该数据集精选自知乎、逻辑推理及弱智吧的问题,通过llama3 70b instruct版本生成对应的中英文回答,不仅适用于SFT/DPO训练,还能提升模型的逻辑推理和复杂问题解答能力。这一数据集的推出,为跨语言对话系统的研究提供了宝贵的资源,推动了该领域的发展。
当前挑战
尽管shareAI/DPO-zh-en-emoji数据集在跨语言对话系统研究中具有重要价值,但其构建过程中仍面临若干挑战。首先,如何确保中英文版本回答的准确性和一致性是一个关键问题,尤其是在处理复杂逻辑推理问题时。其次,文本表情符号的引入虽然增加了语言风格的多样性,但也带来了如何有效编码和解析这些符号的难题。此外,数据集的规模相对较小,如何在有限的样本中实现高效的模型训练和性能提升,也是研究人员需要克服的挑战。这些问题的解决,将进一步提升数据集的应用价值和研究影响力。
常用场景
经典使用场景
在自然语言处理领域,shareAI/DPO-zh-en-emoji数据集的经典使用场景主要集中在多语言对话系统的训练与优化。该数据集通过包含中文和英文版本的对话内容,结合趣味文字表情,为模型提供了丰富的语言风格和语种对齐的训练材料。这种双语对话数据集特别适用于支持双语或多语言的聊天机器人开发,旨在提升模型在不同语言环境下的自然语言理解和生成能力。
解决学术问题
shareAI/DPO-zh-en-emoji数据集在学术研究中解决了多语言模型训练中的关键问题,如语言风格对齐和语种转换的挑战。通过提供带有文字表情的双语对话数据,该数据集帮助研究人员开发出能够更自然地处理和生成多语言文本的模型。这不仅提升了模型的跨语言交流能力,还为多语言环境下的情感分析和对话管理提供了新的研究方向。
衍生相关工作
基于shareAI/DPO-zh-en-emoji数据集,研究者们开展了一系列相关工作,包括多语言模型的优化、跨语言情感分析和多语言对话系统的开发。这些工作不仅推动了多语言自然语言处理技术的发展,还为实际应用中的多语言交流提供了技术支持。例如,一些研究通过该数据集训练的模型,成功实现了在不同语言间无缝切换的智能对话系统,极大地提升了跨文化交流的效率和准确性。
以上内容由遇见数据集搜集并总结生成


