robinson_schensted_knuth_correspondence_10
收藏Hugging Face2025-08-09 更新2025-08-10 收录
下载链接:
https://huggingface.co/datasets/ACDRepo/robinson_schensted_knuth_correspondence_10
下载链接
链接失效反馈官方服务:
资源简介:
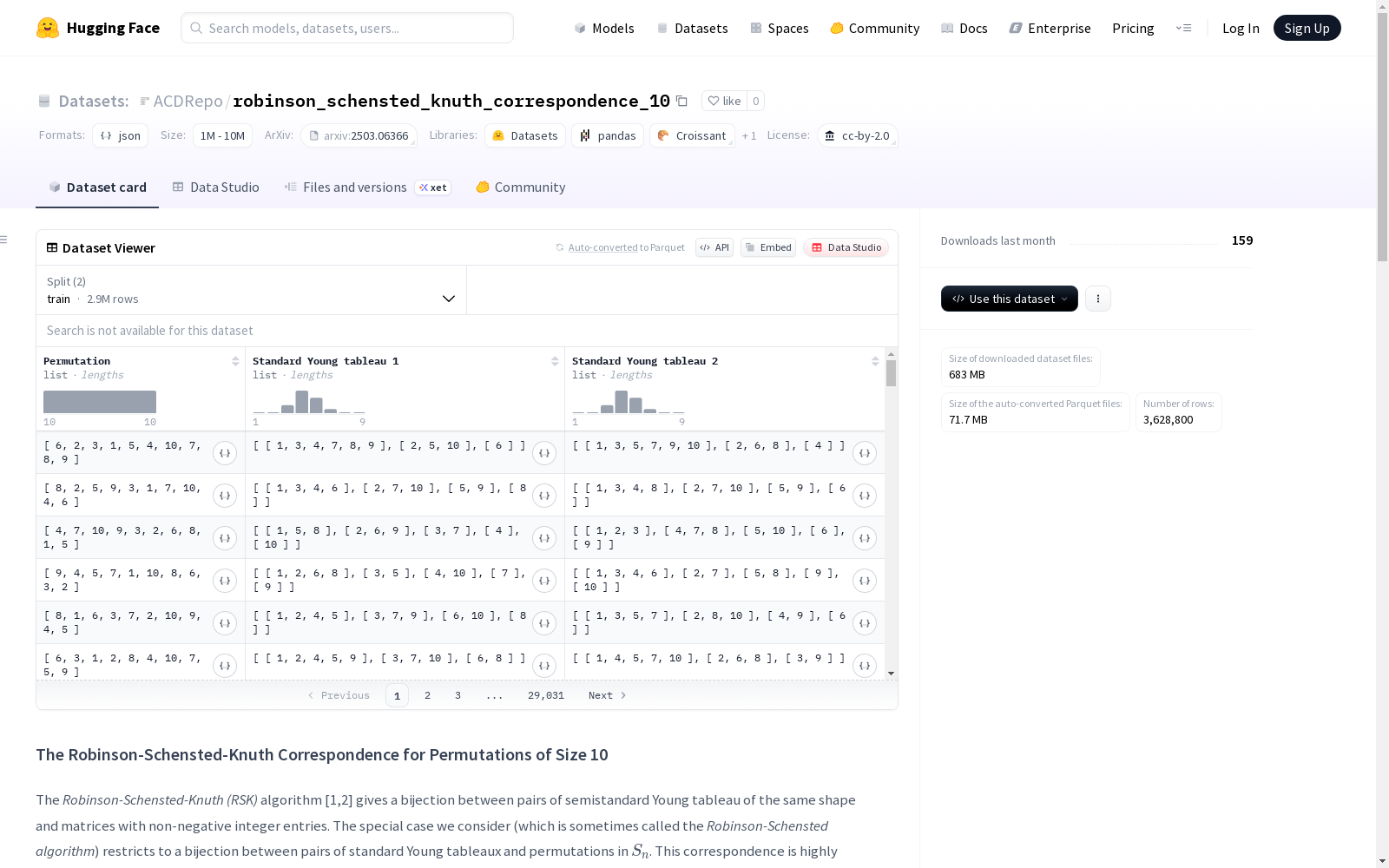
该数据集包含大小为10的排列的Robinson-Schensted-Knuth (RSK)对应关系。RSK算法是一种将标准Young表与排列之间建立双射关系的算法。数据集由一对标准Young表和相应的排列组成,排列以逆序集的形式表示。数据集的目的是训练模型学习RSK算法,从而预测给定的标准Young表对应的排列。
创建时间:
2025-08-01
搜集汇总
数据集介绍
构建方式
在代数组合学领域,Robinson-Schensted-Knuth对应关系作为连接置换与标准杨表的核心桥梁,本数据集通过Sage数学软件系统生成了所有规模为10的置换及其对应的标准杨表对。数据生成过程严格遵循RSK算法的逆向映射,将标准杨表对作为输入,通过计算得到对应的置换逆序集表示,确保了数据的数学严谨性与完整性。
特点
该数据集的显著特征在于采用置换的逆序集二进制编码作为输出表示,而非传统的一行记号法。这种表示方法通过\(\binom{n}{2}\)维二元向量精确刻画置换结构,其中每位对应特定位置对是否构成逆序。数据集涵盖所有规模为10的置换情形,为标准杨表与置换之间的双向映射提供了全面而精确的实例,为机器学习模型学习组合对应关系奠定了坚实基础。
使用方法
使用本数据集时,模型接收一对标准杨表作为输入,需预测对应的置换逆序集二进制向量。标准杨表以嵌套列表形式呈现,例如[[1,4,7],[2,6,8],[3],[5]]表示形状为(3,3,1,1)的杨表。输出层需配置\(\binom{10}{2}=45\)个节点,分别对应字典序排列的逆序对存在与否的二元分类任务,从而实现对RSK对应关系的机器学习建模。
背景与挑战
背景概述
Robinson-Schensted-Knuth对应关系作为代数组合学领域的核心算法,由Gilbert de Beauregard Robinson于1938年首次提出,后经Craige Schensted(1961年)和Donald Knuth的深化研究,建立了置换与标准杨表之间的双射关系。该算法不仅揭示了组合结构的深层对称性,更为最长递增子序列问题提供了优雅的解决方案。太平洋西北国家实验室的Helen Jenne团队于2025年构建的该数据集,旨在通过机器学习方法验证模型对这一经典组合映射的学习能力,推动计算数学与组合理论的交叉融合。
当前挑战
该数据集核心挑战在于让机器学习模型从标准杨表对重构原始置换,这要求模型隐式掌握RSK算法的组合逻辑及其与最长递增子序列的关联。构建过程中的技术难点包括:如何将杨表的组合结构转化为可计算的张量表示,以及将置换的逆序集编码为固定维度的二进制向量以适配神经网络输出层。此外,算法步骤随置换规模呈指数级增长,需平衡计算复杂度与模型泛化能力,这对机器学习方法的组合推理能力提出了极高要求。
常用场景
经典使用场景
在代数组合学研究中,该数据集被广泛应用于验证机器学习模型对Robinson-Schensted-Knuth对应关系的学习能力。研究者通过输入标准杨表对,要求模型预测对应的置换逆序集表示,从而测试模型对组合数学中双射关系的理解深度。这种设置不仅检验模型对精确组合结构的捕捉能力,更涉及最长递增子序列等经典问题的隐含学习。
实际应用
在实际应用中,该数据集为开发智能组合数学辅助系统提供了训练基础。此类系统可协助数学家快速验证组合猜想,特别是在对称群表示论和杨表计算领域。此外,在编码理论和密码学中,对置换结构的深度学习模型可能衍生出新的算法设计思路,为离散数学与计算机科学的交叉研究提供实践支撑。
衍生相关工作
该数据集催生了多项关于组合神经网络架构的创新研究,包括针对置换输出的特殊网络设计。基于此开展的后续工作扩展到了更广泛的代数组合对应关系学习,如晶体基理论与Schützenberger提升算法。这些研究不仅深化了机器学习与组合数学的融合,还促进了可解释AI在形式化数学推理中的应用发展。
以上内容由遇见数据集搜集并总结生成


