kwaikeg/KAgentBench
收藏Hugging Face2024-01-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/kwaikeg/KAgentBench
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-sa-4.0
language:
- zh
- en
size_categories:
- 1K<n<10K
task_categories:
- text-generation
---
KAgentBench is the benchmark proposed in KwaiAgents ([Github](https://github.com/KwaiKEG/KwaiAgents)), which is a series of Agent-related works open-sourced by the [KwaiKEG](https://github.com/KwaiKEG) from [Kuaishou Technology](https://www.kuaishou.com/en). It contains over 3,000 human-edited, automated evaluation data for testing Agent capabilities, with evaluation dimensions including planning, tool-use, reflection, concluding, and profiling.
## Overall statistics of KAgentBench
---
| type| #Queries | #Inst | Avg. #Ground | Avg. #Tools | Avg. #Turns | Avg. #Tasks | Avg. Len-Know | Metric |
| :-------: | :-------:| :-------: | :-------: | :-------: | :-------: | :-------: | :-------: | :-------: |
| Planning & Tool-use | 320 | 1,317 | 4.12 | 8.68 | 1.51 | 2.21 | 245.31 | ROUGE-L, EM |
| Reflection | 68 | 272 | 4 | 12 | 1 | 3.97 | 1369.04 | ROUGE-L, EM |
| Concluding | 245 | 1,225 | 5 | - | 1.52 | 2.14 | 923.96 | ROUGE-L |
| Profile | 433 | 433 | 5 | - | 1.99 | - | - | ROUGE-L |
## Experimental results of different LLMs on KAgentBench
---
The specific performance of different models on benchmarks can be seen in more detail in our [paper](https://arxiv.org/abs/2312.04889).
| | Scale | Planning | Tool-use | Reflection | Concluding | Profile | Overall Score |
|----------------|-------|----------|----------|------------|------------|---------|---------------|
| GPT-3.5-turbo | - | 18.55 | 15.89 | 5.32 | 37.26 | 35.42 | 21.72 |
| Llama2 | 13B | 0.15 | 0.23 | 0.08 | 16.60 | 17.73 | 5.22 |
| ChatGLM3 | 6B | 7.87 | 6.82 | 4.49 | 30.01 | 30.14 | 13.82 |
| Qwen | 7B | 13.34 | 10.87 | 4.73 | 36.24 | 34.99 | 18.36 |
| Baichuan2 | 13B | 6.70 | 10.11 | 4.25 | 24.97 | 19.08 | 12.54 |
| ToolLlama | 7B | 0.20 | 3.44 | 0.54 | 15.62 | 10.66 | 5.50 |
| AgentLM | 13B | 0.17 | 0.09 | 0.05 | 16.30 | 15.22 | 4.86 |
| Qwen-MAT | 7B | 31.64 | 28.26 | 29.50 | 44.85 | 44.78 | 34.20 |
| Baichuan2-MAT | 13B | 37.27 | 34.82 | 32.06 | 48.01 | 41.83 | 38.49 |
## JSON Format
---
Each data point is
a dict with the following keys:
- `id`: a unique id for this data point. This is useful for evaluation.
- `query`: a string.
- `type`: a string, the type of this data(plantooluse,reflextion,conclusion,profile).
- `golden_result_list`: a list. The reference response.
- `funcs`: a list of functions that may be used in the current query
- `prompt_input`: a dict,input composed of different prompt templates
- `memory`: a string
- `memory_type`: a string,types of memory: task, knowledge, conversation
- `memory_last_task`: a list, in the case where memory is task, the last task information in the previous round
The overall data format is as follows
```json
{
"id": "",
"query": "",
"type": "",
"golden_result_list": [],
"funcs": [],
"prompt_input": {},
"memory": "",
"memory_type": "",
"memory_last_task": {}
}
```
## How to download benchmark
---
You can download the benchmark evaluation set through [kwaikeg/KAgentBench](https://huggingface.co/datasets/kwaikeg/KAgentBench/tree/main), or you can also download the benchmark evaluation set on [KwaiAgents](https://github.com/KwaiKEG/KwaiAgents).
The filename of the evaluation set is 'benchmark_eval.jsonl'. Download the file to your local system.
## Environment Setup
---
Please make sure you have setup the environment and installed the required packages. Make sure you meet the above requirements, and then install the dependent libraries.
```bash
pip install -r requirements.txt
```
## Benchmark Inference
To run benchmark evaluations using different models, it is necessary to appropriately load and predict according to the model in the inference script. Different models may have variations in their initialization and loading methods. We have provided inference scripts for both the Qianwen and Baichuan models. Inference for other models can be adapted based on the scripts we have provided.
Taking the provided open-source model kagentlms_qwen_7b_mat as an example.(The kagentlms_qwen_7b_mat model has been uploaded to [huggingface](https://huggingface.co/kwaikeg/kagentlms_qwen_7b_mat))
Run the script to perform benchmark predictions. The parameter is the prediction results file.
```bash
python infer_qwen.py qwen_benchmark_res.jsonl
```
Similarly, to perform evaluations using the 'kagentlms_baichuan2_13b_mat' model, execute the following command.
```bash
python infer_baichuan.py baichuan_benchmark_res.jsonl
```
The prediction results will be stored in the 'model_predict' field, which is a dictionary (dict) structure. The key is the type of prompt, and the corresponding value is the output of the model. In the 'profile', as it contains only one prompt, 'model_predict' is a string, and the corresponding value is the model output.
Below is an example display of a prediction result for 'conclusion' data.
```json
{
"query": "在过去的一年中,哪个月份的全球气温最高?",
"id": "0ae75cf4-8897-5998-b74c-c7ae7202621c",
"type": "conclusion",
"memory_type": "task",
"memory": "...",
"funcs": [],
"memory_last_task": {},
"golden_result_list": [
{
"golden_result":"2022年中,6月是全球最高气温。"
},
{
"golden_result":"2022年中,全球最高气温是6月。"
},
{
"golden_result":"2022年中,全球最高气温是6月。"
},
{
"golden_result":"2022年中,6月是全球最高气温。。"
},
{
"golden_result":"2022年中,全球最高气温是6月。"
}
],
"prompt_input": {...},
"model_predict": {
"ReACT": "2022年7月的全球气温最高,达到了17.23℃。",
"AutoGPT": "在过去的一年中,全球气温最高的月份是2023年4月,全球表面平均气温达到了17.23°C,创下了历史新高。这一数据来自于美国国家海洋和大气管理局与美国缅因大学汇编的初步数据。",
"ModelScope": "在过去一年中,全球气温最高的月份是2023年7月。根据美国国家航空航天局(NASA)和美国国家海洋和大气管理局(NOAA)的最新研究报告,2022年是史上排名第6的最热年份,尽管拉尼娜现象改变了天气模式,抑制了全球气温。然而,2023年7月的全球平均气温达到了17.23℃,超过了7月4日和5日创下的17.18℃的联合纪录,而后者之前曾打破了7月3日创下的17.01℃的纪录。",
"ToolLlama": "Thought: I have found the information about the warmest month in 2022 in the memory. I will use this information to answer the question and call the Finish function to provide the final answer.\nAction: Finish\nAction Input: {\"return_type\": \"give_answer\", \"final_answer\": \"在2022年,全球最暖的月份是5月,比20世纪平均值高出1.39°F(0.77°C)。\"}",
"Kuaiagent": "在过去的一年中,全球气温最高的月份是2023年7月。根据美国国家航空航天局(NASA)和美国国家海洋和大气管理局(NOAA)的最新研究报告,2023年7月的全球平均气温达到了17.23℃,超过了19世纪50年代有仪器记录以来的任何一个月。"
}
}
```
'...' indicates that the content is too extensive. For the sake of convenient display format, the content has been abbreviated.
## Evaluation
Taking the inference results of the 'kagentlms_qwen_7b_mat' model as an example, calculate the metrics based on the benchmark inference results obtained from the 'infer'. Execute the following command to get the overall score.
The first parameter is the benchmark evaluation set, which contains reference responses manually annotated, and the second parameter is the prediction results of the model being evaluated.
```bash
python benchmark_eval.py ./benchmark_eval.jsonl ./qwen_benchmark_res.jsonl
```
The final model score is as follows:
```bash
plan : 31.64, tooluse : 28.26, reflextion : 29.50, conclusion : 44.85, profile : 44.78, overall : 34.20
```
许可证:CC BY-NC-SA 4.0
语言:
- 中文
- 英语
规模分类:
- 1K < n < 10K
任务类别:
- 文本生成
KAgentBench 是 KwaiAgents 提出的基准测试集([Github](https://github.com/KwaiKEG/KwaiAgents)),后者是快手科技(Kuaishou Technology)旗下的 KwaiKEG 开源的一系列 AI 智能体(AI Agent)相关研究工作。该基准测试集包含超过3000条人工编辑的自动化评测数据,用于评测AI智能体的多项能力,评测维度涵盖规划、工具使用、反思(Reflection)、总结、画像(Profile)。
## KAgentBench 整体统计数据
---
| 任务类型 | 查询数 | 实例数 | 平均基准回复数 | 平均工具调用数 | 平均交互轮次 | 平均任务数 | 平均知识长度 | 评测指标 |
| :-------: | :-------:| :-------: | :-------: | :-------: | :-------: | :-------: | :-------: | :-------: |
| 规划与工具使用 | 320 | 1,317 | 4.12 | 8.68 | 1.51 | 2.21 | 245.31 | ROUGE-L, EM |
| 反思(Reflection) | 68 | 272 | 4 | 12 | 1 | 3.97 | 1369.04 | ROUGE-L, EM |
| 总结 | 245 | 1,225 | 5 | - | 1.52 | 2.14 | 923.96 | ROUGE-L |
| 画像(Profile) | 433 | 433 | 5 | - | 1.99 | - | - | ROUGE-L |
## 不同大语言模型在 KAgentBench 上的实验结果
---
不同模型在该基准测试集上的具体性能细节可参阅我们的[论文](https://arxiv.org/abs/2312.04889)。
| | 参数量规模 | 规划得分 | 工具使用得分 | 反思得分 | 总结得分 | 画像得分 | 综合得分 |
|----------------|-------|----------|----------|------------|------------|---------|---------------|
| GPT-3.5-turbo | - | 18.55 | 15.89 | 5.32 | 37.26 | 35.42 | 21.72 |
| Llama2 | 13B | 0.15 | 0.23 | 0.08 | 16.60 | 17.73 | 5.22 |
| ChatGLM3 | 6B | 7.87 | 6.82 | 4.49 | 30.01 | 30.14 | 13.82 |
| Qwen | 7B | 13.34 | 10.87 | 4.73 | 36.24 | 34.99 | 18.36 |
| Baichuan2 | 13B | 6.70 | 10.11 | 4.25 | 24.97 | 19.08 | 12.54 |
| ToolLlama | 7B | 0.20 | 3.44 | 0.54 | 15.62 | 10.66 | 5.50 |
| AgentLM | 13B | 0.17 | 0.09 | 0.05 | 16.30 | 15.22 | 4.86 |
| Qwen-MAT | 7B | 31.64 | 28.26 | 29.50 | 44.85 | 44.78 | 34.20 |
| Baichuan2-MAT | 13B | 37.27 | 34.82 | 32.06 | 48.01 | 41.83 | 38.49 |
## JSON 数据格式
---
每条数据样本为一个字典,包含以下键值对:
- `id`: 该数据样本的唯一标识符,便于评测流程使用。
- `query`: 字符串类型,为用户查询内容。
- `type`: 字符串类型,代表该数据样本的任务类型,可选值为`plantooluse`、`reflection`、`conclusion`、`profile`。
- `golden_result_list`: 列表类型,存储参考响应集合。
- `funcs`: 列表类型,包含当前查询可能用到的函数。
- `prompt_input`: 字典类型,由不同提示模板组合而成的输入内容。
- `memory`: 字符串类型,为上下文记忆内容。
- `memory_type`: 字符串类型,代表记忆类型,可选值为`task`(任务记忆)、`knowledge`(知识记忆)、`conversation`(对话记忆)。
- `memory_last_task`: 列表类型,当记忆类型为任务记忆时,存储上一轮的任务信息。
整体数据格式示例如下:
json
{
"id": "",
"query": "",
"type": "",
"golden_result_list": [],
"funcs": [],
"prompt_input": {},
"memory": "",
"memory_type": "",
"memory_last_task": {}
}
## 基准测试集下载方式
---
你可以通过 [kwaikeg/KAgentBench](https://huggingface.co/datasets/kwaikeg/KAgentBench/tree/main) 下载该基准评测集,也可以在 [KwaiAgents](https://github.com/KwaiKEG/KwaiAgents) 仓库中获取。评测集文件名为`benchmark_eval.jsonl`,请将其下载至本地系统。
## 环境配置
---
请确保已完成环境配置并安装所需依赖包。在满足上述要求后,执行以下命令安装依赖库:
bash
pip install -r requirements.txt
## 基准测试推理
---
若需使用不同模型运行基准评测,需根据推理脚本中的模型类型进行适配加载与预测,不同模型的初始化及加载方式可能存在差异。我们已为通义千问(Qwen)与百川(Baichuan)模型提供了官方推理脚本,其余模型可基于提供的脚本进行适配调整。
以提供的开源模型`kagentlms_qwen_7b_mat`为例(该模型已上传至 [Hugging Face](https://huggingface.co/kwaikeg/kagentlms_qwen_7b_mat)),运行以下脚本执行基准预测,参数为预测结果保存文件路径:
bash
python infer_qwen.py qwen_benchmark_res.jsonl
同理,若需使用`kagentlms_baichuan2_13b_mat`模型,执行以下命令:
bash
python infer_baichuan.py baichuan_benchmark_res.jsonl
预测结果将存储在`model_predict`字段中,该字段为字典结构,键为提示模板类型,对应值为模型输出结果。在画像(Profile)任务中,由于仅包含一种提示模板,`model_predict`为字符串类型,其值即为模型输出。
以下为「总结」类型数据的预测结果示例:
json
{
"query": "在过去的一年中,哪个月份的全球气温最高?",
"id": "0ae75cf4-8897-5998-b74c-c7ae7202621c",
"type": "conclusion",
"memory_type": "task",
"memory": "...",
"funcs": [],
"memory_last_task": {},
"golden_result_list": [
{
"golden_result":"2022年中,6月是全球最高气温。"
},
{
"golden_result":"2022年中,全球最高气温是6月。"
},
{
"golden_result":"2022年中,全球最高气温是6月。"
},
{
"golden_result":"2022年中,6月是全球最高气温。。"
},
{
"golden_result":"2022年中,全球最高气温是6月。"
}
],
"prompt_input": {...},
"model_predict": {
"ReACT": "2022年7月的全球气温最高,达到了17.23℃。",
"AutoGPT": "在过去的一年中,全球气温最高的月份是2023年4月,全球表面平均气温达到了17.23°C,创下了历史新高。这一数据来自于美国国家海洋和大气管理局与美国缅因大学汇编的初步数据。",
"ModelScope": "在过去一年中,全球气温最高的月份是2023年7月。根据美国国家航空航天局(NASA)和美国国家海洋和大气管理局(NOAA)的最新研究报告,2022年是史上排名第6的最热年份,尽管拉尼娜现象改变了天气模式,抑制了全球气温。然而,2023年7月的全球平均气温达到了17.23℃,超过了7月4日和5日创下的17.18℃的联合纪录,而后者之前曾打破了7月3日创下的17.01℃的纪录。",
"ToolLlama": "Thought: I have found the information about the warmest month in 2022 in the memory. I will use this information to answer the question and call the Finish function to provide the final answer.
Action: Finish
Action Input: {"return_type": "give_answer", "final_answer": "在2022年,全球最暖的月份是5月,比20世纪平均值高出1.39°F(0.77°C)。"}",
"Kuaiagent": "在过去的一年中,全球气温最高的月份是2023年7月。根据美国国家航空航天局(NASA)和美国国家海洋和大气管理局(NOAA)的最新研究报告,2023年7月的全球平均气温达到了17.23℃,超过了19世纪50年代有仪器记录以来的任何一个月。"
}
}
注:`...` 表示内容过长,为便于展示格式已进行省略。
## 评测流程
---
以`kagentlms_qwen_7b_mat`模型的推理结果为例,基于`infer`生成的基准推理结果计算评测指标,执行以下命令可获取综合得分:
第一个参数为包含人工标注参考响应的基准评测集文件路径,第二个参数为待评测模型的预测结果文件路径。
bash
python benchmark_eval.py ./benchmark_eval.jsonl ./qwen_benchmark_res.jsonl
最终模型得分输出如下:
bash
plan : 31.64, tooluse : 28.26, reflextion : 29.50, conclusion : 44.85, profile : 44.78, overall : 34.20
提供机构:
kwaikeg
原始信息汇总
数据集概述
数据集名称
- KAgentBench
数据集来源
- 由KwaiKEG团队从Kuaishou Technology开源。
数据集内容
- 包含超过3,000个人工编辑的自动化评估数据,用于测试Agent能力。
- 评估维度包括规划、工具使用、反思、总结和用户画像。
数据集统计
- 类型:Planning & Tool-use, Reflection, Concluding, Profile
- 查询数量:Planning & Tool-use (320), Reflection (68), Concluding (245), Profile (433)
- 实例数量:Planning & Tool-use (1,317), Reflection (272), Concluding (1,225), Profile (433)
- 平均基础数量:Planning & Tool-use (4.12), Reflection (4), Concluding (5), Profile (5)
- 平均工具数量:Planning & Tool-use (8.68), Reflection (12)
- 平均轮次:Planning & Tool-use (1.51), Reflection (1), Concluding (1.52), Profile (1.99)
- 平均任务数量:Planning & Tool-use (2.21), Reflection (3.97), Concluding (2.14)
- 平均知识长度:Planning & Tool-use (245.31), Reflection (1369.04), Concluding (923.96)
- 评估指标:ROUGE-L, EM
数据集格式
- 数据点结构:
id: 唯一标识符query: 查询字符串type: 数据类型(如plantooluse, reflection, conclusion, profile)golden_result_list: 参考响应列表funcs: 可能使用的函数列表prompt_input: 由不同提示模板组成的输入字典memory: 记忆字符串memory_type: 记忆类型(如task, knowledge, conversation)memory_last_task: 前一轮任务信息的列表
数据集下载
- 可通过kwaikeg/KAgentBench或KwaiAgents下载评估集,文件名为benchmark_eval.jsonl。
实验结果
- 不同模型的性能在论文中有详细展示。
- 示例模型性能:
- GPT-3.5-turbo:Overall Score 21.72
- Llama2:Overall Score 5.22
- ChatGLM3:Overall Score 13.82
- Qwen:Overall Score 18.36
- Baichuan2:Overall Score 12.54
- ToolLlama:Overall Score 5.50
- AgentLM:Overall Score 4.86
- Qwen-MAT:Overall Score 34.20
- Baichuan2-MAT:Overall Score 38.49
评估方法
- 使用
python benchmark_eval.py脚本进行评估,输入参数为基准评估集和模型预测结果文件。 - 示例命令:
python benchmark_eval.py ./benchmark_eval.jsonl ./qwen_benchmark_res.jsonl - 评估结果示例:
plan : 31.64, tooluse : 28.26, reflextion : 29.50, conclusion : 44.85, profile : 44.78, overall : 34.20
搜集汇总
数据集介绍
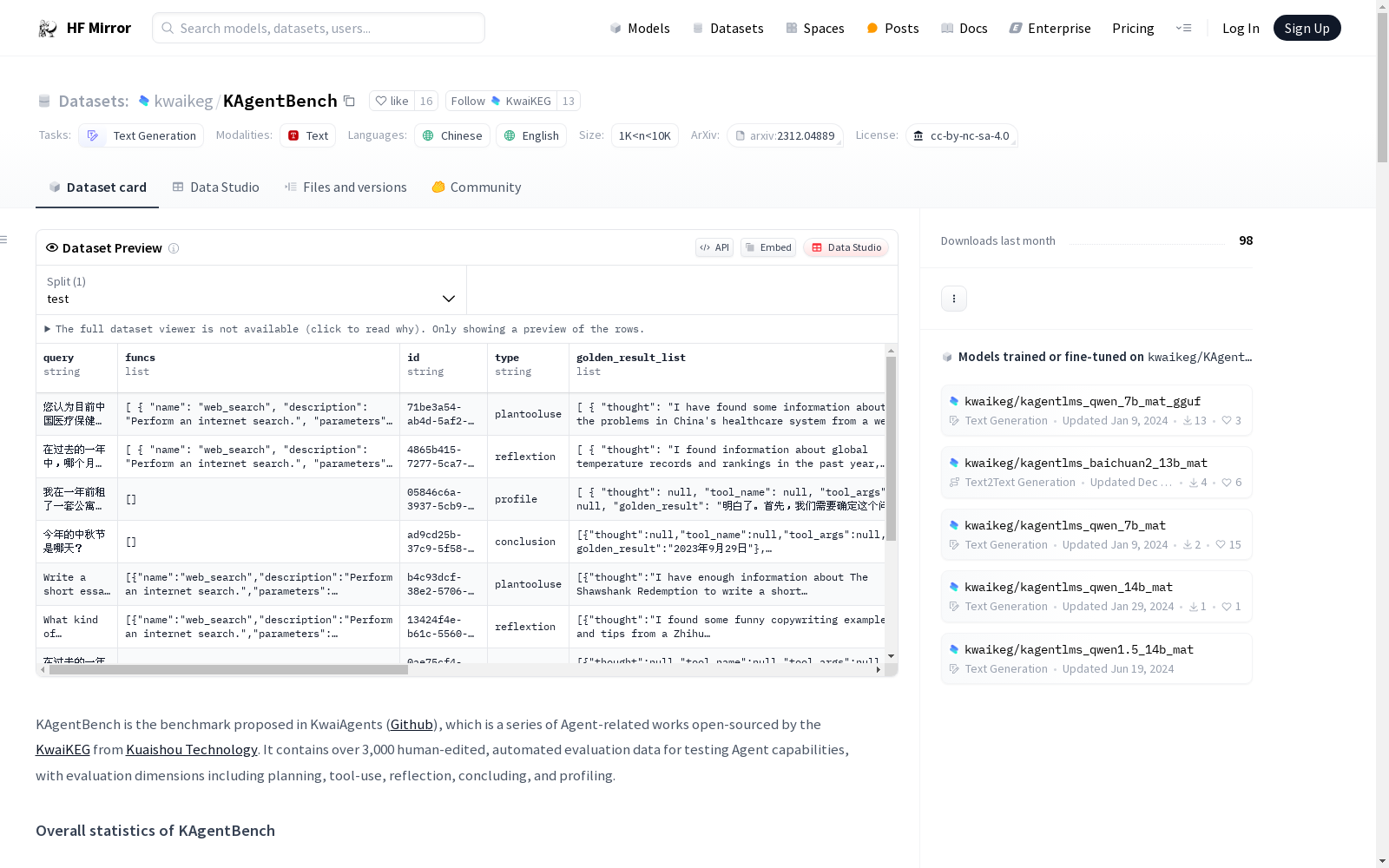
构建方式
KAgentBench数据集是由KwaiKEG团队提出并构建的,旨在评估Agent的规划、工具使用、反思、总结和概况等能力。该数据集包含超过3000条由人工编辑的自动化评估数据,涵盖了不同类型的任务,如规划与工具使用、反思、总结和概况等。数据集中的每个实例都包含了查询、类型、参考答案、可能使用的函数、输入提示、记忆以及记忆类型等信息,构建过程中充分考虑了Agent在不同维度上的评估需求。
特点
KAgentBench数据集的特点在于其多样性、全面性和实用性。它不仅包含了丰富的查询和任务类型,而且提供了详尽的参考答案和可能使用的函数列表,为Agent的评估提供了多维度的视角。此外,数据集还提供了不同规模的模型在不同任务上的性能对比,有助于研究者在不同的评估维度上对模型进行深入分析和比较。
使用方法
使用KAgentBench数据集进行模型评估时,首先需要从HuggingFace或KwaiAgents下载评估集。然后,在适当的环境下,通过加载预训练模型并运行推理脚本来生成预测结果。最后,使用提供的评估脚本,将预测结果与参考答案进行对比,计算出模型在各个任务类型上的得分,以及整体得分。这一流程使得KAgentBench成为一个易于使用且高效的评估工具。
背景与挑战
背景概述
KAgentBench是由KwaiKEG团队于近期提出的一个基准数据集,旨在评估智能体在规划、工具使用、反思、总结和概况等维度上的能力。该数据集由Kuaishou Technology支持,包含了3000余条人工编辑的自动化评估数据。KAgentBench的创建,为智能体研究领域的评估提供了新的标准和视角,对于推动智能体技术的发展具有重要的研究价值和实践意义。
当前挑战
在构建KAgentBench数据集的过程中,研究人员面临的挑战主要包括:如何全面覆盖智能体的各项能力评估维度,确保评估的全面性和准确性;如何在数据集中平衡不同类型任务的难度和数量,以保证评估的公正性和客观性;此外,针对智能体技术的快速发展,数据集还需不断更新和扩展,以适应新的技术需求和评估标准。在研究领域问题方面,KAgentBench所解决的挑战包括提高智能体在复杂场景下的规划能力、工具使用能力以及反思和总结能力,这对于提升智能体的自主性和交互能力至关重要。
常用场景
经典使用场景
KAgentBench作为一项针对智能体能力评估的基准,其经典使用场景在于为研究者提供了一个全面的测试平台,用以评估智能体在规划、工具使用、反思、总结以及画像等多维度上的表现。研究者可以通过该数据集,对智能体的决策能力进行细致的量化分析,进而优化智能体的设计和性能。
解决学术问题
该数据集解决了长期以来智能体评估缺乏统一标准的问题,为学术研究提供了可靠的实验基础。通过KAgentBench,研究者能够识别智能体在不同任务中的性能瓶颈,进而推动智能体技术在复杂环境下的自适应和决策制定能力的研究。
衍生相关工作
基于KAgentBench的数据集,已经衍生出了一系列相关研究工作,如Qwen-MAT和Baichuan2-MAT等模型在数据集上的表现研究。这些工作不仅推动了智能体技术的进步,也为智能体评估技术的发展提供了新的视角和方法。
以上内容由遇见数据集搜集并总结生成


