lmms-lab/ScienceQA
收藏Hugging Face2024-03-08 更新2024-06-22 收录
下载链接:
https://hf-mirror.com/datasets/lmms-lab/ScienceQA
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: ScienceQA-FULL
features:
- name: image
dtype: image
- name: question
dtype: string
- name: choices
sequence: string
- name: answer
dtype: int8
- name: hint
dtype: string
- name: task
dtype: string
- name: grade
dtype: string
- name: subject
dtype: string
- name: topic
dtype: string
- name: category
dtype: string
- name: skill
dtype: string
- name: lecture
dtype: string
- name: solution
dtype: string
splits:
# - name: train
# num_bytes: 422199906.182
# num_examples: 12726
- name: validation
num_bytes: 140142913.699
num_examples: 4241
- name: test
num_bytes: 138277282.051
num_examples: 4241
download_size: 679275875
dataset_size: 700620101.932
- config_name: ScienceQA-IMG
features:
- name: image
dtype: image
- name: question
dtype: string
- name: choices
sequence: string
- name: answer
dtype: int8
- name: hint
dtype: string
- name: task
dtype: string
- name: grade
dtype: string
- name: subject
dtype: string
- name: topic
dtype: string
- name: category
dtype: string
- name: skill
dtype: string
- name: lecture
dtype: string
- name: solution
dtype: string
splits:
# - name: train
# num_bytes: 413310651.0
# num_examples: 6218
- name: validation
num_bytes: 137253441.0
num_examples: 2097
- name: test
num_bytes: 135188432.0
num_examples: 2017
download_size: 663306124
dataset_size: 685752524.0
configs:
- config_name: ScienceQA-FULL
data_files:
# - split: train
# path: ScienceQA-FULL/train-*
- split: validation
path: ScienceQA-FULL/validation-*
- split: test
path: ScienceQA-FULL/test-*
- config_name: ScienceQA-IMG
data_files:
# - split: train
# path: ScienceQA-IMG/train-*
- split: validation
path: ScienceQA-IMG/validation-*
- split: test
path: ScienceQA-IMG/test-*
---
<p align="center" width="100%">
<img src="https://i.postimg.cc/g0QRgMVv/WX20240228-113337-2x.png" width="100%" height="80%">
</p>
# Large-scale Multi-modality Models Evaluation Suite
> Accelerating the development of large-scale multi-modality models (LMMs) with `lmms-eval`
🏠 [Homepage](https://lmms-lab.github.io/) | 📚 [Documentation](docs/README.md) | 🤗 [Huggingface Datasets](https://huggingface.co/lmms-lab)
# This Dataset
This is a formatted version of [derek-thomas/ScienceQA](https://huggingface.co/datasets/derek-thomas/ScienceQA). It is used in our `lmms-eval` pipeline to allow for one-click evaluations of large multi-modality models.
```
@inproceedings{lu2022learn,
title={Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering},
author={Lu, Pan and Mishra, Swaroop and Xia, Tony and Qiu, Liang and Chang, Kai-Wei and Zhu, Song-Chun and Tafjord, Oyvind and Clark, Peter and Ashwin Kalyan},
booktitle={The 36th Conference on Neural Information Processing Systems (NeurIPS)},
year={2022}
}
```
# 大规模多模态模型评测套件
> 借助`lmms-eval`加速大规模多模态模型(Large-scale Multi-modality Models, LMMs)的研发
🏠 [主页](https://lmms-lab.github.io/) | 📚 [文档](docs/README.md) | 🤗 [Huggingface数据集](https://huggingface.co/lmms-lab)
# 本数据集
本数据集是[derek-thomas/ScienceQA(科学问答数据集)](https://huggingface.co/datasets/derek-thomas/ScienceQA)的格式化版本,被应用于我们的`lmms-eval`流程中,以实现大规模多模态模型的一键式评测。
@inproceedings{lu2022learn,
title={学会解释:面向科学问答任务的基于思维链的多模态推理},
author={Lu Pan、Swaroop Mishra、Tony Xia、Liang Qiu、Kai-Wei Chang、Song-Chun Zhu、Øyvind Tafjord、Peter Clark、Ashwin Kalyan},
booktitle={第36届神经信息处理系统会议(NeurIPS 2022)},
year={2022}
}
<p align="center" width="100%">
<img src="https://i.postimg.cc/g0QRgMVv/WX20240228-113337-2x.png" width="100%" height="80%">
</p>
## 数据集信息
- 配置名称:ScienceQA-FULL
特征列表:
- 字段名:image,数据类型:图像
- 字段名:question,数据类型:字符串
- 字段名:choices,数据类型:字符串序列
- 字段名:answer,数据类型:int8(8位有符号整数)
- 字段名:hint,数据类型:字符串
- 字段名:task,数据类型:字符串
- 字段名:grade,数据类型:字符串
- 字段名:subject,数据类型:字符串
- 字段名:topic,数据类型:字符串
- 字段名:category,数据类型:字符串
- 字段名:skill,数据类型:字符串
- 字段名:lecture,数据类型:字符串
- 字段名:solution,数据类型:字符串
划分集:
# - 划分名称:训练集
# 字节数:422199906.182
# 样本数量:12726
- 划分名称:验证集
字节数:140142913.699
样本数量:4241
- 划分名称:测试集
字节数:138277282.051
样本数量:4241
下载大小:679275875
数据集总大小:700620101.932
- 配置名称:ScienceQA-IMG
特征列表:
- 字段名:image,数据类型:图像
- 字段名:question,数据类型:字符串
- 字段名:choices,数据类型:字符串序列
- 字段名:answer,数据类型:int8(8位有符号整数)
- 字段名:hint,数据类型:字符串
- 字段名:task,数据类型:字符串
- 字段名:grade,数据类型:字符串
- 字段名:subject,数据类型:字符串
- 字段名:topic,数据类型:字符串
- 字段名:category,数据类型:字符串
- 字段名:skill,数据类型:字符串
- 字段名:lecture,数据类型:字符串
- 字段名:solution,数据类型:字符串
划分集:
# - 划分名称:训练集
# 字节数:413310651.0
# 样本数量:6218
- 划分名称:验证集
字节数:137253441.0
样本数量:2097
- 划分名称:测试集
字节数:135188432.0
样本数量:2017
下载大小:663306124
数据集总大小:685752524.0
配置项:
- 配置名称:ScienceQA-FULL
数据文件:
# - 划分:训练集
# 路径:ScienceQA-FULL/train-*
- 划分:验证集
路径:ScienceQA-FULL/validation-*
- 划分:测试集
路径:ScienceQA-FULL/test-*
- 配置名称:ScienceQA-IMG
数据文件:
# - 划分:训练集
# 路径:ScienceQA-IMG/train-*
- 划分:验证集
路径:ScienceQA-IMG/validation-*
- 划分:测试集
路径:ScienceQA-IMG/test-*
提供机构:
lmms-lab
原始信息汇总
数据集概述
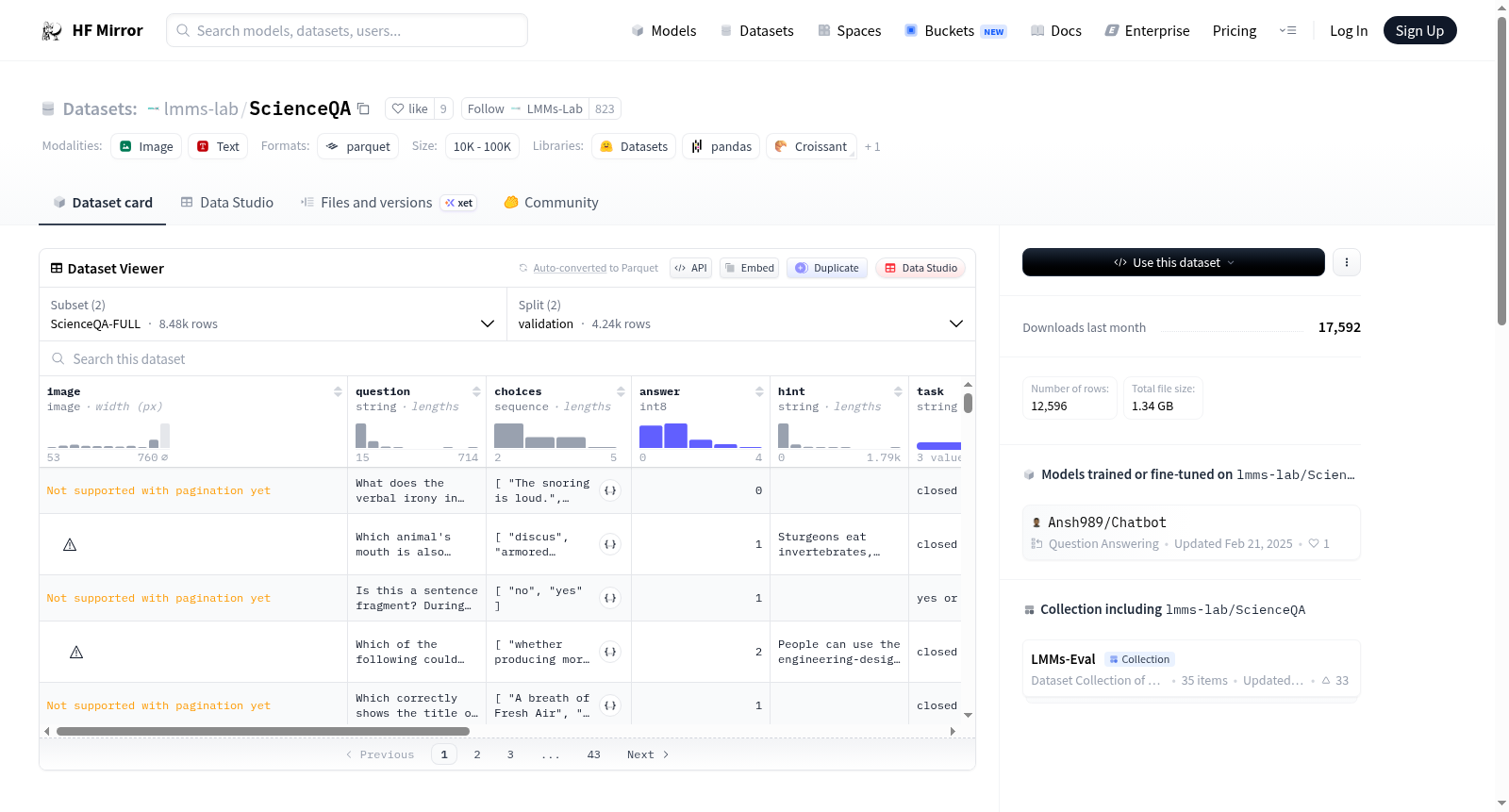
ScienceQA-FULL
- 特征:
image: 图像类型question: 字符串类型choices: 字符串序列answer: 8位整数类型hint: 字符串类型task: 字符串类型grade: 字符串类型subject: 字符串类型topic: 字符串类型category: 字符串类型skill: 字符串类型lecture: 字符串类型solution: 字符串类型
- 拆分:
validation: 140142913.699字节, 4241个样本test: 138277282.051字节, 4241个样本
- 下载大小: 679275875字节
- 数据集大小: 700620101.932字节
ScienceQA-IMG
- 特征:
image: 图像类型question: 字符串类型choices: 字符串序列answer: 8位整数类型hint: 字符串类型task: 字符串类型grade: 字符串类型subject: 字符串类型topic: 字符串类型category: 字符串类型skill: 字符串类型lecture: 字符串类型solution: 字符串类型
- 拆分:
validation: 137253441字节, 2097个样本test: 135188432字节, 2017个样本
- 下载大小: 663306124字节
- 数据集大小: 685752524字节
数据文件配置
- ScienceQA-FULL:
validation: ScienceQA-FULL/validation-*test: ScienceQA-FULL/test-*
- ScienceQA-IMG:
validation: ScienceQA-IMG/validation-*test: ScienceQA-IMG/test-*
搜集汇总
数据集介绍
构建方式
在科学教育领域,高质量的多模态数据集对于评估模型的理解与推理能力至关重要。ScienceQA数据集通过系统化地整合视觉与文本信息构建而成,其内容源自广泛的科学学科,涵盖从小学到高中的多个年级。数据采集过程严格遵循教育标准,确保题目在学科知识、认知技能和图像关联性上具有代表性。每个样本均包含问题、选项、答案及丰富的元数据,如图像、提示、讲解和解决方案,这些元素共同构成了一个结构严谨的多模态评估基准。
特点
该数据集以其全面的多模态特性脱颖而出,不仅融合了图像与文本,还提供了精细的学科分类和技能标注。每个问题均关联具体的学科、主题、年级及任务类型,并附带详细的讲解和解决方案,这为深入分析模型的推理过程提供了可能。数据集分为ScienceQA-FULL和ScienceQA-IMG两个版本,后者专注于包含图像的问题,使得研究者能够针对视觉理解能力进行专项评估。其丰富的元数据层支持多维度的性能剖析,推动了大型多模态模型在科学问答领域的精准评测。
使用方法
在大型多模态模型的评估流程中,ScienceQA数据集可通过lmms-eval框架实现一键式评测。用户首先加载数据集的指定配置,如ScienceQA-FULL或ScienceQA-IMG,随后利用验证集和测试集进行模型推理。评估过程支持端到端的多模态输入处理,模型需综合图像与文本信息生成答案,系统将自动比对预测结果与标注答案,并计算准确率等指标。该集成化方法显著简化了评测复杂度,使研究者能专注于模型性能的深入分析,加速多模态推理技术的迭代发展。
背景与挑战
背景概述
ScienceQA数据集由Pan Lu等研究人员于2022年构建,作为NeurIPS会议上的重要成果,该数据集旨在推动多模态推理与科学问答领域的研究。其核心研究问题聚焦于通过思维链机制,促进模型在科学问题解答中的解释性推理能力。数据集涵盖丰富的学科主题与年级层次,不仅为大规模多模态模型的评估提供了标准化基准,也显著提升了人工智能在复杂科学知识理解与推理方面的研究深度。
当前挑战
ScienceQA数据集所应对的领域挑战在于,科学问答往往需要模型融合文本与图像信息,进行跨模态的深度推理与因果解释,这对现有多模态模型的逻辑连贯性与知识泛化能力提出了较高要求。在构建过程中,数据收集面临学科多样性平衡与多模态对齐的复杂性,同时标注高质量的思维链解答需确保科学准确性与教育适用性,这些因素共同构成了数据集构建的核心难点。
常用场景
经典使用场景
在科学教育领域,ScienceQA数据集为多模态推理研究提供了关键基准。该数据集整合了图像、文本问题与多项选择答案,其经典使用场景在于评估大型多模态模型在科学问答任务中的表现。研究者通过该数据集能够系统地测试模型对跨学科知识的理解能力,尤其是在处理需要结合视觉信息与文本推理的复杂问题时,数据集的结构化设计使得模型性能的量化分析成为可能。
解决学术问题
ScienceQA数据集主要解决了多模态推理中解释性生成的学术挑战。传统模型往往在结合视觉与语言信息进行因果推断时存在局限,该数据集通过提供带有思维链标注的样本,促进了可解释人工智能的发展。它帮助研究者探索模型如何模拟人类的推理过程,从而在科学问题解答中实现更透明、更可靠的决策机制,推动了多模态学习理论向更深层次的演进。
衍生相关工作
围绕ScienceQA数据集,衍生出了一系列经典研究工作。例如,原论文《Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering》提出了思维链推理框架,启发了后续多模态大模型的评估方法。许多研究在此基础上开发了新的基准测试工具,如lmms-eval评估套件,这些工作不仅扩展了数据集的适用场景,还推动了多模态人工智能在科学认知与推理任务中的标准化进程。
以上内容由遇见数据集搜集并总结生成


