triton-sft-dataset
收藏Hugging Face2025-06-03 更新2025-06-04 收录
下载链接:
https://huggingface.co/datasets/cdreetz/triton-sft-dataset
下载链接
链接失效反馈官方服务:
资源简介:
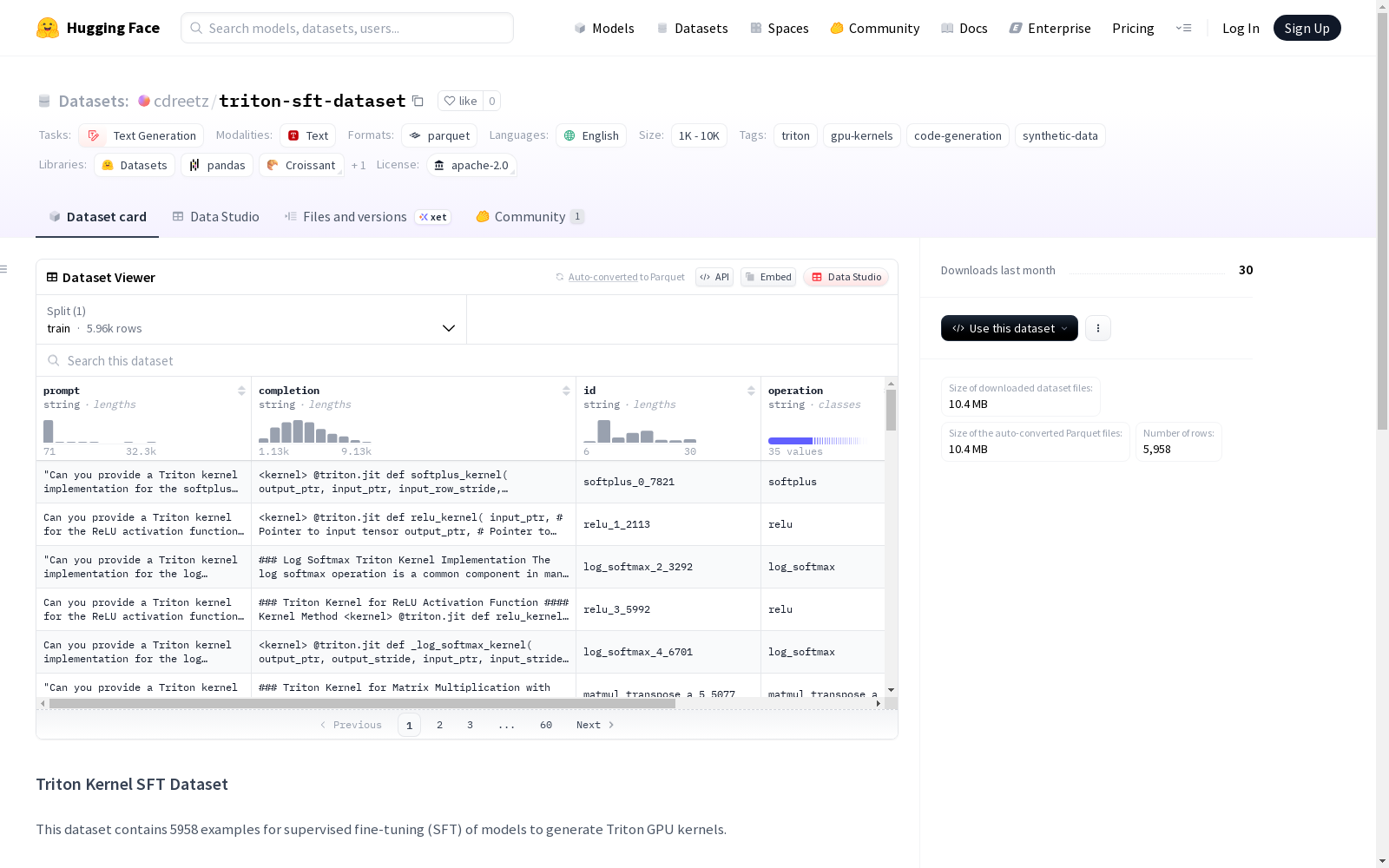
Triton Kernel SFT数据集包含5958个示例,用于模型的监督微调,以便生成Triton GPU内核。数据集由两种类型的示例组成:60%的合成查询(请求各种操作的Triton内核)和40%的转换查询(将PyTorch代码转换为Triton内核的请求)。每个示例包括一个提示(请求Triton内核的指令/查询)、一个完成(相应的Triton内核实现)以及包含类型、操作和ID的元数据。
创建时间:
2025-06-02
原始信息汇总
Triton Kernel SFT 数据集概述
基本信息
- 许可证: Apache-2.0
- 任务类别: 文本生成
- 语言: 英语
- 标签:
- Triton
- GPU-kernels
- 代码生成
- 合成数据
- 数据规模: 1K<n<10K
数据集描述
- 目的: 用于监督微调(SFT)模型以生成Triton GPU内核
- 示例数量: 5958
数据集内容
- 示例类型:
- 合成查询 (60%): 生成的请求各种操作的Triton内核的查询
- 转换查询 (40%): 将PyTorch代码转换为Triton内核的请求
数据结构
每个示例包含以下字段:
prompt: 请求Triton内核的指令/查询completion: 对应的Triton内核实现id: 唯一标识符operation: 操作类型(如"matmul", "softmax"等)type: 查询类型("synthetic"或"convert")has_triton_docs: 布尔值,表示生成过程中是否使用了Triton文档
使用方法
python from datasets import load_dataset dataset = load_dataset("cdreetz/triton-sft-dataset")
生成方式
- 方法: 使用语言模型的自动提示技术生成多样化的训练示例
搜集汇总
数据集介绍
构建方式
在GPU加速计算领域,Triton-sft-dataset采用自动化提示工程与语言模型协同生成机制,构建了包含5958个监督微调样本的高质量语料库。其中60%为通过合成查询技术生成的Triton内核请求指令,40%为将PyTorch代码转换为Triton内核的实际转换需求,每个样本均配备唯一标识符并标注操作类型与生成来源。
使用方法
研究者可通过HuggingFace数据集库直接加载该资源,使用标准load_dataset函数调用即可获取完整训练集。该数据集专为文本生成任务设计,适用于训练具有Triton内核代码生成能力的语言模型,建议在GPU加速编程教学、自动代码生成系统等场景中作为监督微调的基础训练数据。
背景与挑战
背景概述
随着GPU加速计算在深度学习领域的广泛应用,高效GPU内核开发成为提升计算性能的关键技术。Triton-sft-dataset由研究团队于近期创建,专注于Triton GPU内核代码生成领域,旨在通过监督微调技术优化大语言模型在GPU内核编程方面的表现。该数据集包含近6000个高质量样本,涵盖合成查询和代码转换两种类型,为自动化GPU内核生成提供了重要的训练资源,对推动高性能计算和编译器优化研究具有显著价值。
当前挑战
在GPU内核代码生成领域,主要挑战在于处理复杂的并行计算模式和内存访问模式,同时确保生成代码的性能优化和正确性。数据集构建过程中面临生成高质量训练样本的挑战,包括保持代码语义一致性、覆盖多样化的计算操作类型,以及平衡合成数据与真实代码转换样本的比例。此外,确保生成的Triton内核与不同硬件架构的兼容性,以及处理各种边界情况和异常处理机制,都是需要解决的关键技术难题。
常用场景
经典使用场景
在GPU编程领域,Triton SFT数据集主要应用于大语言模型的监督微调过程,专门针对Triton GPU内核代码生成任务。该数据集通过精心设计的提示-完成配对,为模型提供学习高性能GPU内核编写的标准范式,涵盖矩阵乘法、softmax等典型并行计算操作,显著提升模型生成优化计算代码的能力。
解决学术问题
该数据集有效解决了代码生成模型中专业领域知识匮乏的学术难题,特别是针对GPU并行编程这一高度专业化领域。通过提供结构化的Triton内核实现样本,它填补了通用代码生成模型与特定硬件优化之间的知识鸿沟,为研究模型在低资源领域适应性问题提供了重要实验基础,推动了专业化代码生成技术的发展。
实际应用
在实际工业应用中,该数据集为开发高性能计算库和深度学习框架提供了核心训练资源。工程师可利用经过该数据集微调的模型,自动将PyTorch等框架的代码转换为优化的Triton内核,大幅提升GPU计算效率。这种应用显著降低了手动编写优化内核的技术门槛,加速了AI系统在推理和训练阶段的性能优化进程。
数据集最近研究
最新研究方向
在GPU加速计算领域,Triton-sft-dataset作为专门针对Triton GPU内核生成的监督微调数据集,正推动编译器优化与代码生成研究的深度融合。当前研究聚焦于利用合成数据与真实代码转换相结合的模式,探索大语言模型在高性能计算内核自动生成中的泛化能力。该数据集通过覆盖矩阵乘法、softmax等典型算子,为研究异构计算架构下的程序优化提供了重要基准。随着AI编译技术需求的爆发式增长,此类数据集已成为连接自然语言编程与底层硬件优化的重要桥梁,显著降低了GPU内核开发的技术门槛。
以上内容由遇见数据集搜集并总结生成


