SID_Set_description
收藏Hugging Face2025-06-10 更新2025-06-11 收录
下载链接:
https://huggingface.co/datasets/saberzl/SID_Set_description
下载链接
链接失效反馈官方服务:
资源简介:
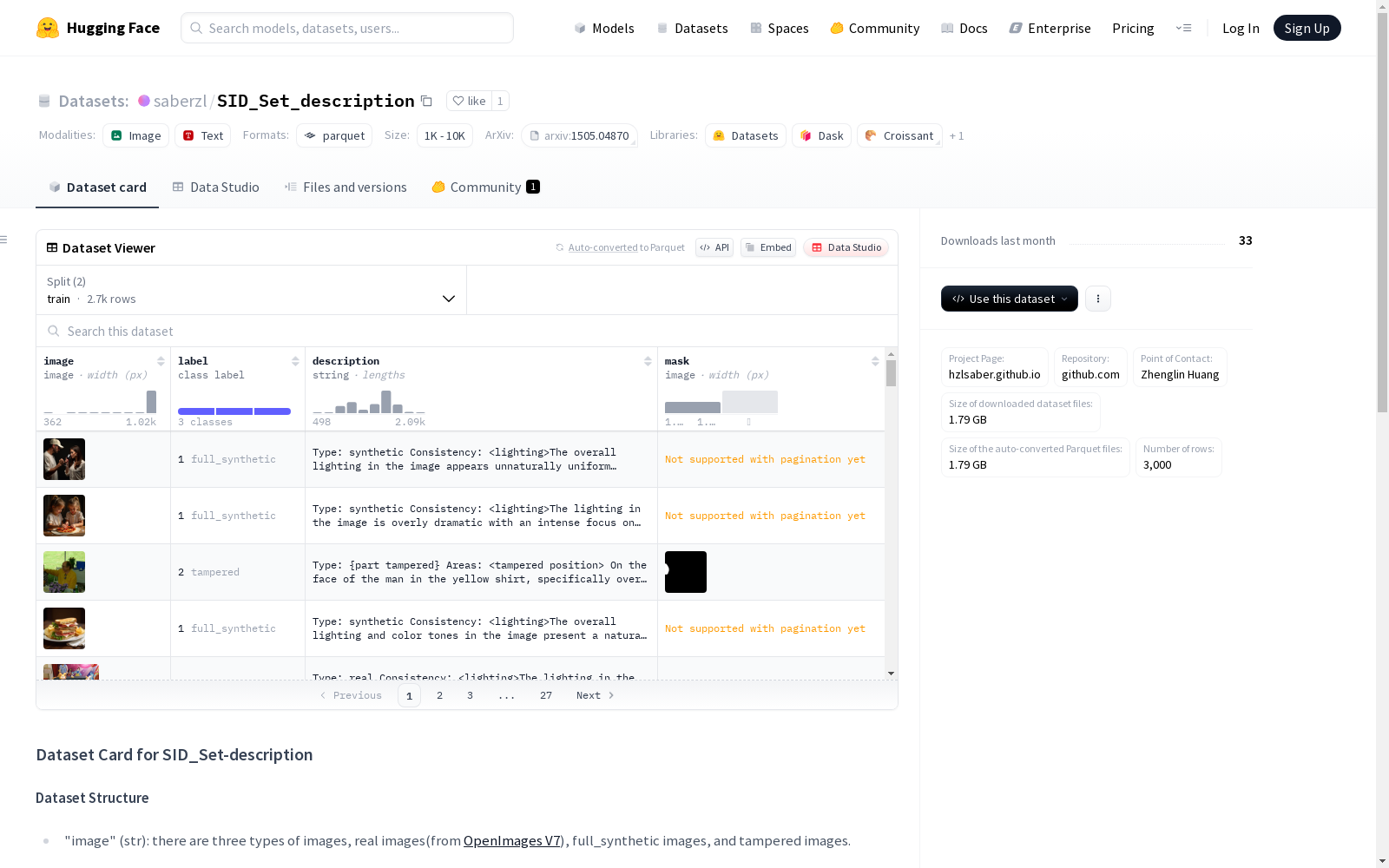
SID_Set是一个用于社交媒体图像深度伪造检测、定位和解释的数据集,包含真实图像、全合成图像和篡改图像。数据集分为训练集和验证集,共有3000个图像,其中训练集有2700个图像,验证集有300个图像。
创建时间:
2025-06-09
原始信息汇总
SID_Set-description 数据集概述
数据集基本信息
- 项目页面: https://hzlsaber.github.io/projects/SIDA/
- 代码仓库: https://github.com/hzlsaber/SIDA
- 联系人: Zhenglin Huang
数据集结构
特征
- image (图像类型): 包含三种类型图像:
- 真实图像(来自OpenImages V7)
- 全合成图像
- 篡改图像
- mask (图像类型): 二值掩码,突出显示篡改图像中的篡改区域
- label (类别标签): 分类类别:
- 0: 真实图像
- 1: 全合成图像
- 2: 篡改图像
- description (字符串): 图像真实性分析描述
数据划分
- train: 2700个样本,大小1606820841.7字节
- validation: 300个样本,大小178172694.0字节
技术规格
- 下载大小: 1788697083字节
- 数据集大小: 1784993535.7字节
许可信息
- 采用Creative Commons Attribution 4.0 International License
- 包含来自以下数据集的内容:
引用信息
bibtex @misc{huang2025sidasocialmediaimage, title={SIDA: Social Media Image Deepfake Detection, Localization and Explanation with Large Multimodal Model}, author={Zhenglin Huang and Jinwei Hu and Xiangtai Li and Yiwei He and Xingyu Zhao and Bei Peng and Baoyuan Wu and Xiaowei Huang and Guangliang Cheng}, year={2025}, booktitle={Conference on Computer Vision and Pattern Recognition} }
搜集汇总
数据集介绍
构建方式
SID_Set_description数据集构建融合了多源图像数据,采用严谨的标注流程确保数据质量。其核心图像素材源自OpenImages V7的真实图像库,通过专业算法生成全合成图像,并基于图像处理技术创建篡改样本。每张篡改图像均配有精确的二值掩膜标注,清晰标记篡改区域。数据划分遵循机器学习标准,包含2700张训练图像和300张验证图像,形成平衡的数据分布。
特点
该数据集在图像真实性检测领域具有显著特色,涵盖真实、全合成和篡改三类图像,构建完整的真实性检测体系。每张图像附带详细的文本描述,为多模态分析提供支持。特别设计的二值掩膜标注能精确定位篡改区域,支持细粒度分析。数据集严格遵循CC BY 4.0国际许可协议,整合了COCO、OpenImages V7等权威数据源,确保法律合规性。
使用方法
使用该数据集时,建议采用端到端的深度学习框架处理图像分类任务。输入层可同时加载图像数据和对应掩膜,通过卷积神经网络提取视觉特征。文本描述字段可用于构建多模态模型,增强分类性能。数据已预分为训练集和验证集,支持直接用于模型训练与评估。研究者可参考项目页面的技术文档,结合大型多模态模型进行深度伪造检测、定位和解释的完整流程开发。
背景与挑战
背景概述
SID_Set_description数据集由利物浦大学的Zhenglin Huang等人于2025年构建,旨在应对社交媒体图像深度伪造检测与定位的研究需求。该数据集整合了来自OpenImages V7的真实图像、全合成图像以及篡改图像,通过多模态标注(包括分类标签、文本描述和篡改区域掩码)为图像真实性分析提供了丰富的基准数据。作为计算机视觉领域的重要资源,该数据集特别针对深度伪造检测模型的泛化能力和可解释性研究,其成果已发表于计算机视觉顶级会议CVPR,对推动数字媒体取证技术的发展具有显著意义。
当前挑战
该数据集面临的核心挑战体现在两个维度:在领域问题层面,深度伪造技术的快速演进导致伪造痕迹愈发隐蔽,要求检测模型具备对微妙伪影的捕捉能力与跨域泛化性能;在构建过程中,需平衡真实图像与合成/篡改图像的样本分布,确保掩码标注精确覆盖复杂篡改区域。多源数据的版权合规性整合(如COCO、OpenImages V7和Flickr30k)以及文本描述与视觉内容的语义对齐,进一步增加了数据集构建的复杂度。
常用场景
经典使用场景
在数字图像真实性检测领域,SID_Set_description数据集通过提供真实图像、全合成图像及篡改图像的三分类标注,为研究者构建了一个标准化的基准测试平台。该数据集特别适用于训练深度学习模型识别社交媒体中经过局部篡改或完全合成的图像,其掩模标注能精确定位篡改区域,为图像取证研究提供了关键技术支持。
解决学术问题
该数据集有效解决了数字图像篡改检测中标注数据稀缺的核心问题,其多模态标注结构(图像-掩模-文本描述)支持端到端的深度伪造检测模型开发。通过融合OpenImages等权威数据源的图像,它推动了图像真实性验证任务从二分类(真实/伪造)向细粒度三分类(真实/全合成/局部篡改)的范式升级,为解释性AI在视觉内容分析中的应用奠定数据基础。
衍生相关工作
该数据集直接催生了CVPR 2025发表的SIDA多模态检测框架,其提供的基准测试结果被后续研究广泛引用。基于其构建的变体数据集如SID-3D拓展了三维模型伪造检测方向,而衍生的Explainable-Forgery基准则推动了可解释性检测算法的发展,形成数字图像取证领域的研究谱系。
以上内容由遇见数据集搜集并总结生成


