cc12
收藏Hugging Face2025-04-16 更新2025-04-17 收录
下载链接:
https://huggingface.co/datasets/Salmonnn/cc12
下载链接
链接失效反馈官方服务:
资源简介:
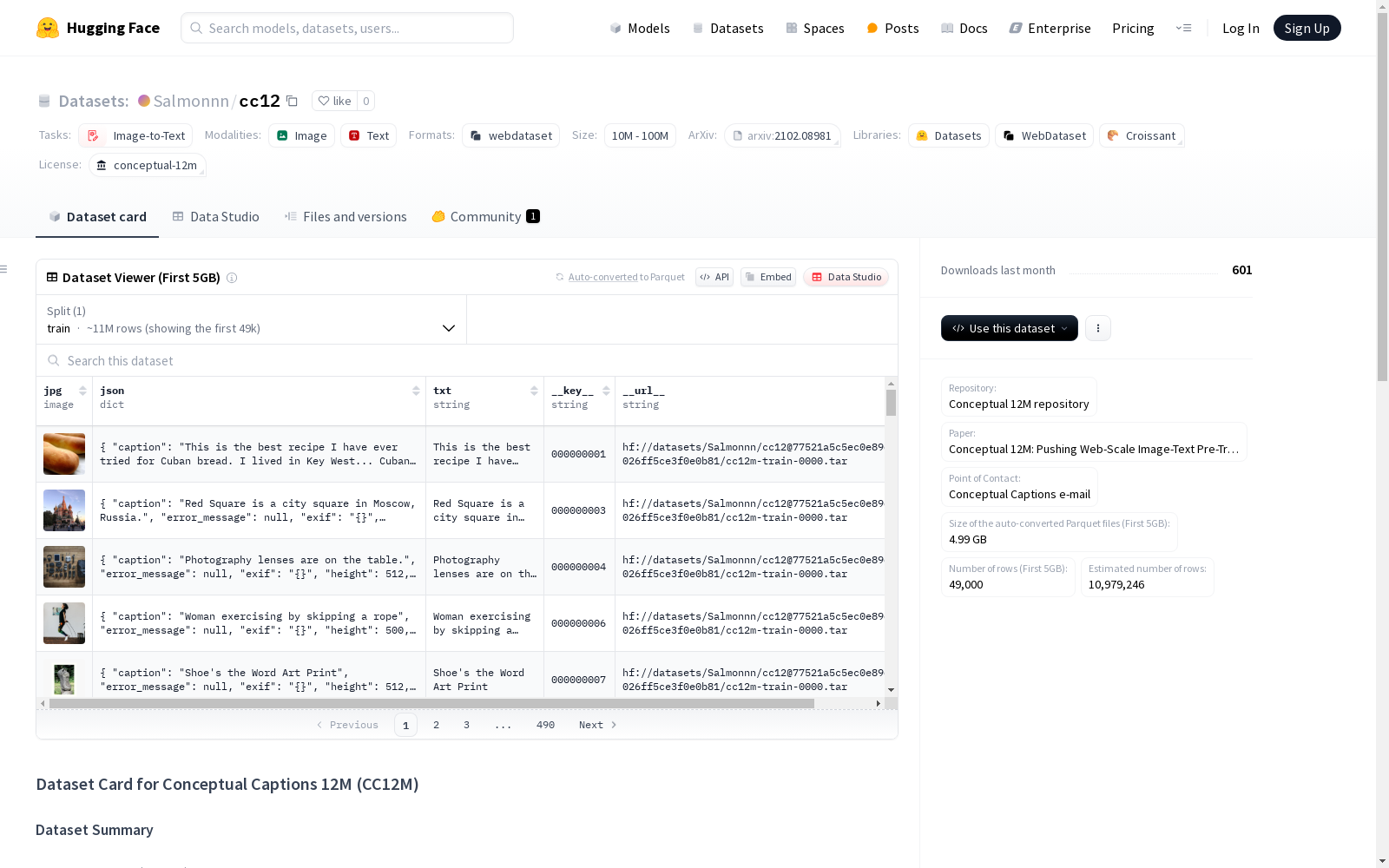
概念 captions 12M(CC12M)是一个包含1200万张图像-文本对的数据库,专门用于视觉和语言预训练。它的数据收集流程是Conceptual Captions 3M(CC3M)的一个宽松版本。
创建时间:
2025-04-10
搜集汇总
数据集介绍
构建方式
在计算机视觉与自然语言处理的交叉领域,Conceptual 12M(CC12M)数据集的构建采用了创新的网络规模数据采集策略。该数据集基于Conceptual Captions 3M(CC3M)的采集流程进行优化,通过自动化系统从公开网络资源中筛选出1200万张高质量图像-文本对。为确保数据多样性,采集过程特别关注长尾视觉概念的覆盖,采用图像最短边限制为512像素的智能缩放技术,有效平衡了数据规模与质量。
特点
作为当前最大规模的开放图像-文本数据集之一,CC12M的突出特点体现在其海量样本与精细标注的完美结合。数据集涵盖自然场景、抽象概念等多元视觉内容,每个样本均配有语义丰富的描述文本。2176个分片式存储结构显著提升数据读取效率,而严格的尺寸标准化处理则保障了模型输入的规范性。这种设计特别适合训练需要理解复杂视觉语义关系的多模态模型。
使用方法
研究者可通过WebDataset格式高效加载CC12M数据集,其分片式.tar文件结构兼容主流深度学习框架。借助Hugging Face datasets库或专用webdataset工具包,用户能灵活实现数据流的并行加载与实时解码。该数据集主要服务于视觉-语言预训练任务,如跨模态检索、图像描述生成等前沿研究方向,使用时需注意遵守Google规定的数据使用条款。
背景与挑战
背景概述
Conceptual 12M(CC12M)数据集由Google Research团队于2021年推出,旨在推动大规模图像-文本预训练模型的发展,特别是在识别长尾视觉概念方面的能力。该数据集包含1200万对图像-文本数据,是Conceptual Captions 3M(CC3M)数据集的扩展版本,采用了更为宽松的数据收集策略。CC12M的发布为计算机视觉和自然语言处理领域的多模态研究提供了丰富资源,显著提升了模型在复杂视觉场景下的理解和生成能力。该数据集的核心研究问题聚焦于如何利用网络规模的图像-文本数据提升模型的泛化性能,尤其是在处理罕见或长尾视觉概念时的表现。
当前挑战
CC12M数据集面临的挑战主要体现在两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,尽管CC12M为多模态预训练提供了海量数据,但如何有效利用这些数据提升模型对长尾视觉概念的识别能力仍是一个关键难题。数据中的噪声和标注不一致性可能影响模型性能。在构建过程中,数据收集和清洗的复杂性带来了显著挑战。网络来源的图像和文本质量参差不齐,需要设计高效的过滤和验证机制。此外,数据规模的急剧扩大也带来了存储和计算资源的需求激增,如何平衡数据规模与质量成为构建过程中的核心问题。
常用场景
经典使用场景
在计算机视觉与自然语言处理的交叉领域,CC12M数据集以其1200万规模的图像-文本对成为多模态预训练任务的黄金标准。该数据集特别适用于训练视觉-语言联合表征模型,研究者通过对比学习或跨模态注意力机制,能够有效捕捉图像内容与文本描述之间的深层语义关联。其海量样本覆盖长尾视觉概念的特性,使得模型在零样本迁移学习场景中展现出卓越的泛化能力。
解决学术问题
CC12M的构建从根本上解决了视觉-语言预训练中数据稀缺与分布不均两大核心难题。通过自动化爬取与过滤网络图像-文本对,该数据集显著扩充了传统手工标注数据集的规模,尤其改善了模型对低频视觉概念的识别性能。在CVPR 2021的研究中证实,基于CC12M预训练的模型在COCO等基准数据集上实现了3-5个百分点的性能提升,为开放域视觉理解任务设立了新的基线标准。
衍生相关工作
该数据集催生了CLIP-ViT、ALIGN等一系列里程碑式多模态架构,其中OpenAI的GLIDE模型通过CC12M扩展训练数据,实现了文本引导的图像生成突破。微软研究院提出的BEiT-3框架更是在此基础上引入跨模态掩码建模,在VLUE评测中创下89.7%的最新准确率记录,推动了视觉-语言统一表征的理论发展。
以上内容由遇见数据集搜集并总结生成


