cc-task1-json
收藏Hugging Face2026-05-17 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/AbstractPhil/cc-task1-json
下载链接
链接失效反馈官方服务:
资源简介:
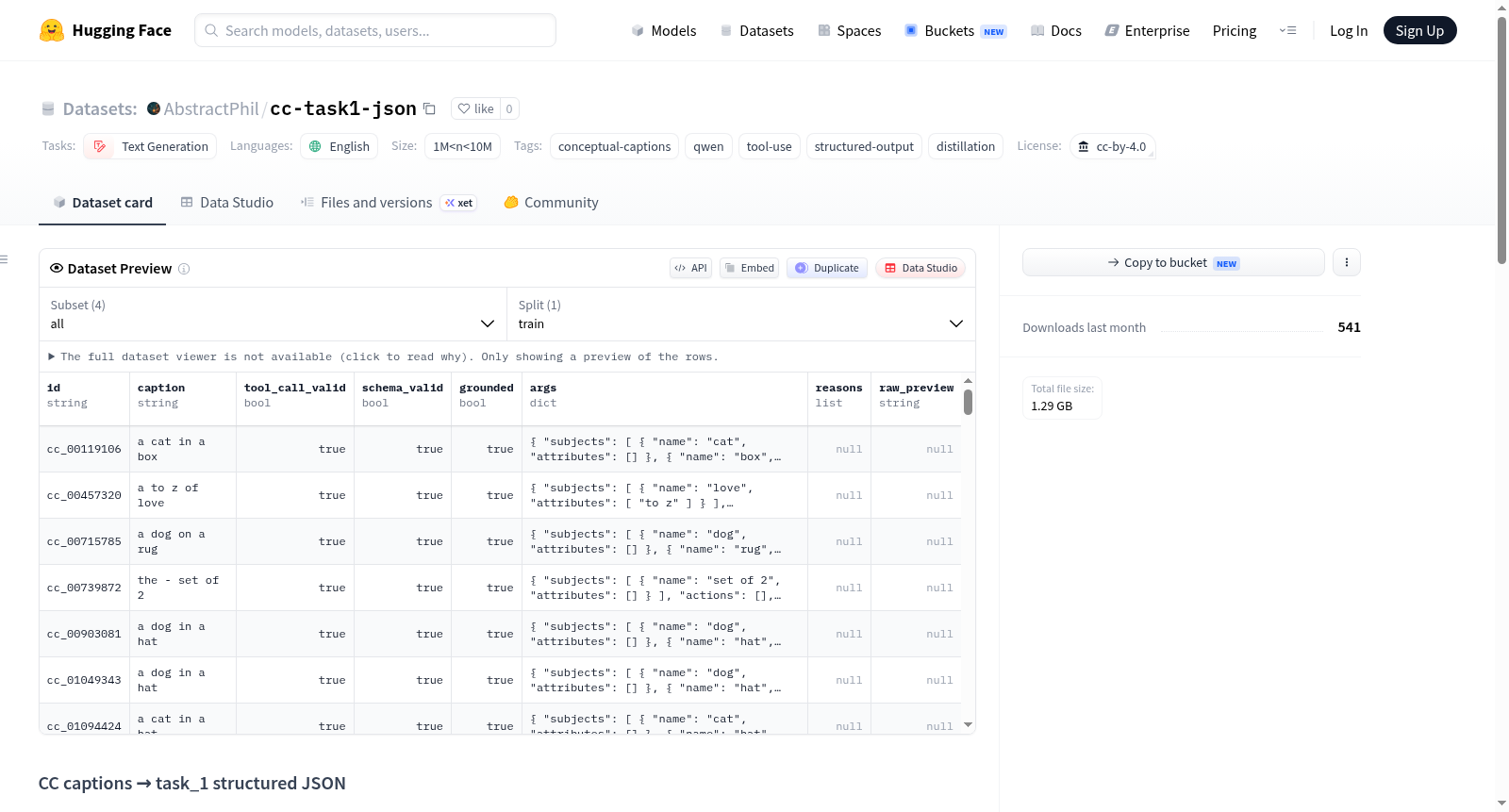
该数据集名为CC captions → task_1 structured JSON,是基于Conceptual Captions图像描述数据集,通过Qwen3.5-0.8B模型结合特定LoRA适配器(AbstractPhil/qwen3.5-0.8b-task_1-lora)进行转换和增强而生成的。其核心目的是将原始的、自由的图像描述文本转换为结构化的JSON格式,具体执行字面信息提取任务(task_1)。转换过程不仅生成了结构化数据,还对其进行了模式有效性和基础性评分,以确保数据质量。数据规模在100万到1000万条之间,包含三个分片(shard_0, shard_1, shard_2)和一个汇总配置(all)。每条数据记录包含以下字段:唯一标识符(id)、原始描述(caption)、多个有效性标志(tool_call_valid, schema_valid, grounded)以及核心的结构化参数对象(args)。其中,args对象包含subjects(主体)、actions(动作)、setting(场景,如室内/室外)、style(风格)和mood(情绪)等字段。只有当grounded字段为true的记录才被认为是可直接用于训练的。该数据集适用于需要模型学习生成或理解特定JSON模式的文本生成任务,特别是工具调用、结构化输出和知识蒸馏等场景。用户可以使用Hugging Face datasets库加载,并轻松过滤出高质量的训练样本。
The dataset is named CC captions → task_1 structured JSON and is generated based on the Conceptual Captions image description dataset, transformed and enhanced using the Qwen3.5-0.8B model with a specific LoRA adapter (AbstractPhil/qwen3.5-0.8b-task_1-lora). Its core purpose is to convert original, free-form image description texts into structured JSON format, specifically performing the literal information extraction task (task_1). The conversion process not only generates structured data but also scores it for schema validity and groundedness to ensure data quality. The data scale ranges from 1 million to 10 million entries, including three shards (shard_0, shard_1, shard_2) and a summary configuration (all). Each data record contains the following fields: a unique identifier (id), the original description (caption), multiple validity flags (tool_call_valid, schema_valid, grounded), and the core structured parameter object (args). The args object includes fields such as subjects, actions, setting (e.g., indoor/outdoor), style, and mood. Only records with the grounded field set to true are considered directly usable for training. This dataset is suitable for text generation tasks that require models to learn to generate or understand specific JSON patterns, particularly in scenarios like tool-use, structured-output, and distillation. Users can load it using the Hugging Face datasets library and easily filter out high-quality training samples.
创建时间:
2026-05-15
搜集汇总
数据集介绍
构建方式
本数据集基于Conceptual Captions(CC)图像标题数据,通过微调后的Qwen3.5-0.8B模型(适配器为AbstractPhil/qwen3.5-0.8b-task_1-lora),将原始英文图像提示转换为结构化的任务型JSON格式。构建过程在Google Colab平台上完成,使用三台并行运行的RTX 6000 Pro Blackwell GPU,每台处理一个数据分片(shard_0、shard_1、shard_2),以每批128条以上的批量推理方式,每10000行进行一次分块上传,总计耗时约50小时。推理时所用的系统提示词和工具定义来源于AbstractPhil/json-coco-format数据集,确保转换语义一致。
特点
该数据集包含约数百万条记录,每条数据包含原始标题、唯一标识符,以及由模型生成的JSON字段,如主体、动作、场景设置(室内/室外/未知)、风格和情绪等。所有记录均经过模式验证和语义可靠性评分,其中grounded字段为true的行可直接用于监督微调。数据集的显著特点是结构高度规范化,支持直接过滤以获取高质量训练样本,同时保留了原始自然语言标题,便于追踪和分析。
使用方法
用户可通过HuggingFace的datasets库加载数据集,例如使用load_dataset('AbstractPhil/cc-task1-json', 'all', split='train')加载全部分片。推荐在加载后过滤grounded字段为true的记录,以确保数据质量。对于监督微调任务,需从caption和args字段动态重建消息数组,可参考元数据集中的格式模板。数据集提供多个配置(shard_0至shard_2及all),便于分布式处理或部分采样。
背景与挑战
背景概述
cc-task1-json数据集由研究者AbstractPhil于近期创建,旨在将Conceptual Captions数据集中的英文图像提示转化为结构化JSON格式,以服务于文本生成与工具使用领域的模型训练。该数据集依托Qwen3.5-0.8B模型并通过LoRA微调实现批量蒸馏,其核心研究问题在于如何从自然语言描述中自动提取主体、动作、场景等结构化信息,以增强模型对视觉语义的解析与推理能力。作为连接图像描述与结构化输出的一座桥梁,cc-task1-json为多模态与语言模型的指令微调提供了重要的训练素材,尤其在小规模轻量级模型的知识蒸馏与工具调用场景中展现出独特的应用价值。
当前挑战
该数据集首先致力于解决图像描述领域的关键挑战——将非结构化的自然语言提示自动转化为可机读的结构化JSON格式,支持工具调用与结构化输出任务。在构建过程中,研究人员面临多重困难:使用轻量级Qwen3.5-0.8B模型进行蒸馏,导致上下文关联有限、主题错误与无效上下文频发;原始模型生成的JSON结构存在基础性缺陷,且输出token数远超标准CLIP模型的77 token上限。此外,数据生成需在Google Colab环境下,利用三台并行RTX 6000 Pro Blackwell GPU耗时50小时进行分批推理,最后还要经过严格的模式验证与接地性打分方可筛选出高质量训练样本。
常用场景
经典使用场景
cc-task1-json数据集为跨模态理解领域提供了结构化的文本-图像映射资源。它基于Conceptual Captions语料库,通过微调后的Qwen3.5-0.8B模型将原始英文图像描述转化为包含主体、动作、场景及情感等多维信息的JSON格式。该数据集广泛应用于训练能够精准解析图像语义的文本生成模型,尤其在需要从自然语言中提取结构化主题要素的任务中表现突出。其经典用法是作为指令微调与工具调用能力的训练数据,帮助模型掌握从非结构化描述到结构化参数输出的转换能力,进而提升对复杂视觉场景的抽象理解水平。
解决学术问题
该数据集有效解决了视觉语言模型中语义结构化提取不足的学术难题。传统图像描述数据集多停留在平面化的文本表述,缺乏对场景要素的标准化分解。cc-task1-json通过引入可验证的结构化标签,为研究模型在零样本条件下的语义解析能力、工具调用执行效果及多任务联合推理提供了可靠基准。其意义在于推动模型从单纯描述转向具备逻辑拆解与参数化输出的高级认知范式,为构建可解释、可控制的视觉语言系统奠定了数据基础,显著影响了多模态领域内关于知识蒸馏与能力迁移的研究方向。
衍生相关工作
该数据集衍生了一系列相关的重要工作,主要集中在对指令微调模型与结构化输出能力的深化研究。基于cc-task1-json,研究者构建了多版本的任务型LoRA适配器,如用于生成更精细场景标签的V2版本,以及用于多轮对话中工具调用链的扩展数据集。同时,该数据集催生了关于数据筛选策略的系统性探索,提出了基于grounded标签的过滤方法论,显著提升了训练样本的质量与多样性。其开创的从概念描述到结构化JSON的转换范式,也被后续工作迁移至视频理解、音频描述等领域,形成了跨模态结构化表征的研究脉络。
以上内容由遇见数据集搜集并总结生成


