YouTube-English
收藏Hugging Face2025-04-27 更新2025-04-28 收录
下载链接:
https://huggingface.co/datasets/OrcinusOrca/YouTube-English
下载链接
链接失效反馈官方服务:
资源简介:
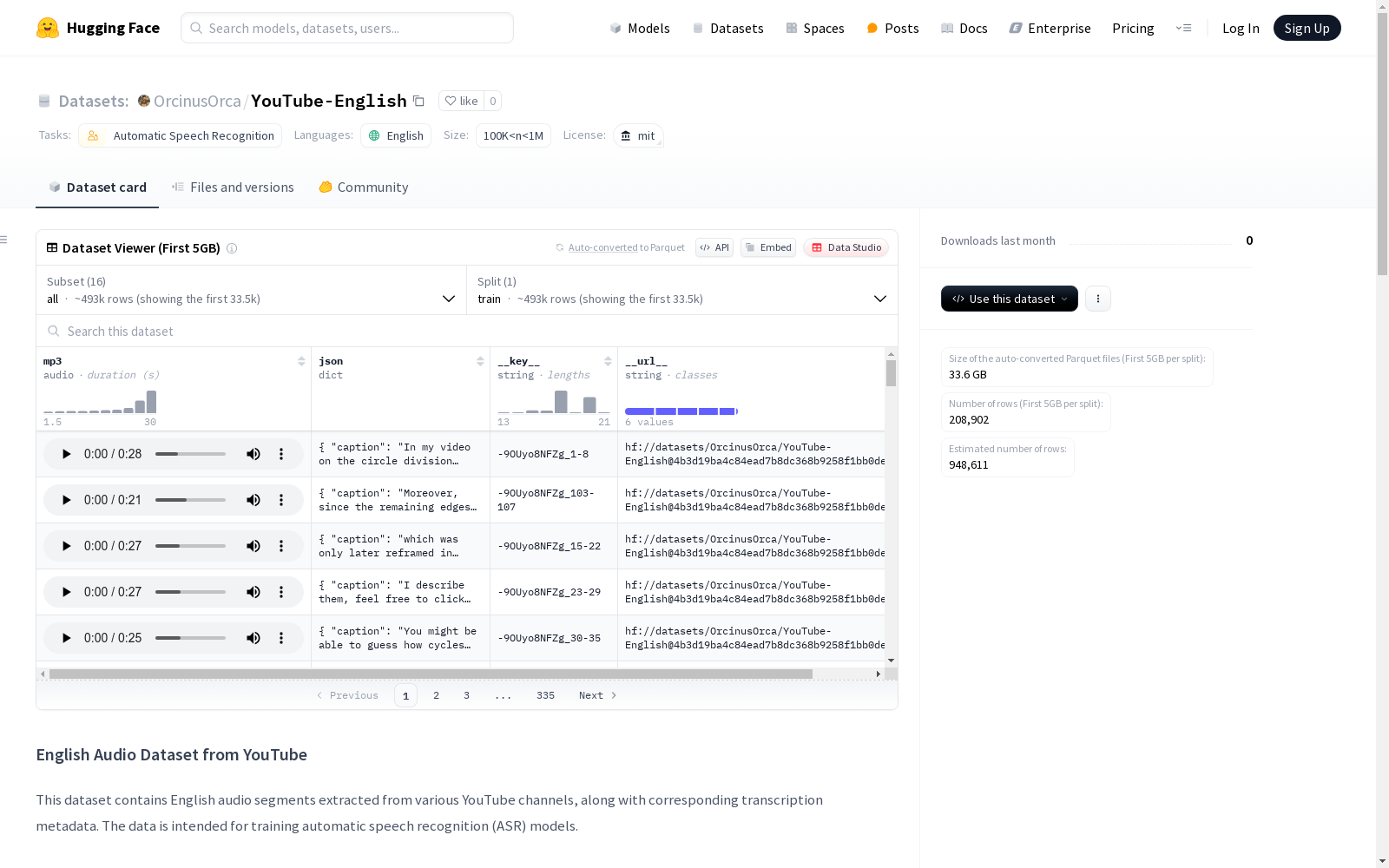
该数据集包含从各种YouTube频道提取的英语音频片段以及相应的转录元数据。数据用于训练自动语音识别(ASR)模型。数据来源于YouTube频道,处理过程包括下载、分割和保存音频及元数据。数据集总结部分详细列出了每个频道的视频数量、持续时间和占总数据集的百分比。
This dataset comprises English audio clips extracted from a variety of YouTube channels, alongside their corresponding transcription metadata. It is designed for training Automatic Speech Recognition (ASR) models. The data is sourced from YouTube channels, and the processing pipeline includes downloading, segmenting, and storing the audio content and metadata. The dataset summary section details the number of videos, total duration, and the percentage share of each channel relative to the entire dataset.
创建时间:
2025-04-27
原始信息汇总
数据集概述:YouTube英文音频数据集
基本信息
- 许可证: MIT
- 任务类别: 自动语音识别 (ASR)
- 语言: 英语 (en)
- 数据规模: 100K<n<1M
数据来源与处理
- 下载: 从选定YouTube频道下载音频 (
.m4a) 和英文字幕 (.srt),存储于data/{channel_id}/目录结构。 - 分割: 基于
.srt文件的时间信息分割音频文件:- 按SRT段分组,每组最大时长接近30秒。
- 使用
ffmpeg提取音频段并保存为16000 Hz采样率的.mp3文件。 - 每个段的元数据(包括频道/视频信息和字幕文本/时间)保存在对应的
.json文件中。
数据集结构
dataset/ └── {channel_id}/ # YouTube频道ID └── {video_id}/ # YouTube视频ID ├── {video_id}{group_name}.mp3 # 分割后的音频文件 ├── {video_id}{group_name}.json # 对应的元数据文件 └── ...
{group_name}: 表示段中包含的字幕索引(单个索引如1或多个索引范围如1-5)。
数据统计
| 频道 | 视频数量 | 时长(小时) | 占比 |
|---|---|---|---|
| 3blue1brown | 136 | 37.82 | 1.08% |
| boxofficemoviesscenes | 1626 | 153.06 | 4.38% |
| business | 887 | 187.80 | 5.38% |
| markrober | 97 | 21.77 | 0.62% |
| marvel | 763 | 35.17 | 1.01% |
| mitocw | 2844 | 1738.07 | 49.79% |
| mkbhd | 114 | 27.61 | 0.79% |
| msftmechanics | 732 | 131.52 | 3.77% |
| neoexplains | 35 | 8.06 | 0.23% |
| nvidia | 134 | 19.42 | 0.56% |
| quantasciencechannel | 93 | 13.60 | 0.39% |
| teded | 1768 | 145.53 | 4.17% |
| theinfographicsshow | 3402 | 827.06 | 23.69% |
| twominutepapers | 871 | 79.34 | 2.27% |
| veritasium | 291 | 64.96 | 1.86% |
| 总计 | 13793 | 3490.79 | 100.00% |
数据加载
使用Hugging Face datasets 库加载数据:
python
import os
from datasets import load_dataset
ds = load_dataset( "OrcinusOrca/YouTube-English", "all", # 或指定频道ID split="train", streaming=False, # 或True num_proc=os.cpu_count(), )
搜集汇总
数据集介绍
构建方式
YouTube-English数据集通过系统化的流程构建而成,其核心数据来源于精选的YouTube频道。原始音频文件(.m4a格式)及英文字幕(.srt格式)首先被下载并存储于按频道ID分类的目录结构中。基于字幕时间戳信息,采用ffmpeg工具对音频进行智能分段处理,确保每个片段时长接近30秒上限以适应Whisper模型需求。分段后的音频以16kHz采样率保存为MP3格式,同时生成包含视频元数据、字幕文本及时间信息的JSON文件,最终按频道-视频两层目录结构组织为TAR归档文件。
使用方法
通过Hugging Face datasets库可直接加载数据集,支持全量加载或按频道配置选择特定子集。用户可通过设置streaming参数实现流式或本地加载,利用num_proc参数启用多核并行处理以提升效率。典型应用场景包括:作为预训练语料库用于英语ASR模型开发,通过多领域数据增强模型泛化能力;或作为评估基准测试不同语音识别算法在复杂音频环境下的性能表现。数据加载后可直接访问音频文件及对应结构化元数据,便于端到端模型训练流程集成。
背景与挑战
背景概述
YouTube-English数据集是专为自动语音识别(ASR)模型训练而构建的大规模英语音频语料库,由多领域YouTube频道内容构成。该数据集由研究者OrcinusOrca团队于2023年通过系统化采集MIT OpenCourseWare、Veritasium等15个知名教育科普类频道的13,793个视频构建,总时长达到3,490小时,其中MIT开放式课程占比近50%。其核心价值在于通过真实场景下的多模态语音数据(包含精确时间戳的音频片段与对应字幕文本),解决了传统ASR训练数据中自然语音多样性不足的问题,为语音技术在教育、媒体等领域的应用提供了重要基础支撑。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,需处理YouTube视频中复杂的声学环境(如背景音乐、多人对话、非标准发音),这对ASR模型的噪声鲁棒性和上下文理解能力提出更高要求;在构建过程中,精确对齐可变比特率音频与自动生成字幕的时间轴存在技术难度,特别是处理视频中频繁出现的非语音片段(如静默间隔、视觉特效音)时需开发定制化的分段算法。此外,不同频道间音频质量与字幕准确度的显著差异(如TED-Ed专业字幕与用户生成内容的对比),要求数据清洗阶段建立多级质量控制机制。
常用场景
经典使用场景
在语音识别技术的研究中,YouTube-English数据集因其丰富的英语音频内容和准确的转录文本而成为训练自动语音识别(ASR)模型的理想选择。该数据集涵盖了多个领域的音频内容,包括教育、科技、商业和娱乐等,为研究者提供了多样化的语音样本。通过利用这些数据,研究者能够构建更加鲁棒和泛化能力强的ASR模型,从而提升语音识别系统在复杂环境下的表现。
解决学术问题
YouTube-English数据集解决了语音识别领域中数据稀缺和多样性不足的问题。传统的语音数据集往往局限于特定场景或口音,而该数据集通过整合来自不同领域和背景的音频内容,为研究者提供了更全面的语音样本。这不仅有助于提升模型的泛化能力,还为研究多语言、多口音和复杂背景下的语音识别问题提供了宝贵资源。
实际应用
在实际应用中,YouTube-English数据集被广泛用于开发商业化的语音识别系统,如智能助手、语音转文字工具和实时字幕生成系统。这些系统在教育、媒体和客户服务等领域发挥着重要作用。例如,教育机构可以利用该数据集开发的ASR模型,为在线课程提供实时字幕,提升学习体验。
数据集最近研究
最新研究方向
在自动语音识别(ASR)领域,YouTube-English数据集因其丰富的多领域英语音频内容成为研究热点。该数据集涵盖了教育、科技、商业、娱乐等多个主题,尤其以MIT开放课程和科普频道的长时音频为特色,为端到端语音识别模型的训练提供了高质量的语料。近期研究聚焦于利用该数据集探索跨领域语音识别鲁棒性提升,特别是在处理不同口音、专业术语和自发语音时的泛化能力。与此同时,结合Whisper等预训练模型进行微调,以优化长音频分割与转录的准确性,成为当前技术突破的关键方向。该数据集的多样性和规模也为多模态学习提供了可能,例如探索音频与文本信息的联合表征,进一步推动智能语音助手和教育技术应用的发展。
以上内容由遇见数据集搜集并总结生成


