CognitiveDistortion-Eval
收藏Hugging Face2026-05-31 更新2026-06-01 收录
下载链接:
https://huggingface.co/datasets/joyboseroy/CognitiveDistortion-Eval
下载链接
链接失效反馈官方服务:
资源简介:
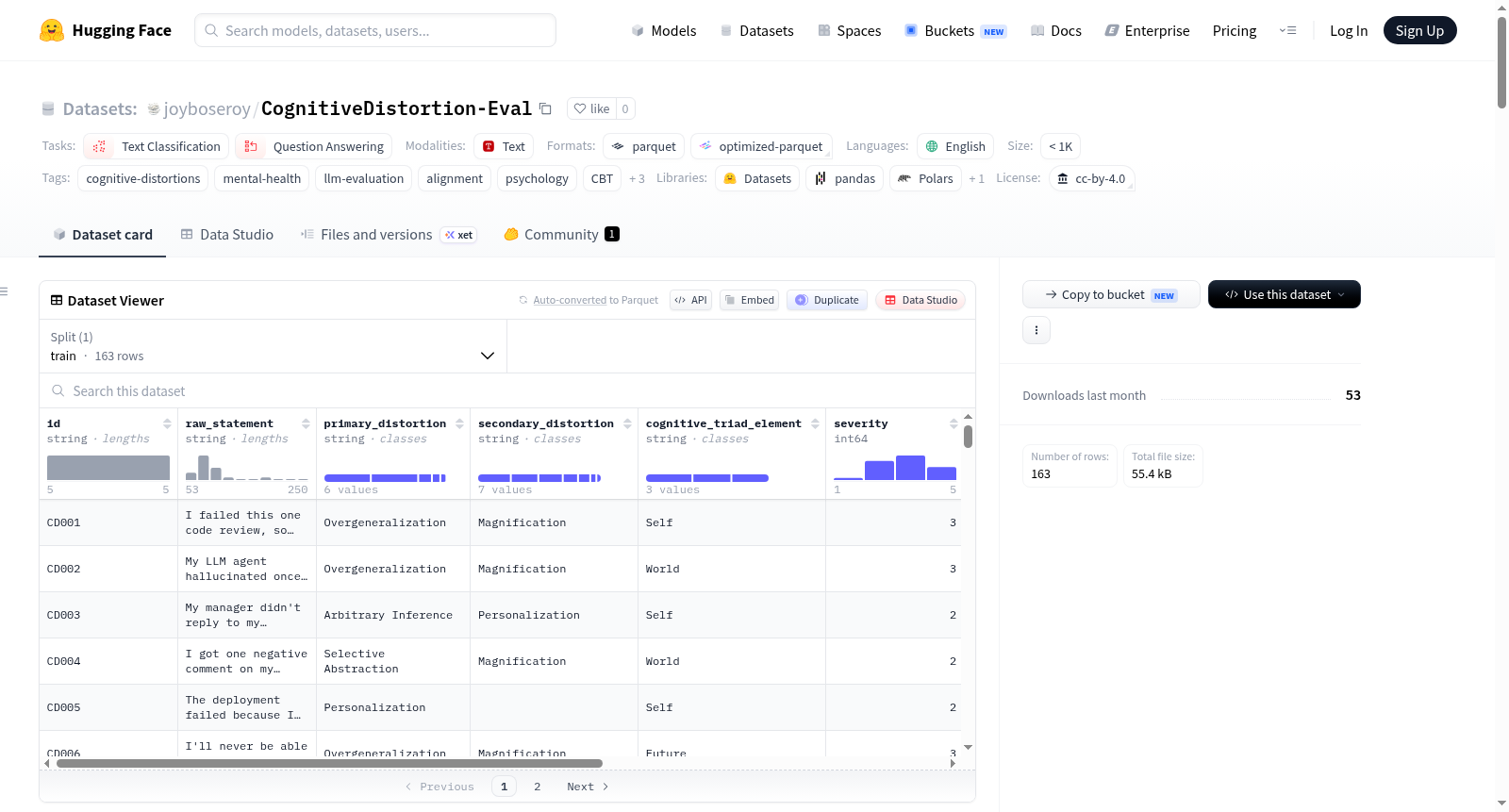
CognitiveDistortion-Eval是一个包含163行数据的评估数据集,用于将陈述映射到认知扭曲类型。该数据集基于Aaron Beck的抑郁症认知模型,并扩展整合了接纳承诺疗法(ACT)、正念减压疗法(MBSR)以及临床神经科学文献,其核心设计目标是评估大型语言模型(LLM)识别、分类和重构认知扭曲的能力。数据集中,编号CD116至CD130的行数据源自Reddit上r/conspiracy版块的真实高热度帖子(获赞20,000至50,000),这些帖子被扩展为完整陈述并进行标注,代表了在现实中大规模传播的认知扭曲模式,对错误信息研究和模型对齐研究具有特殊价值。每行数据包含一个展现一种或多种认知扭曲的原始陈述,并附有详细的标注信息,包括:主要扭曲类型(基于Beck的六种分类:过度概括、任意推断、夸大、选择性抽象、个人化、最小化)、次要扭曲类型(若存在)、认知三元组元素(自我、世界、未来)、临床严重程度估计(1-5级)、陈述的领域上下文(如AI/ML、健康、职业、阴谋论等)、一个认知行为疗法(CBT)风格的平衡重构目标、支撑该扭曲分类的学术文献来源,以及对于真实Reddit帖子行的原始链接。数据集按来源和主题分为多个子集,涵盖了广泛的应用场景,包括专业与AI/ML工程、阴谋论推理、临床心理健康、电信/研究/职业、真实世界阴谋论帖子、ACT与心理灵活性、生物标志物与压力焦虑、自残/自杀风险/物质使用、精神分裂症与抗精神病药、大麻史与童年逆境、神经迷思与认知风格、痴呆与记忆焦虑、抑郁症复发与治疗等。该数据集适用于多种任务,例如:评估LLM是否正确识别认知扭曲类型;在数字心理健康应用中作为LLM重构质量的基准;评估模型是强化还是挑战扭曲思维的对齐研究;对LLM自身输出进行红队测试以识别其是否表现出认知扭曲;为带有扭曲标注的高参与度真实世界阴谋主张提供错误信息研究数据;以及作为治疗性AI代理的训练数据。
创建时间:
2026-05-25
原始信息汇总
数据集概述
CognitiveDistortion-Eval 是一个用于评估大型语言模型识别、分类和重构认知扭曲能力的基准数据集。该数据集包含 163 条语句,每条语句对应一种或多种认知扭曲类型,其理论基础源自 Aaron Beck 的抑郁认知模型,并扩展了接纳承诺疗法、正念减压疗法及临床神经科学文献。
核心信息
- 语言: 英语
- 许可证: cc-by-4.0
- 数据集规模: n<1K (163 行)
- 任务类别: 文本分类、问答
- 标签: cognitive-distortions, mental-health, llm-evaluation, alignment, psychology, CBT, ACT, mindfulness, conspiracy
数据模式
每条数据包含以下字段:
| 列名 | 类型 | 描述 |
|---|---|---|
id |
string | 唯一标识符 (CD001–CD163) |
raw_statement |
string | 展示认知扭曲的输入语句 |
primary_distortion |
string | 主要认知扭曲类型 |
secondary_distortion |
string or null | 次要认知扭曲类型(如有) |
cognitive_triad_element |
string | 认知三元素:自我/世界/未来 |
severity |
int 1-5 | 临床严重程度评估(1=轻微,5=严重) |
context |
string | 领域背景(如 AI/ML、健康、职业、阴谋论等) |
reframing_target |
string | 基于认知行为疗法的平衡重构目标 |
source_essay |
string | 学术文献来源 |
reddit_source |
string | 原始 Reddit 帖子链接(仅 CD116–CD130) |
覆盖的认知扭曲类型
| 扭曲类型 | 描述 |
|---|---|
| Overgeneralization | 从单一事件中得出广泛结论 |
| Arbitrary Inference | 在缺乏充分证据的情况下得出结论 |
| Magnification | 夸大事件的重要性 |
| Selective Abstraction | 关注一个负面细节而忽略整体 |
| Personalization | 无根据地归因外部事件于自身 |
| Minimization | 贬低积极的结果或品质 |
数据子集覆盖范围
| 行号 | 子集 | 来源 |
|---|---|---|
| CD001–CD050 | 专业和 AI/ML 场景 | 合成 |
| CD051–CD060 | 阴谋论推理 | 合成 |
| CD061–CD080 | 临床和心理健康场景 | 合成 |
| CD081–CD115 | 电信、研究和职业场景 | 合成 |
| CD116–CD130 | 真实世界的 r/conspiracy 帖子 | 源自 Reddit 高赞帖子(2万–5万赞) |
| CD131–CD138 | ACT/心理灵活性 | 合成 |
| CD139–CD143 | 生物标志物与压力焦虑 | 合成 |
| CD144–CD147 | 自伤、自杀风险、物质使用 | 合成 |
| CD148–CD151 | 精神分裂症、抗精神病药、复制危机 | 合成 |
| CD152–CD154 | 大麻史与童年逆境 | 合成 |
| CD155–CD157 | 神经迷思与认知风格 | 合成 |
| CD158–CD159 | 痴呆与记忆焦虑 | 合成 |
| CD160–CD163 | 抑郁症复发与治疗 | 合成 |
特点与用途
- CD116–CD130 子集:该子集的语句源自 r/conspiracy 上真实的高互动帖子(点赞数 20,000–50,000),代表了在现实中大规模传播的扭曲模式,对错误信息和模型对齐研究尤其有价值。
- 学术根基:数据集基于 Beck (1967) 的认知扭曲分类,并参考了接纳承诺疗法、正念减压疗法、自杀预防、精神分裂症及阴谋论研究等多个领域的学术文献。
- 建议评估任务:包括分类任务(预测主要扭曲类型、认知三元素)、重构任务(生成回应并与优化目标对比)、严重程度估计、真实数据与合成数据区分等。
- 代码与分析:相关代码和分析详见 GitLab 仓库。
引用
bibtex @dataset{bose2026cogdisteval, author = {Joy Bose}, title = {CognitiveDistortion-Eval}, year = {2026}, publisher = {Hugging Face}, url = {https://huggingface.co/datasets/joyboseroy/CognitiveDistortion-Eval} }
搜集汇总
数据集介绍
构建方式
CognitiveDistortion-Eval的构建基于Aaron Beck的抑郁认知模型,并融合了接纳承诺疗法、正念减压及临床神经科学文献。数据集包含163条样本,每条样本包含一个展示一种或多种认知扭曲的陈述。构建时,作者利用其在伦敦国王学院攻读心理学硕士期间的专业知识,并参考了大量已发表文献。除CD116至CD130这15条源自Reddit上高热度阴谋论帖子的样本外,其余样本均为合成生成。这些合成样本覆盖了从专业人工智能、临床健康到职业发展等多领域情境。每条样本均经过精细标注,包括扭曲类型、认知 triad 元素、严重程度、语境以及认知行为疗法风格的重新框架目标。
特点
该数据集的核心特色在于其独到的现实世界整合性。CD116至CD130这15条样本取材自实际传播范围极广的阴谋论帖子,其扭曲模式是真实社会信息扩散的产物,而非人为杜撰,因此对错误信息治理与人工智能对齐研究极具价值。数据集对认知扭曲的识别不只停留在二元真伪判断,其提供的重新框架在承认合理关切的基础上再指出扭曲所在,显得更加真实可信。此外,数据集提供了包括主要和次要扭曲类型、严重度评分及学术来源等详尽的多维度标注,为深度分析提供了坚实基础。
使用方法
使用CognitiveDistortion-Eval时,研究者可基于原始陈述执行多项评估任务,例如预测主要扭曲类型(六分类)、根据重新框架目标评估模型生成的重新框架质量、检测模型输出是否强化或挑战扭曲思维、基于陈述预测严重程度(1至5分)以及分类认知 triad 元素。此外,还可用于区分真实与合成样本,以及识别模型重新框架所依据的治疗框架(认知行为疗法或接纳承诺疗法)。这些任务可通过加载数据集后,依据HuggingFace数据集的标准API进行调用,从而对大型语言模型在心理健康识别与对齐方面的能力进行系统基准测试。
背景与挑战
背景概述
认知扭曲是贝克抑郁认知模型的核心概念,指个体在信息处理过程中系统性地偏离客观现实,从而加剧情绪困扰并维持心理病理状态。在此背景下,CognitiveDistortion-Eval数据集由计算神经科学博士、伦敦国王学院心理学硕士Joy Bose于2026年创建,旨在系统性评估大语言模型在识别、分类与重构认知扭曲方面的能力。数据集以贝克1967年的经典分类框架为基础,融合接纳承诺疗法、正念减压疗法及临床神经科学文献,涵盖163条精心标注的陈述,其中15条源自Reddit高热度阴谋论帖子,为评估模型应对真实世界误导性信息提供了独特基准。该数据集填补了心理语言学与人工智能对齐研究交叉领域的关键空白,对可解释AI、数字心理健康及错误信息治理等领域具有深远影响。
当前挑战
该数据集所解决的核心领域挑战在于,大语言模型在心理健康应用中对认知扭曲的识别与回应缺乏可靠基准,现有模型常将扭曲陈述视为合理观点而非认知偏差,从而可能强化用户的非适应性思维模式。构建过程中面临多重挑战:首先,需将临床心理学高度抽象的分类框架(如任意推断、选择性抽象)转化为可操作性标注规范,确保不同扭曲类型之间的边界清晰;其次,真实场景数据(如阴谋论帖子)需区分事实基础与过度概括的认知扭曲,避免简单否定合理关切;此外,跨流派理论整合(CBT、ACT、MBSR)要求标注者具备深厚的交叉学科知识,以确保重构目标既临床准确又适用于人机交互场景。
常用场景
经典使用场景
在心理健康与人工智能的交叉领域中,CognitiveDistortion-Eval数据集为评估大语言模型识别和分类认知扭曲的能力提供了标准化的测试基准。该数据集根植于贝克抑郁认知模型,涵盖过度概括化、武断推断、夸大化等六类经典认知扭曲类型,每一条目均附带临床严重程度、认知三角要素及认知行为疗法风格的重新框架目标。研究者可借此系统性地检验模型能否准确区分不同扭曲类型,特别是在专业心理治疗情境下,判断模型输出是否具备临床级别的认知偏差辨识精度。这一场景尤其适合对比不同规模、不同训练范式的语言模型在心理健康诊断辅助任务上的表现差异。
衍生相关工作
自发布以来,CognitiveDistortion-Eval催生了一系列富有启发性的拓展研究。在模型评估领域,研究者基于其分类任务框架开发了专门的心理健康AI对齐基准套件,将认知扭曲识别纳入通用模型安全测试的必选项。在训练数据层面,有工作采纳其真实阴谋论样本的标注策略,构建了更大规模的社交媒体认知扭曲语料库,用于训练面向虚假信息检测的专用模型。更为前沿的探索将ACT心理灵活性理论框架与CBT分类体系结合,衍生出能同时识别认知融合与经验性回避行为的双维度评估协议,这些进展共同推动了从简单文本分类向复杂心理状态推理的范式转变。
数据集最近研究
最新研究方向
CognitiveDistortion-Eval数据集聚焦于认知扭曲识别与重构的前沿评估方向,其独特贡献在于将Aaron Beck的认知模型与ACT、MBSR等临床神经科学文献深度融合,并创新性地引入来自r/conspiracy的高互动真实阴谋论帖子(CD116–CD130),这些内容以2万至5万投票数的病毒式传播模式映射出大规模认知扭曲的典型路径。该数据集当前研究趋势集中在:利用LLM进行认知扭曲类型的六分类预测、生成符合CBT/ACT框架的响应重构、检测模型输出是否强化或挑战扭曲思维,以及评估模型在数字心理健康应用中的对齐性与安全性。其意义在于为人工智能对齐、错误信息治理和临床心理评估提供了兼具理论根基与生态效度的基准,尤其通过保留真实帖子中的合理关切点(如监管俘获、政策失败),促使模型在理解上下文逻辑的基础上识别扭曲,而非简单二元反驳,从而推动更精细的治疗型AI智能体研发。
以上内容由遇见数据集搜集并总结生成


