akjindal53244/Arithmo-Data
收藏Hugging Face2024-01-26 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/akjindal53244/Arithmo-Data
下载链接
链接失效反馈官方服务:
资源简介:
---
tags:
- math
- math-qa
configs:
- config_name: default
data_files:
- split: train
path: combined_MathInstruct_MetaMathQA_LilaOOD_train.json
- split: test
path: combined_MathInstruct_MetaMathQA_LilaOOD_test.json
license: apache-2.0
---
Arithmo dataset is prepared as combination of [MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA), [MathInstruct](https://huggingface.co/datasets/TIGER-Lab/MathInstruct), and [lila ood](https://huggingface.co/datasets/allenai/lila/viewer/ood). Refer to [Model Training Data](https://github.com/akjindal53244/Arithmo-Mistral-7B#model-training-data) section in Arithmo-Mistral-7B project GitHub page for more details.
### Support My Work
Building LLMs takes time and resources; if you find my work interesting, your support would be epic!
<a href="https://www.buymeacoffee.com/a_little_learner" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a>
<h2 id="References">References</h2>
```
@article{yu2023metamath,
title={MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models},
author={Yu, Longhui and Jiang, Weisen and Shi, Han and Yu, Jincheng and Liu, Zhengying and Zhang, Yu and Kwok, James T and Li, Zhenguo and Weller, Adrian and Liu, Weiyang},
journal={arXiv preprint arXiv:2309.12284},
year={2023}
}
@article{Yue2023mammoth,
title={MAmmoTH: Building math generalist models through hybrid instruction tuning},
author={Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen},
journal={arXiv preprint arXiv:2309.05653},
year={2023}
}
@article{mishra2022lila,
title={Lila: A unified benchmark for mathematical reasoning},
author={Swaroop Mishra, Matthew Finlayson, Pan Lu, Leonard Tang, Sean Welleck, Chitta Baral, Tanmay Rajpurohit, Oyvind Tafjord, Ashish Sabharwal, Peter Clark, and Ashwin Kalyan},
journal={arXiv preprint arXiv:2210.17517},
year={2022}
}
```
提供机构:
akjindal53244
原始信息汇总
数据集概述
标签
- math
- math-qa
配置
- 配置名称: default
- 数据文件:
- 训练集: combined_MathInstruct_MetaMathQA_LilaOOD_train.json
- 测试集: combined_MathInstruct_MetaMathQA_LilaOOD_test.json
- 数据文件:
许可证
- apache-2.0
数据集来源
- 该数据集是 MetaMathQA、MathInstruct 和 lila ood 的组合。
参考文献
- Yu, Longhui, et al. "MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models." arXiv preprint arXiv:2309.12284 (2023).
- Yue, Xiang, et al. "MAmmoTH: Building math generalist models through hybrid instruction tuning." arXiv preprint arXiv:2309.05653 (2023).
- Mishra, Swaroop, et al. "Lila: A unified benchmark for mathematical reasoning." arXiv preprint arXiv:2210.17517 (2022).
搜集汇总
数据集介绍
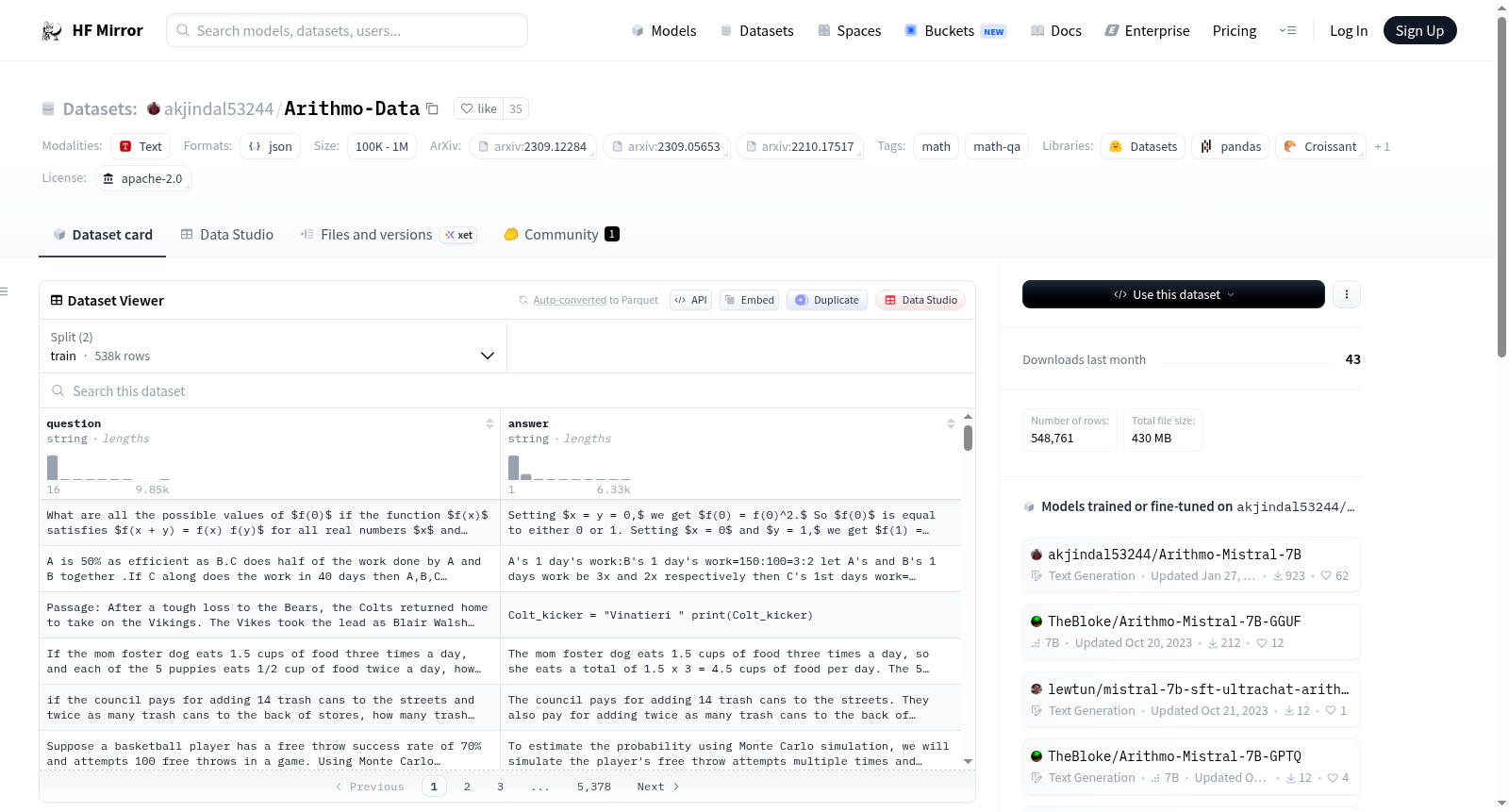
构建方式
在数学推理领域,高质量的指令数据对于提升大型语言模型的数值计算与逻辑推演能力至关重要。Arithmo数据集通过精心整合三个权威数学问答资源——MetaMathQA、MathInstruct以及Lila的分布外(OOD)子集,构建了一套综合性的训练与测试语料。其构建过程遵循严格的筛选与融合策略,将不同来源的数据按训练集与测试集划分,形成统一的JSON格式文件,确保了数据在数学问题覆盖广度与深度上的均衡性。
使用方法
研究人员可利用该数据集进行数学专用语言模型的指令调优与性能评估。典型使用流程包括加载指定的训练与测试文件,将其输入模型进行监督式微调或少量样本学习。在评估阶段,通过测试集衡量模型在复杂数学问题上的解答准确率与推理连贯性。数据集兼容主流机器学习框架,用户可参考相关GitHub项目中的训练数据章节,复现或扩展已有的数学模型训练流程,以推动数学人工智能的发展。
背景与挑战
背景概述
在人工智能领域,数学推理能力被视为衡量大型语言模型智能水平的关键指标之一。Arithmo-Data数据集由研究人员akjindal53244于2023年构建,其核心目标在于通过整合多个高质量数学问题资源,为模型训练提供丰富且多样化的数学指令数据。该数据集融合了MetaMathQA、MathInstruct以及Lila OOD三个知名数学基准,旨在解决数学问题求解、逻辑推理及泛化能力等核心研究问题,对推动数学推理模型的发展具有显著影响力。
当前挑战
Arithmo-Data数据集面临的挑战主要体现在两个方面:在领域问题层面,数学推理任务本身具有高度复杂性,涉及多步骤演算、符号操作及跨领域知识融合,要求模型不仅掌握基础算术,还需具备抽象思维和严谨的逻辑推导能力;在构建过程中,数据整合面临源数据集格式异构、问题质量参差不齐以及标注一致性维护等难题,需通过精细的预处理和标准化流程确保数据的可靠性与有效性。
常用场景
经典使用场景
在数学推理领域,Arithmo-Data数据集作为综合性数学问题集合,其经典使用场景在于为大型语言模型提供高质量的指令微调与评估基准。该数据集融合了MetaMathQA、MathInstruct和lila ood等多个权威数学推理资源,覆盖了从基础算术到复杂逻辑推导的多样化问题类型。研究者通常利用该数据集训练模型以提升其数学问题求解能力,特别是在多步骤推理和符号计算方面,为模型在数学领域的泛化性能提供了坚实的训练基础。
解决学术问题
Arithmo-Data数据集有效解决了数学推理研究中数据稀缺与多样性不足的学术难题。通过整合多个高质量数学数据集,它提供了丰富的、结构化的数学问题样本,有助于克服模型在复杂数学场景下的过拟合与泛化能力弱的问题。该数据集支持对模型数学推理能力的系统性评估,推动了如多模态数学理解、符号推理优化等前沿研究方向的发展,为构建通用数学推理模型奠定了数据基础。
实际应用
在实际应用中,Arithmo-Data数据集被广泛用于开发智能教育辅助系统和自动化数学问题求解工具。基于该数据集训练的模型能够协助学生解答数学题目、提供分步推理指导,并在科研与工程计算中辅助进行公式推导与逻辑验证。此外,该数据集还可应用于金融分析、数据科学等领域的定量推理任务,提升自动化系统的数学处理精度与效率。
数据集最近研究
最新研究方向
在数学推理领域,Arithmo数据集整合了MetaMathQA、MathInstruct与lila ood等优质资源,为大型语言模型的数学能力提升提供了关键训练基础。当前研究聚焦于通过混合指令调优策略,构建具备泛化能力的数学通用模型,以应对复杂多变的数学问题求解场景。前沿探索涉及利用自举方法生成高质量数学问题,增强模型在零样本或少样本情境下的推理性能,同时推动数学基准的统一化评估框架发展,旨在深化模型对数学概念的结构化理解与逻辑演绎能力。这一方向不仅呼应了人工智能在科学计算中的深化应用趋势,也为教育技术、自动化推理等跨学科热点注入了新的活力,具有显著的学术与实用价值。
以上内容由遇见数据集搜集并总结生成


