NepaliParliamentDSv2
收藏Hugging Face2025-04-27 更新2025-04-28 收录
下载链接:
https://huggingface.co/datasets/kiranpantha/NepaliParliamentDSv2
下载链接
链接失效反馈官方服务:
资源简介:
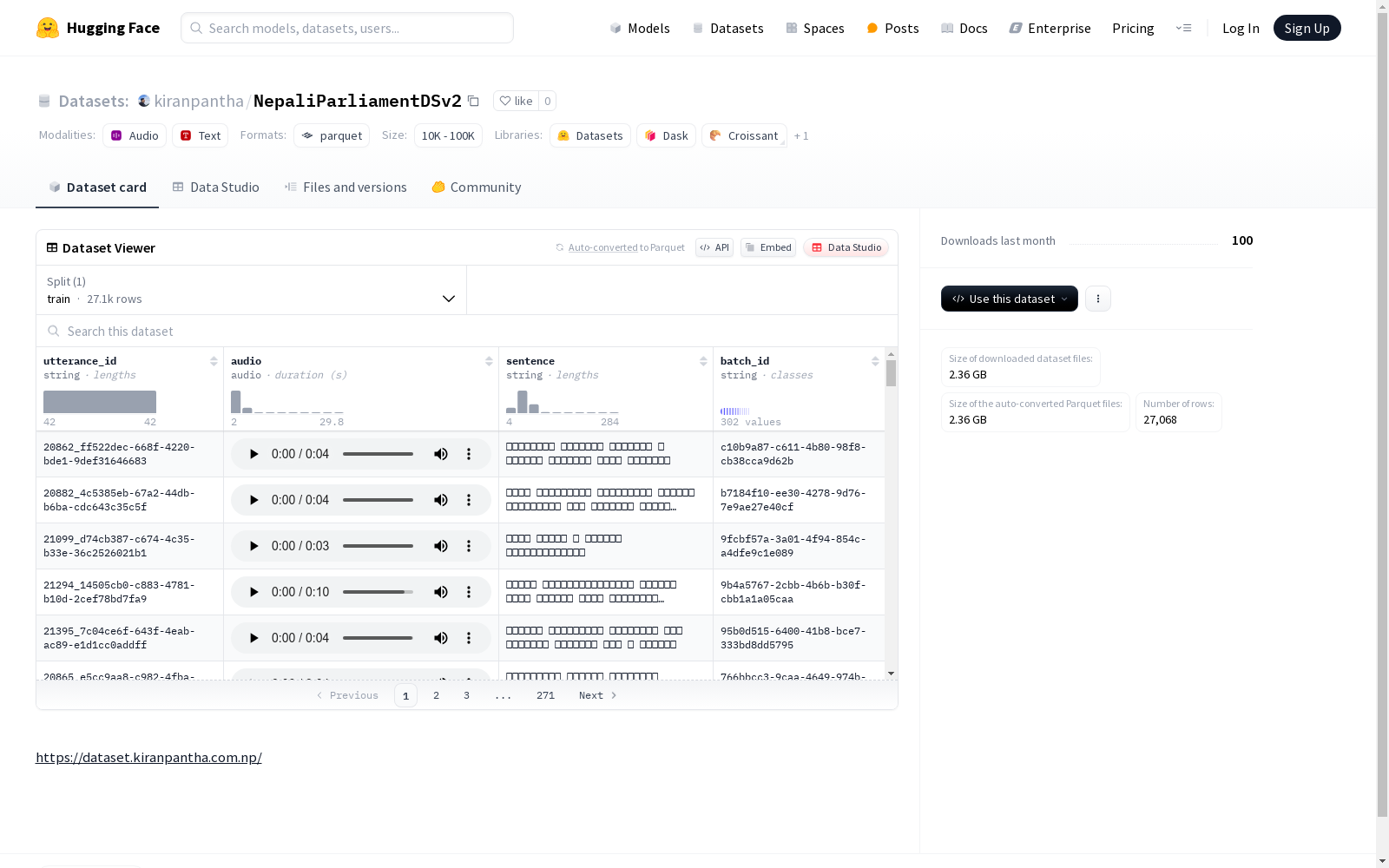
该数据集包含四个特征字段:utterance_id(字符串类型)、audio(音频类型)、sentence(字符串类型)和batch_id(字符串类型)。数据集分为训练集(train),共有约27068个示例,数据集总大小约为2.54GB。具体数据集的用途和背景在README文件中未提及。
创建时间:
2025-04-22
原始信息汇总
NepaliParliamentDSv2 数据集概述
数据集基本信息
- 数据集名称: NepaliParliamentDSv2
- 数据集地址: https://huggingface.co/datasets/kiranpantha/NepaliParliamentDSv2
- 相关网站: https://dataset.kiranpantha.com.np/
数据集特征
- utterance_id: 字符串类型,表示话语的唯一标识符。
- audio: 音频类型,包含音频数据。
- sentence: 字符串类型,包含与音频对应的句子文本。
- batch_id: 字符串类型,表示批次的唯一标识符。
数据集拆分
- train:
- 样本数量: 27,068
- 数据大小: 2,543,719,494.8760343 字节
- 下载大小: 2,361,877,672 字节
配置信息
- 默认配置:
- 数据文件路径:
data/train-*
- 数据文件路径:
搜集汇总
数据集介绍
构建方式
NepaliParliamentDSv2数据集作为尼泊尔议会语音研究的重要资源,其构建过程体现了严谨的学术规范。数据采集依托真实议会会议场景,通过专业录音设备获取高质量音频样本,每条数据均包含唯一话语ID、音频文件及对应文本转录。技术团队采用分层抽样策略确保数据代表性,最终形成包含27,068条样本的训练集,数据总量达2.54GB。原始音频经标准化降噪处理,文本转录由语言学专家校验,形成结构化对齐数据。
特点
该数据集最显著的特征在于其领域特异性,所有语料均来自尼泊尔议会实际议事场景,包含丰富的政治术语和方言变体。音频采样规格专业,支持声学模型训练所需的波形分析。每条数据配备精确到语句级的文本标注,且通过batch_id字段保留原始会话上下文信息。数据规模在低资源语言研究中颇具优势,27K样本量足以支撑端到端语音识别系统的训练需求,同时保持约2.36GB的合理下载体积。
使用方法
研究者可通过HuggingFace数据集库直接加载该资源,标准接口支持音频波形与文本的双流获取。典型应用场景包括构建尼泊尔语ASR系统,此时建议将音频转为梅尔频谱图作为输入特征。数据中的batch_id字段可用于会话连续性分析,而utterance_id则保障了样本追溯能力。对于跨语言研究,本数据集可与Common Voice等开源语料库联合使用,但需注意处理议会用语与日常用语的领域差异。官方提供的在线文档包含详细的预处理建议和基准模型性能指标。
背景与挑战
背景概述
NepaliParliamentDSv2数据集由尼泊尔研究者Kiran Pantha等人构建,旨在推动尼泊尔语语音识别与自然语言处理领域的研究。该数据集收录了尼泊尔议会会议中的大量语音片段及对应文本转录,时间跨度覆盖现代议会辩论的多个阶段。作为南亚低资源语言的重要语料库,其构建得到了尼泊尔本土学术机构的支持,填补了尼泊尔语在议会话语分析、语音技术开发等领域的空白。数据集采用音频-文本对齐的结构化设计,为研究议会话语特征、口音变异及语音识别模型优化提供了关键资源。
当前挑战
该数据集面临的核心挑战体现在两个方面:在领域问题层面,尼泊尔语作为黏着语具有复杂的形态变化,议会场景中即兴发言的语速波动、专业术语密度及发言人特有口音,对语音识别准确率构成显著挑战;在构建过程中,原始录音存在背景噪音干扰、多人同时发言的音频混叠问题,且议会术语体系缺乏标准化转写规范,需通过多轮人工校验确保文本转录质量。此外,低资源语言的标注人才稀缺导致数据清洗与标注成本居高不下。
常用场景
经典使用场景
在尼泊尔语语音识别领域,NepaliParliamentDSv2数据集凭借其丰富的议会发言录音和对应文本转录,成为训练端到端语音识别模型的理想选择。该数据集收录了超过2.7万条带标注的音频样本,为研究者提供了研究低资源语言声学建模的标准化基准。其独特的议会发言场景数据,特别适合分析正式场合下的语音特征和领域特定术语。
实际应用
在实际应用层面,该数据集支撑了尼泊尔议会会议的实时转录系统开发,显著提升了政府工作记录的效率。基于该数据训练的模型已被集成到公共服务平台,实现议会内容的自动归档和检索。在司法领域,相关技术辅助实现了庭审记录的自动化处理,为尼泊尔司法数字化进程提供了关键技术支撑。
衍生相关工作
围绕该数据集已产生多项标志性研究成果,包括KiranPantha团队开发的端到端尼泊尔语ASR系统,其创新性地采用混合CTC-Attention架构处理音素丰富的尼泊尔语。后续研究进一步拓展到说话人识别领域,通过分析议会发言特征构建了首个尼泊尔政治人物声纹数据库,为多媒体内容分析开辟了新方向。
以上内容由遇见数据集搜集并总结生成


