NOW Corpus
收藏arXiv2025-09-30 收录
下载链接:
https://www.corpusdata.org/now_corpus.asp
下载链接
链接失效反馈官方服务:
资源简介:
该数据集名为NOW,是现有最大的全文新闻文章语料库,它收集了来自20个英语国家的谷歌新闻中的新闻文章,内容涵盖了政治、体育、名人新闻等多个主题。此外,该数据集包含了来自23,000个媒体机构的新闻文章,并对其中12个国家及其配对国家的重要事件进行了手动标注。规模上,该数据集包含了与634,000篇文章相关的120万句句子。基于此数据集的任务是追踪新闻文章中各国之间的关系。
This dataset, named NOW, is the largest full-text news article corpus currently available. It collects news articles sourced from Google News across 20 English-speaking countries, covering a wide range of topics including politics, sports, celebrity news and others. Additionally, the dataset encompasses news articles from 23,000 media outlets, and has manually annotated important events for 12 countries and their paired counterparts. In terms of scale, the dataset contains 1.2 million sentences associated with 634,000 articles. The task built upon this dataset aims to track the relationships between countries as reflected in the included news articles.
提供机构:
NOW Corpus
搜集汇总
数据集介绍
背景与挑战
背景概述
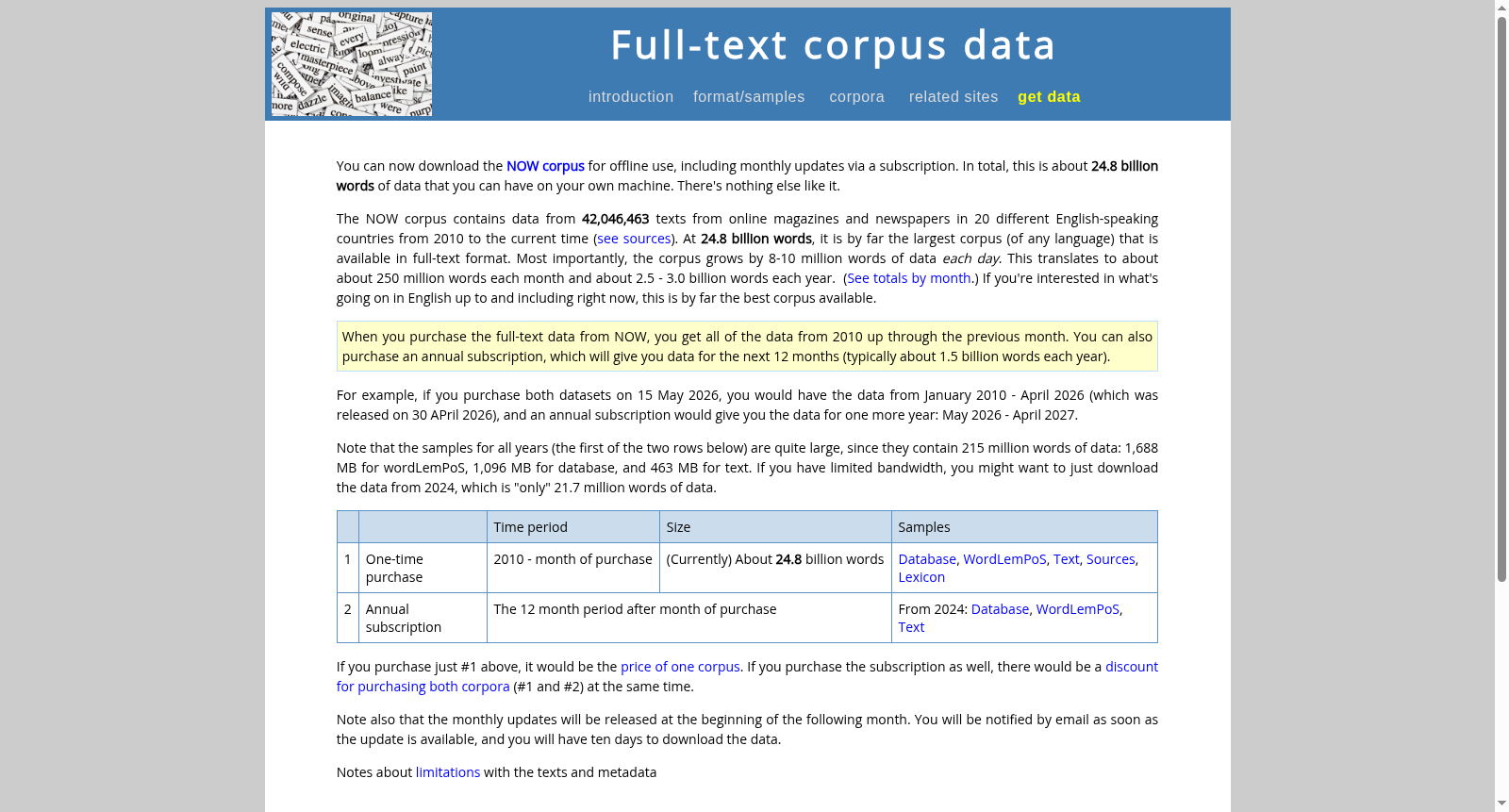
NOW Corpus是一个包含约248亿词的庞大语料库,涵盖2010年至今来自20个英语国家的42,046,463篇在线杂志和报纸文章,每日更新8-10百万词,提供多种格式的下载选项。
以上内容由遇见数据集搜集并总结生成


