K-SEED
收藏Hugging Face2024-12-05 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/NCSOFT/K-SEED
下载链接
链接失效反馈官方服务:
资源简介:
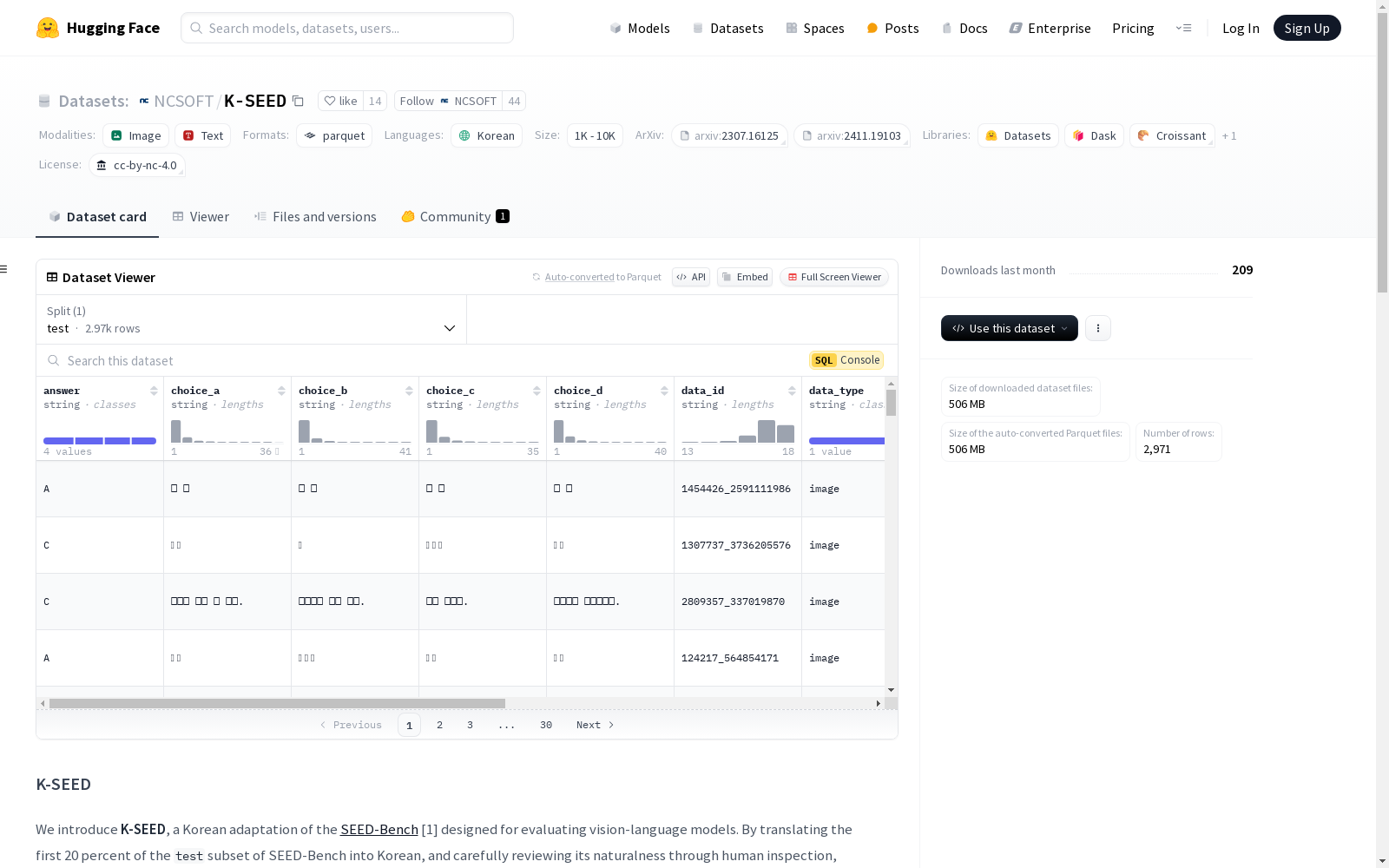
K-SEED是一个用于评估视觉语言模型的韩语数据集,它是SEED-Bench的韩语改编版本。数据集包含12个评估维度的问题,如场景理解、实例身份和实例属性,旨在全面评估模型在韩语中的表现。数据集包含一个测试集,包含2971个样本,每个样本包括问题、四个选项、答案、图像等信息。
创建时间:
2024-11-26
原始信息汇总
K-SEED 数据集概述
基本信息
- 语言: 韩语 (ko)
- 许可证: CC BY-NC 4.0
- 配置:
- 配置名称: default
- 数据文件:
- 分割: test
- 路径: data/test-*
数据集结构
- 特征:
- answer: string
- choice_a: string
- choice_b: string
- choice_c: string
- choice_d: string
- data_id: string
- data_type: string
- question: string
- question_id: int64
- question_type_id: int64
- image: image
- segment: string
分割信息
- 分割:
- 名称: test
- 字节数: 513264892.538
- 样本数: 2971
数据集大小
- 下载大小: 505959829
- 数据集大小: 513264892.538
数据集描述
K-SEED 是 SEED-Bench 的韩语改编版本,专门用于评估视觉语言模型。通过将 SEED-Bench 的 test 子集的前 20% 翻译成韩语,并通过人工检查其自然性,开发了一个专门针对韩语的鲁棒评估基准。K-SEED 包含跨越 12 个评估维度的问答,如场景理解、实例身份和实例属性,允许对韩语模型性能进行全面评估。
引用
如果使用 K-SEED 数据集,请引用以下内容: bibtex @misc{ju2024varcovisionexpandingfrontierskorean, title={VARCO-VISION: Expanding Frontiers in Korean Vision-Language Models}, author={Jeongho Ju and Daeyoung Kim and SunYoung Park and Youngjune Kim}, year={2024}, eprint={2411.19103}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2411.19103}, }
搜集汇总
数据集介绍
构建方式
K-SEED数据集的构建基于SEED-Bench的测试子集,通过将其中前20%的内容翻译为韩语,并经过人工审查以确保翻译的自然性和准确性。这一过程确保了数据集在韩语环境下的适用性和鲁棒性,使其能够有效地评估视觉语言模型在韩语中的表现。
使用方法
使用K-SEED数据集时,用户可以通过提供的推理提示模板进行模型评估。该模板包括图像、问题和四个选项,要求模型直接选择对应的选项字母作为答案。通过这种方式,用户可以系统地评估模型在不同视觉语言任务中的性能。
背景与挑战
背景概述
K-SEED数据集是由韩国研究人员基于SEED-Bench数据集开发的韩语适应版本,旨在评估视觉语言模型的性能。该数据集通过将SEED-Bench的测试子集的前20%翻译成韩语,并经过人工审查确保其自然性,从而构建了一个专门针对韩语的鲁棒评估基准。K-SEED涵盖了12个评估维度,如场景理解、实例身份和实例属性等,为韩语视觉语言模型的性能评估提供了全面的工具。该数据集的开发主要由VARCO-VISION团队负责,其研究成果在2024年的技术报告中详细阐述,对推动韩语视觉语言模型的发展具有重要意义。
当前挑战
K-SEED数据集在构建过程中面临的主要挑战包括:首先,如何确保从英语到韩语的翻译准确且自然,这需要大量的人工校对和审查;其次,如何在保持原数据集多样性的同时,适应韩语的语言特性,确保评估的全面性和有效性。此外,K-SEED还需应对视觉语言模型在多模态任务中的复杂性,如图像与文本的准确匹配和理解。这些挑战不仅影响了数据集的构建质量,也对模型的评估提出了更高的要求。
常用场景
经典使用场景
K-SEED数据集主要用于评估视觉-语言模型的性能,特别是在韩语环境下的表现。通过提供包含图像和多选题的测试集,K-SEED允许研究者对模型在场景理解、实例识别和属性分析等多个维度上的表现进行全面评估。这种多维度的评估方式使得K-SEED成为验证和改进视觉-语言模型在韩语处理能力上的重要工具。
解决学术问题
K-SEED数据集解决了在韩语环境下视觉-语言模型评估的不足问题。传统的视觉-语言评估基准多以英语为主,而K-SEED通过引入韩语翻译和本地化测试集,填补了这一领域的空白。这不仅有助于推动韩语视觉-语言模型的研究,还为跨语言视觉-语言模型的比较提供了新的视角和方法。
实际应用
K-SEED数据集在实际应用中具有广泛的前景,特别是在需要多语言支持的视觉-语言系统中。例如,在智能客服、教育辅助和自动驾驶等领域,K-SEED可以用于评估和优化模型在韩语环境下的表现,从而提高系统的准确性和用户体验。此外,K-SEED还可用于开发和测试多语言视觉-语言模型的迁移学习能力。
数据集最近研究
最新研究方向
近年来,视觉-语言模型在多模态任务中的表现日益受到关注,K-SEED数据集作为SEED-Bench的韩语适应版本,为韩国语言环境下的模型评估提供了新的基准。该数据集通过翻译SEED-Bench的部分测试集并进行人工校验,确保了韩语表达的自然性与准确性。K-SEED不仅涵盖了场景理解、实例身份识别等多个评估维度,还为韩国视觉-语言模型的性能评估提供了详尽的框架。随着VARCO-VISION技术报告的发布,K-SEED在推动韩国视觉-语言模型研究方面的作用愈发显著,尤其是在多模态大语言模型的评估与优化领域,K-SEED为研究人员提供了宝贵的资源和参考。
以上内容由遇见数据集搜集并总结生成


