---
language:
- en
license:
- mit
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
task_categories:
- token-classification
task_ids:
- named-entity-recognition
pretty_name: FIN
---
# Dataset Card for "tner/fin"
## Dataset Description
- **Repository:** [T-NER](https://github.com/asahi417/tner)
- **Paper:** [https://aclanthology.org/U15-1010.pdf](https://aclanthology.org/U15-1010.pdf)
- **Dataset:** FIN
- **Domain:** Financial News
- **Number of Entity:** 4
### Dataset Summary
FIN NER dataset formatted in a part of [TNER](https://github.com/asahi417/tner) project.
FIN dataset contains training (FIN5) and test (FIN3) only, so we randomly sample a half size of test instances from the training set to create validation set.
- Entity Types: `ORG`, `LOC`, `PER`, `MISC`
## Dataset Structure
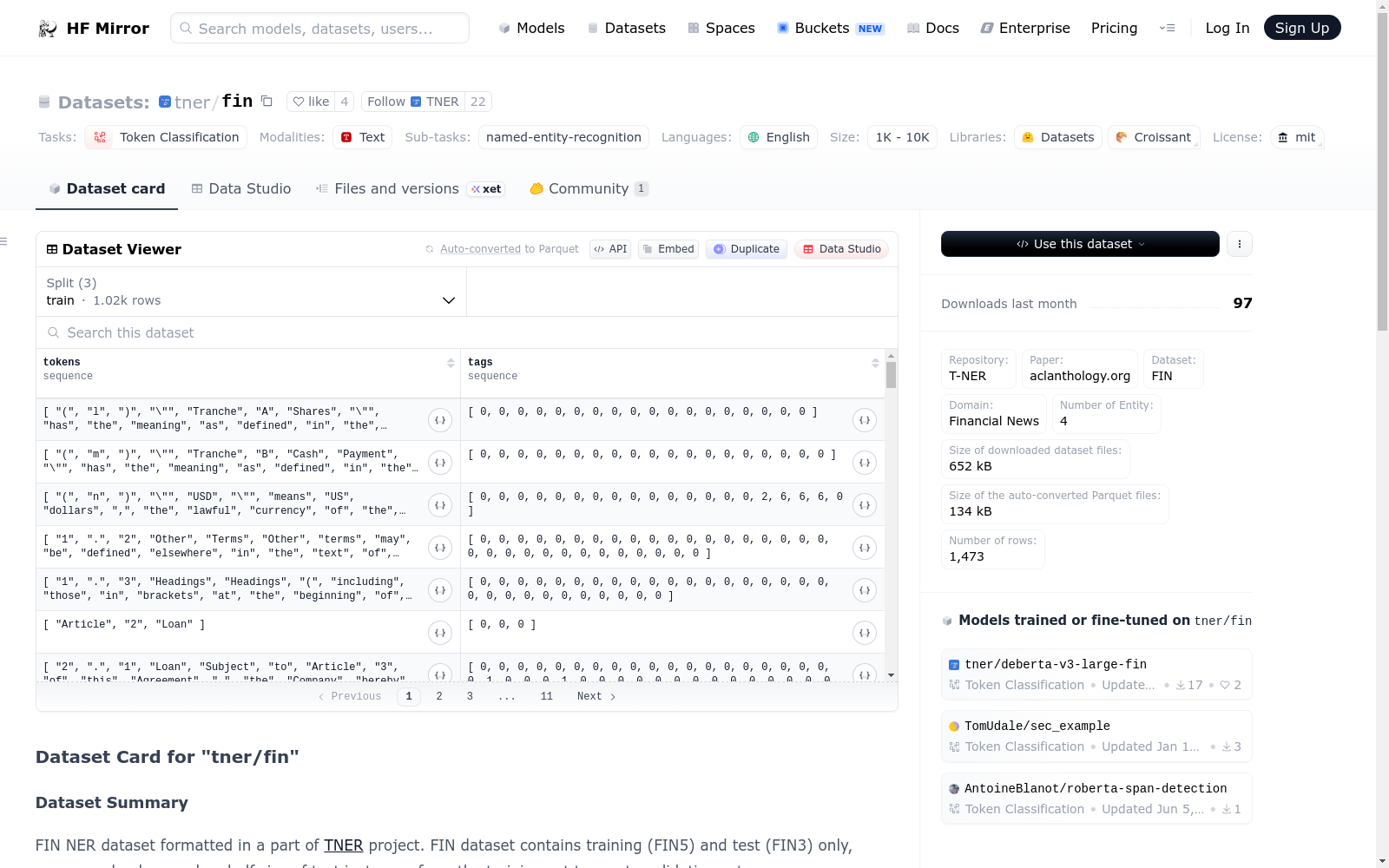
### Data Instances
An example of `train` looks as follows.
```
{
"tags": [0, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
"tokens": ["1", ".", "1", ".", "4", "Borrower", "engages", "in", "criminal", "conduct", "or", "is", "involved", "in", "criminal", "activities", ";"]
}
```
### Label ID
The label2id dictionary can be found at [here](https://huggingface.co/datasets/tner/fin/raw/main/dataset/label.json).
```python
{
"O": 0,
"B-PER": 1,
"B-LOC": 2,
"B-ORG": 3,
"B-MISC": 4,
"I-PER": 5,
"I-LOC": 6,
"I-ORG": 7,
"I-MISC": 8
}
```
### Data Splits
| name |train|validation|test|
|---------|----:|---------:|---:|
|fin |1014 | 303| 150|
### Citation Information
```
@inproceedings{salinas-alvarado-etal-2015-domain,
title = "Domain Adaption of Named Entity Recognition to Support Credit Risk Assessment",
author = "Salinas Alvarado, Julio Cesar and
Verspoor, Karin and
Baldwin, Timothy",
booktitle = "Proceedings of the Australasian Language Technology Association Workshop 2015",
month = dec,
year = "2015",
address = "Parramatta, Australia",
url = "https://aclanthology.org/U15-1010",
pages = "84--90",
}
```
---
语言:
- 英语
许可证:
- MIT协议
多语言属性:
- 单语言
样本量范围:
- 1000 < 样本数 < 10000
任务类别:
- Token分类(Token Classification)
任务子类型:
- 命名实体识别(Named Entity Recognition,NER)
简称:FIN
---
# "tner/fin" 数据集卡片
## 数据集说明
- **代码仓库**:[T-NER](https://github.com/asahi417/tner)
- **相关论文**:[https://aclanthology.org/U15-1010.pdf](https://aclanthology.org/U15-1010.pdf)
- **数据集名称**:FIN
- **应用领域**:金融新闻
- **实体类别数**:4
### 数据集概览
FIN命名实体识别(NER)数据集是[T-NER](https://github.com/asahi417/tner)项目的一部分,采用该项目的标准格式整理。原始FIN数据集仅包含训练集(FIN5)与测试集(FIN3),因此我们从训练集中随机采样半数样本作为验证集。
- **实体类型**:组织(Organization,ORG)、地点(Location,LOC)、人物(Person,PER)、其他实体(Miscellaneous,MISC)
## 数据集结构
### 数据样例
训练集的一条样例格式如下:
json
{
"tags": [0, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
"tokens": ["1", ".", "1", ".", "4", "Borrower", "engages", "in", "criminal", "conduct", "or", "is", "involved", "in", "criminal", "activities", ";"]
}
### 标签映射
标签与ID的对应字典可参见[此处](https://huggingface.co/datasets/tner/fin/raw/main/dataset/label.json):
python
{
"O": 0,
"B-PER": 1,
"B-LOC": 2,
"B-ORG": 3,
"B-MISC": 4,
"I-PER": 5,
"I-LOC": 6,
"I-ORG": 7,
"I-MISC": 8
}
其中,`O`表示非实体标记,`B-*`表示对应实体的起始位置,`I-*`表示对应实体的内部位置。
### 数据划分
各数据集划分的样本量如下:
| 数据集名称 | 训练集样本数 | 验证集样本数 | 测试集样本数 |
|----------|------------:|------------:|------------:|
| fin | 1014 | 303 | 150 |
### 引用信息
bibtex
@inproceedings{salinas-alvarado-etal-2015-domain,
title = "Domain Adaption of Named Entity Recognition to Support Credit Risk Assessment",
author = "Salinas Alvarado, Julio Cesar and
Verspoor, Karin and
Baldwin, Timothy",
booktitle = "Proceedings of the Australasian Language Technology Association Workshop 2015",
month = dec,
year = "2015",
address = "Parramatta, Australia",
url = "https://aclanthology.org/U15-1010",
pages = "84--90",
}
该论文标题可译为《面向信用风险评估的命名实体识别领域自适应》,会议名称可译为《2015年澳大利亚语言技术协会研讨会论文集》。