VideoPath-Instruct
收藏arXiv2025-05-07 更新2025-05-09 收录
下载链接:
https://github.com/trinhvg/VideoPath-LLaVA
下载链接
链接失效反馈官方服务:
资源简介:
VideoPath-Instruct是一个包含4278个视频和诊断相关思维链对的数据集,来源于YouTube上的教育性组织病理学视频。该数据集旨在模仿病理学家的自然诊断过程,包含单张切片图像、自动提取的关键帧视频片段和手动分割的视频病理图像三种不同的图像场景。虽然高质量数据对增强诊断推理至关重要,但其创建过程耗时且数据量有限。为了克服这一挑战,我们从现有的单图像指令数据集中迁移知识,以训练弱注释的关键帧提取视频,然后手动分割视频进行微调。VideoPath-LLaVA在病理学视频分析中建立了新的基准,并为未来支持临床决策的AI系统提供了有前景的基础。
提供机构:
韩国大学
创建时间:
2025-05-07
原始信息汇总
VideoPath-LLaVA 数据集概述
数据集基本信息
- 名称: VideoPath-LLaVA
- 领域: 病理学诊断推理
- 技术方向: 视频指令调优
数据集用途
- 用于病理学诊断推理的视频指令调优研究。
数据集特点
- 提供病理学诊断推理的视频数据。
- 包含指令调优的示例和结果。
相关资源
- 论文: VideoPath-LLaVA: Pathology Diagnostic Reasoning Through Video Instruction Tuning
- 项目页面: VideoPath-LLaVA Project Page
引用信息
bibtex @misc{vuong2025videopathllavapathologydiagnosticreasoning, title={VideoPath-LLaVA: Pathology Diagnostic Reasoning Through Video Instruction Tuning}, author={Trinh T. L. Vuong and Jin Tae Kwak}, year={2025}, eprint={2505.04192}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2505.04192}, }
搜集汇总
数据集介绍
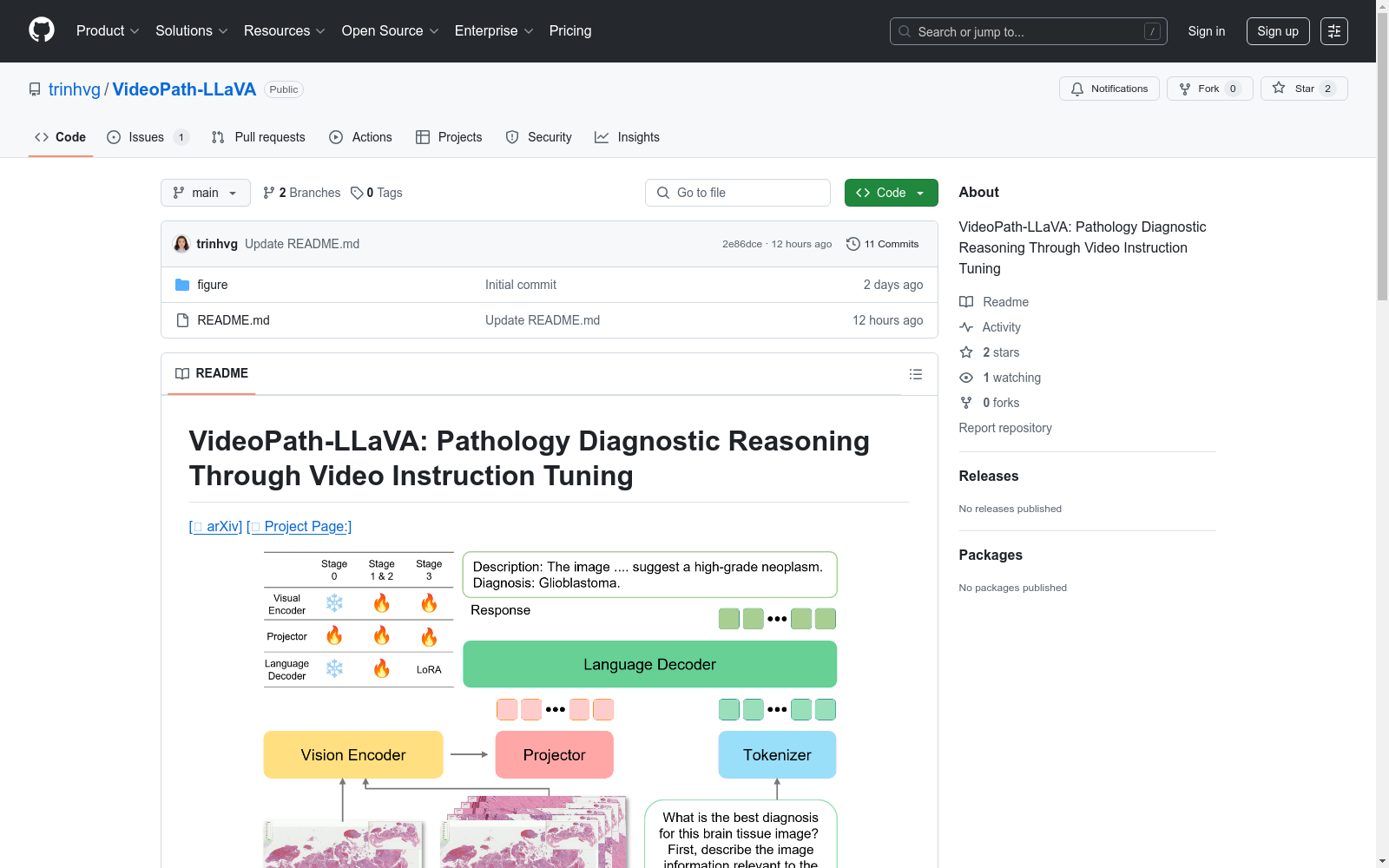
构建方式
VideoPath-Instruct数据集的构建过程体现了计算病理学领域对多模态数据整合的前沿探索。研究团队从5917个YouTube教育视频出发,通过创新的双阶段分割策略生成ClipPath(自动关键帧提取)和VideoPath(半监督手动分割)两个子集。视频内容经过Whisper语音识别系统转录后,采用基于YOLOv10的病理区域检测模型进行视觉数据清洗,去除无关人体区域和叠加文本。针对视频特点,研究团队设计了链式思维(CoT)提示工程,利用GPT-4o-mini模型生成包含病理特征描述和最终诊断的问答对,最终形成4278个高质量的视频-指令对。
使用方法
该数据集主要服务于计算病理学领域的多模态模型训练与评估。使用流程分为三个阶段:预训练阶段可结合Quilt-1M等图像-文本数据进行跨模态对齐;微调阶段建议采用论文提出的混合渐进策略,先静态图像后视频数据的顺序进行适应性训练;最终评估阶段需关注模型在视频理解、特征描述和诊断推理三个维度的表现。数据集提供的链式思维标注支持诊断可解释性分析,研究者可通过可视化中间推理步骤来验证模型决策逻辑。值得注意的是,使用时应遵循数据清洗流程处理新视频,以保持与训练数据分布的一致性。
背景与挑战
背景概述
VideoPath-Instruct数据集由韩国大学的Trinh Vuong和Jin Tae Kwak团队于2025年推出,是计算病理学领域首个专注于视频指令调优的多模态数据集。该数据集包含4278个从YouTube教育视频中提取的病理学视频及诊断相关的链式思维指令对,旨在模拟病理学家的自然诊断过程,通过生成详细的组织学描述并最终给出明确诊断,将视觉叙事与诊断推理相结合。VideoPath-Instruct的创建填补了病理学视频理解领域的空白,为开发支持临床决策的AI系统提供了重要基础。
当前挑战
VideoPath-Instruct数据集面临的核心挑战包括两方面:在领域问题层面,病理学诊断需要同时处理高倍镜下的细微结构和低倍镜下的全局信息,单一图像难以全面捕捉病理特征,而视频数据虽能提供丰富序列信息,但存在关键帧提取与诊断逻辑对齐的难题;在构建过程层面,高质量病理视频数据的标注耗时且专业性强,数据集规模受限,同时需解决视频中无关元素(如人物画面)的干扰以及文本信息泄露等问题,这些因素均增加了数据集构建的复杂度。
常用场景
经典使用场景
在计算病理学领域,VideoPath-Instruct数据集通过整合单张病理图像、自动关键帧提取的视频片段和人工分割的病理视频,模拟病理学家的自然诊断过程。其核心应用场景在于训练大型多模态模型(LMMs)进行病理视频分析,生成详细的组织学描述并最终得出诊断结论。该数据集特别适用于需要结合视觉叙事与诊断推理的研究,为病理学教育、临床决策支持系统提供了重要数据基础。
解决学术问题
VideoPath-Instruct解决了病理学诊断中单张图像信息不足的问题。高倍率图像缺乏全局结构信息,低倍率图像则丢失细节,而该数据集通过视频序列整合多尺度视觉信息,弥补了这一缺陷。其链式思维(CoT)标注方法进一步提升了模型的可解释性,为复杂病理诊断任务(如肿瘤分级、组织特征分析)提供了端到端的推理框架,推动了计算病理学从静态图像分析向动态视频理解的范式转变。
实际应用
该数据集的实际价值体现在临床辅助诊断系统的开发中。基于VideoPath-Instruct训练的模型可实时分析内窥镜或显微镜下的病理视频流,自动识别恶性肿瘤细胞核异型性、有丝分裂活动等关键特征。例如在卵巢癌诊断中,系统能准确区分浆液性癌亚型,并生成包含组织架构、细胞形态学特征的诊断报告,显著减轻病理医生的工作负荷,尤其适用于医疗资源匮乏地区的远程病理会诊。
数据集最近研究
最新研究方向
在计算病理学领域,VideoPath-Instruct数据集的推出标志着多模态模型在病理视频分析中的重大突破。该数据集通过整合单张病理图像、自动提取的关键帧剪辑和手动分割的病理视频,模拟病理学家的自然诊断过程,为AI辅助临床决策提供了新的研究范式。当前研究聚焦于如何利用链式思维(CoT)提示技术,从教育性病理视频中提取诊断推理过程,以增强模型的可解释性和诊断准确性。随着多模态大模型在医疗领域的深入应用,VideoPath-Instruct不仅推动了病理视频理解的技术边界,还为罕见病理的诊断和跨模态知识迁移提供了重要数据基础。
相关研究论文
- 1VideoPath-LLaVA: Pathology Diagnostic Reasoning Through Video Instruction Tuning韩国大学 · 2025年
以上内容由遇见数据集搜集并总结生成


