LONGVIDEOBENCH
收藏arXiv2024-07-23 更新2024-07-24 收录
下载链接:
https://longvideobench.github.io
下载链接
链接失效反馈官方服务:
资源简介:
LONGVIDEOBENCH是一个针对长时视频-语言交错理解的问题回答基准,包含3,763个不同长度的网络收集视频及其字幕,涵盖多种主题。数据集设计用于全面评估大型多模态模型在长期多模态理解上的能力。数据集包含6,678个人工标注的多项选择题,分为17个细粒度类别,旨在测试模型在长视频中的详细多模态信息检索和推理能力。数据集的应用领域包括电影、新闻、生活和知识,旨在解决长视频内容理解中的复杂问题。
LONGVIDEOBENCH is a question answering benchmark targeting long-form video-language interleaved understanding. It contains 3,763 web-collected videos with varying lengths and their corresponding subtitles, covering a wide range of topics. This benchmark is designed to comprehensively evaluate the long-term multimodal understanding capabilities of large multimodal models. It includes 6,678 manually annotated multiple-choice questions divided into 17 fine-grained categories, which aim to test the model's abilities in detailed multimodal information retrieval and reasoning within long videos. The dataset covers application domains such as film, news, daily life and knowledge, and is intended to address complex challenges in long-form video content understanding.
提供机构:
未提及
创建时间:
2024-07-23
搜集汇总
数据集介绍
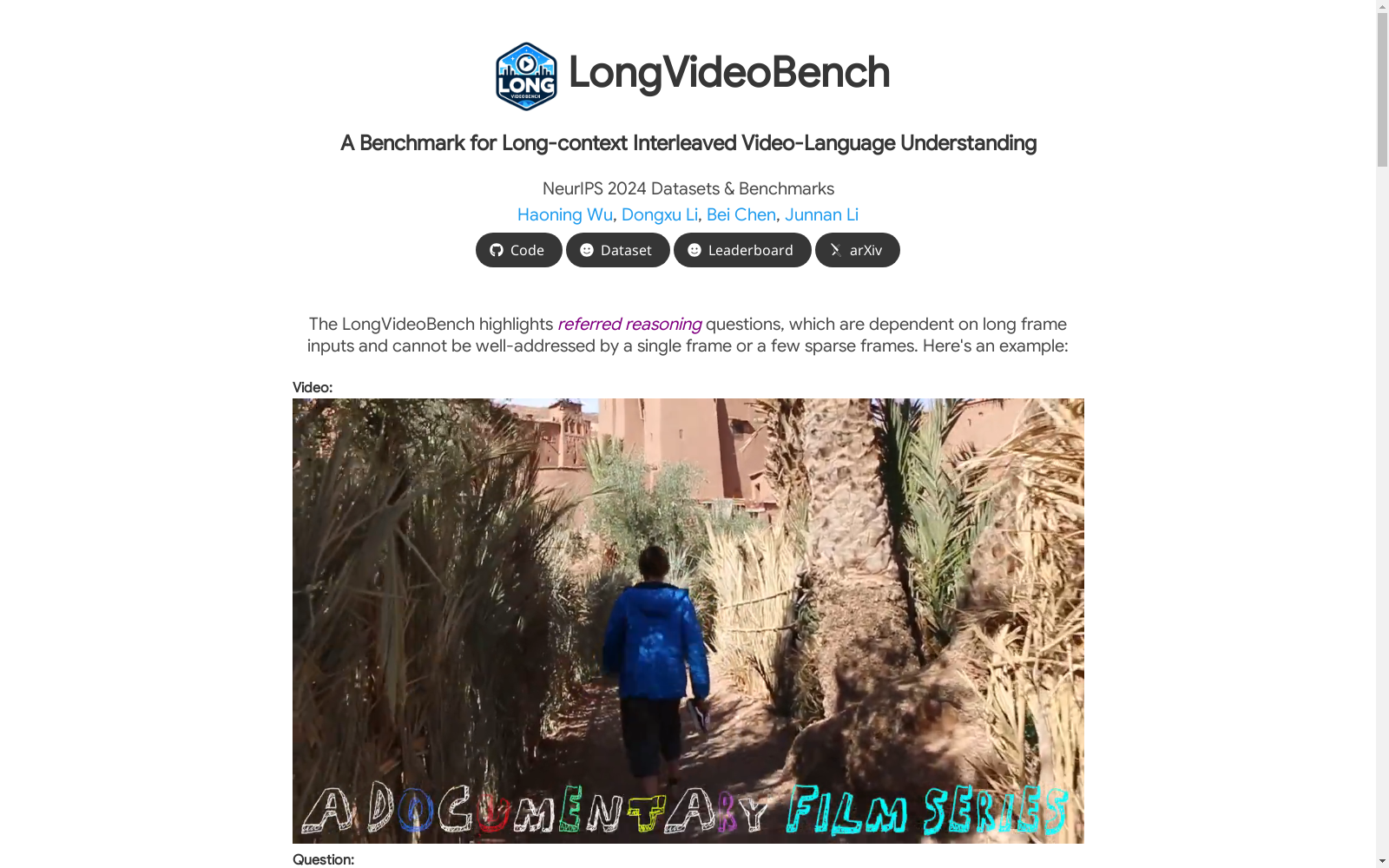
构建方式
LONGVIDEOBENCH数据集的构建旨在评估大型多模态模型(LMMs)在处理长达一小时的字幕视频方面的能力。数据集由3,763个不同长度的网络收集视频及其字幕组成,涵盖多样化的主题。为了全面评估LMMs在长期多模态理解方面的能力,LONGVIDEOBENCH引入了一种称为引用推理的新型视频问答任务。该任务包括6,678个人工标注的多项选择题,分为17个细粒度类别,要求模型根据引用查询来推理相关的视频细节。
特点
LONGVIDEOBENCH数据集的特点在于其视频-语言交错输入的长度可达一小时,这使得它成为评估LMMs在长期多模态理解方面的能力的一个有价值的基准。数据集包括来自不同主题的多样化视频,并附带原始或转录的字幕,挑战模型对长期交错的多模态输入的理解。此外,数据集包含了感知和关系问题,进一步细分为17个细粒度类别,要求模型进行复杂的推理。
使用方法
使用LONGVIDEOBENCH数据集时,首先需要将视频和字幕作为时间对齐的多模态序列输入到LMMs中。模型需要根据引用查询来识别特定的视频上下文,并推理出正确答案。数据集分为验证集和测试集,其中验证集的标签公开,用于模型开发和性能分析,而测试集的标签则保持隐藏,以避免模型过拟合。评估结果表明,即使是先进的LMMs在LONGVIDEOBENCH上也面临着重大挑战,这为未来多模态长上下文理解的研究提供了有价值的方向。
背景与挑战
背景概述
随着大型多模态模型(LMMs)处理输入的长度和丰富性不断增加,对于这些模型的评估标准也亟待更新。LONGVIDEOBENCH数据集的创建旨在填补这一空白,它是一个视频问答基准,特色是包含长达一小时的视频语言交错输入。该数据集由Haoning Wu, Dongxu Li, Bei Chen和Junnan Li于2024年7月提出,旨在全面评估LMMs在长期多模态理解方面的能力。LONGVIDEOBENCH包括3,763个主题多样、长度不一的网络收集视频及其字幕,设计用于评估LMMs在长输入上的详细多模态信息检索和推理能力。LONGVIDEOBENCH的引入为视频理解领域带来了新的研究视角,并对相关领域产生了深远的影响。
当前挑战
LONGVIDEOBENCH数据集面临的主要挑战包括:1) 从长输入中准确检索和推理详细的跨模态信息,这要求模型能够处理更多的帧,并有效地整合视频和字幕信息;2) 构建过程中遇到的挑战,包括视频和字幕的收集、处理以及人类注释的准确性。此外,LONGVIDEOBENCH还提出了一个新的视频问答任务,称为“指代推理”,它要求模型不仅能够定位相关的视频细节,还能够进行复杂的多模态推理。这些挑战对于现有的模型来说是一个巨大的挑战,因为它们往往在处理长视频时表现不佳,而且难以有效地整合文本信息来提高视频理解能力。
常用场景
经典使用场景
LONGVIDEOBENCH数据集最经典的使用场景是作为视频语言理解任务的评价基准。该数据集包含3,763个时长从几秒到一小时不等的网络收集视频及其字幕,涵盖了从日常生活到电影、新闻、生活和知识等多个主题,旨在全面评估大型多模态模型在长期多模态理解方面的能力。数据集中的问题分为感知和关系两个层次,要求模型能够从长视频输入中准确检索和推理详细的多模态信息。
解决学术问题
LONGVIDEOBENCH数据集解决了现有视频理解基准在长视频理解能力评估方面的不足。现有视频基准主要关注短视频,且存在单帧偏置的问题,即模型在处理更多帧的情况下表现并未得到显著提升。LONGVIDEOBENCH通过引入指代推理任务,要求模型处理更多帧,从而更准确地评估模型在长视频理解方面的能力。此外,LONGVIDEOBENCH还包括了感知和关系问题,进一步挑战模型在长视频中的细节提取和关系推理能力。
衍生相关工作
LONGVIDEOBENCH数据集的引入为长视频多模态理解领域的研究提供了新的方向和工具。基于LONGVIDEOBENCH,研究人员可以设计新的实验和评估方法,进一步探索和改进大型多模态模型在长视频理解方面的能力。此外,LONGVIDEOBENCH还可以与其他视频语言理解任务相结合,形成更全面的评估基准,为视频理解领域的研究提供更丰富的数据资源。
以上内容由遇见数据集搜集并总结生成


