Open-Sora-Plan-v1.2.0
收藏Hugging Face2024-07-25 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/LanguageBind/Open-Sora-Plan-v1.2.0
下载链接
链接失效反馈官方服务:
资源简介:
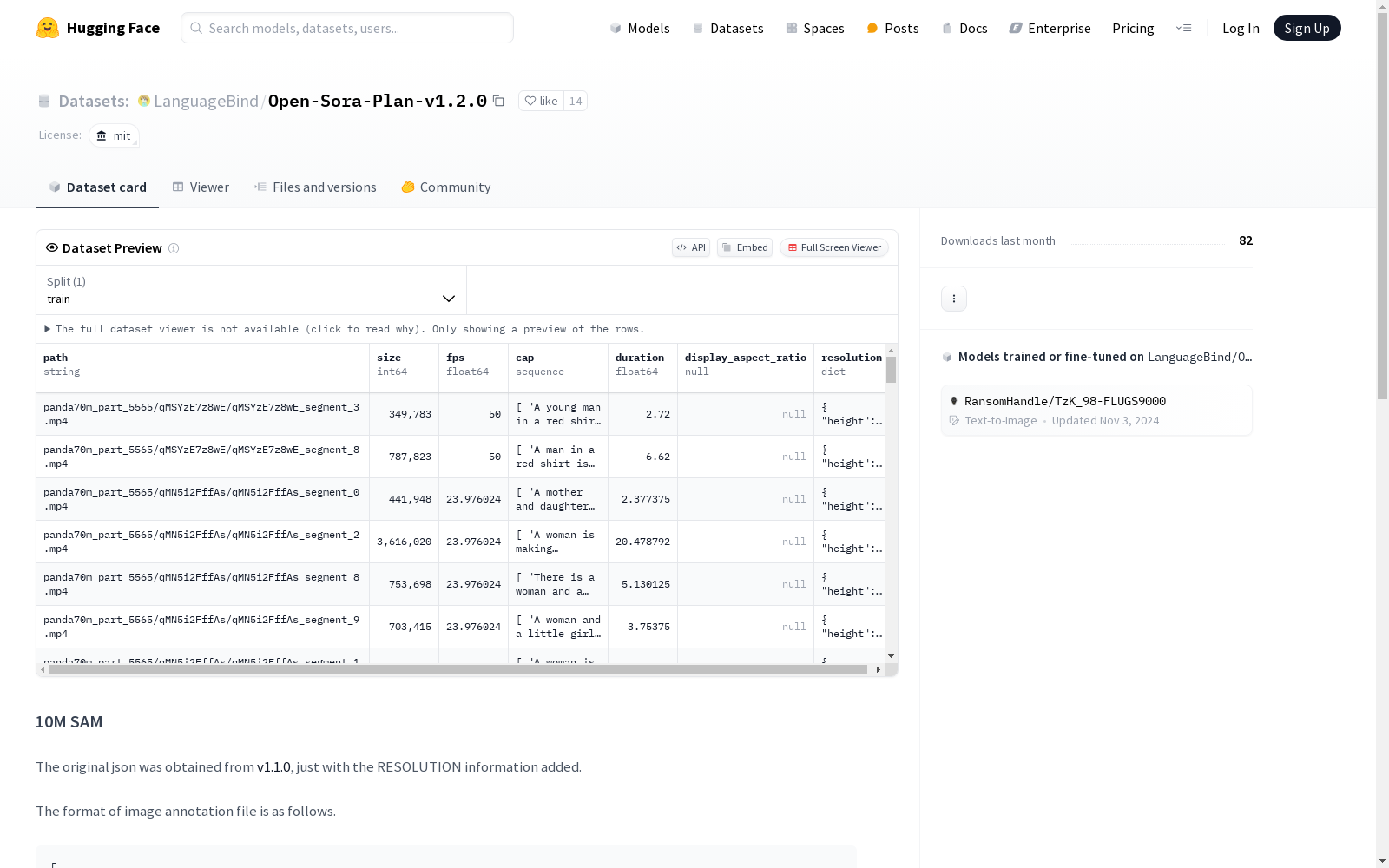
数据集包含三个部分:10M SAM、6M HQ Panda70m 和 100k HQ data。10M SAM 包含图像标注文件,格式为 JSON,每个条目包含图像路径、描述和分辨率信息。6M HQ Panda70m 包含视频标注文件,格式为 JSON,每个条目包含视频路径、描述、分辨率、帧率和持续时间信息。100k HQ data 是从 v1.1.0 版本中获取的原始数据,重新组织了描述。
The dataset consists of three parts: 10M SAM, 6M HQ Panda70m, and 100k HQ data. 10M SAM contains image annotation files in JSON format, where each entry includes image path, description, and resolution information. 6M HQ Panda70m contains video annotation files in JSON format, with each entry encompassing video path, description, resolution, frame rate, and duration information. 100k HQ data consists of raw data sourced from version v1.1.0, with its descriptions restructured.
创建时间:
2024-07-25
原始信息汇总
数据集概述
10M SAM
- 来源: 原始JSON文件来自v1.1.0,增加了分辨率信息。
- 格式: 图像标注文件格式如下: json [ { "path": "00168/001680102.jpg", "cap": [ "xxxxx." ], "resolution": { "height": 512, "width": 683 } }, ... ]
6M HQ Panda70m
-
格式: 视频标注文件格式如下: json [ { "path": "panda70m_part_5565/qLqjjDhhD5Q/qLqjjDhhD5Q_segment_0.mp4", "cap": [ "A man and a woman are sitting down on a news anchor talking to each other." ], "resolution": { "height": 720, "width": 1280 }, "fps": 29.97002997002997, "duration": 11.444767 }, ... ]
-
路径结构:
part_x/youtube_id/youtube_id_segment_i.mp4,其中part_x是自定义组织文件夹,youtube_id和segment_i可从原始标注文件获取。
100k HQ data
- 来源: 原始数据来自v1.1.0,重新组织了标注。
搜集汇总
数据集介绍
构建方式
Open-Sora-Plan-v1.2.0数据集的构建基于多个来源的标注数据整合与优化。首先,从v1.1.0版本中获取了原始的JSON文件,并在此基础上增加了分辨率信息。其次,数据集还整合了来自Panda-70M项目的视频标注数据,这些数据按照自定义的文件夹结构进行组织,并包含了视频的分辨率、帧率和时长等详细信息。最后,数据集还从v1.1.0版本中提取了高质量的100k数据,并对其中的标注进行了重新整理。
特点
Open-Sora-Plan-v1.2.0数据集的特点在于其多模态数据的丰富性与高质量标注。数据集包含了10M的图像标注数据和6M的视频标注数据,每一条数据都附带有详细的描述性文本和分辨率信息。视频数据还额外提供了帧率和时长等关键参数,便于用户进行更深入的分析与处理。此外,数据集中的100k高质量数据经过重新整理,确保了标注的一致性与准确性。
使用方法
使用Open-Sora-Plan-v1.2.0数据集时,用户可以通过解析JSON文件获取图像或视频的路径、标注文本以及分辨率等元数据。对于视频数据,用户还可以利用提供的帧率和时长信息进行时间序列分析或视频处理任务。数据集的组织结构灵活,用户可以根据需要自定义文件夹路径,便于在不同场景下进行数据加载与处理。此外,数据集的高质量标注为多模态学习任务提供了坚实的基础。
背景与挑战
背景概述
Open-Sora-Plan-v1.2.0数据集由LanguageBind团队于近期发布,旨在为多模态学习领域提供高质量的视频和图像标注数据。该数据集的核心研究问题在于如何通过大规模、多样化的标注数据提升模型在视频理解、图像描述生成等任务中的表现。数据集包含了10M SAM、6M HQ Panda70m和100k HQ三个子集,涵盖了从低分辨率到高分辨率的多种媒体格式。该数据集的发布为计算机视觉和自然语言处理领域的研究者提供了宝贵的资源,推动了多模态学习技术的发展。
当前挑战
Open-Sora-Plan-v1.2.0数据集在构建过程中面临多重挑战。首先,数据标注的准确性和一致性是关键问题,尤其是在视频描述生成任务中,如何确保标注内容与视频内容高度匹配是一个技术难点。其次,数据集的多样性和规模要求对数据采集和存储提出了高要求,尤其是在处理高分辨率视频时,存储和计算资源的消耗显著增加。此外,数据集的构建还需要解决版权和隐私问题,确保数据来源合法合规。这些挑战不仅影响了数据集的构建效率,也对后续模型训练和评估提出了更高的要求。
常用场景
经典使用场景
Open-Sora-Plan-v1.2.0数据集在计算机视觉领域中被广泛用于图像和视频的标注与分析。该数据集包含了丰富的图像和视频样本,每个样本都附带有详细的标注信息,如分辨率、帧率、时长等。这些标注信息为研究人员提供了高质量的数据基础,使得该数据集在图像识别、视频内容理解等任务中具有重要应用价值。
衍生相关工作
基于Open-Sora-Plan-v1.2.0数据集,许多经典的研究工作得以展开。例如,研究人员利用该数据集开发了高效的图像分割算法,提升了目标检测的准确性;同时,该数据集还被用于训练深度学习模型,推动了视频内容理解技术的发展。这些衍生工作不仅丰富了数据集的应用场景,还为相关领域的研究提供了新的思路。
数据集最近研究
最新研究方向
随着多模态学习在人工智能领域的快速发展,Open-Sora-Plan-v1.2.0数据集在图像与视频标注领域的研究方向逐渐聚焦于高分辨率数据的处理与多模态信息的融合。该数据集不仅提供了丰富的图像和视频标注信息,还引入了分辨率、帧率等关键参数,为研究者提供了更精细的数据支持。当前,前沿研究主要集中在如何利用这些高分辨率数据提升模型的视觉理解能力,尤其是在视频内容分析与生成任务中,结合文本描述与视觉信息的对齐问题成为热点。此外,数据集中的Panda-70M部分为视频理解与生成模型提供了大量高质量的视频片段,推动了视频生成与编辑技术的进步。Open-Sora-Plan-v1.2.0的发布为多模态学习领域注入了新的活力,进一步推动了视觉与语言模型的协同发展。
以上内容由遇见数据集搜集并总结生成


