IMDb-Best-250-Movies-Dataset
收藏Hugging Face2025-09-01 更新2025-09-02 收录
下载链接:
https://huggingface.co/datasets/gauthamnair2005/IMDb-Best-250-Movies-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
本数据集基于250部最佳电影,可用于训练或分析电影成功因素。
创建时间:
2025-08-26
原始信息汇总
IMDb最佳250部电影数据集概述
数据集来源
- 数据集由用户gauthamnair2005创建并共享
- 数据采集基于Dev Barma的爬虫代码,并由创建者进行部分修改
数据集用途
- 可用于电影成功因素的训练或分析
- 基于IMDb评选的最佳250部电影信息
数据内容
- 包含250部最佳电影的相关数据
搜集汇总
数据集介绍
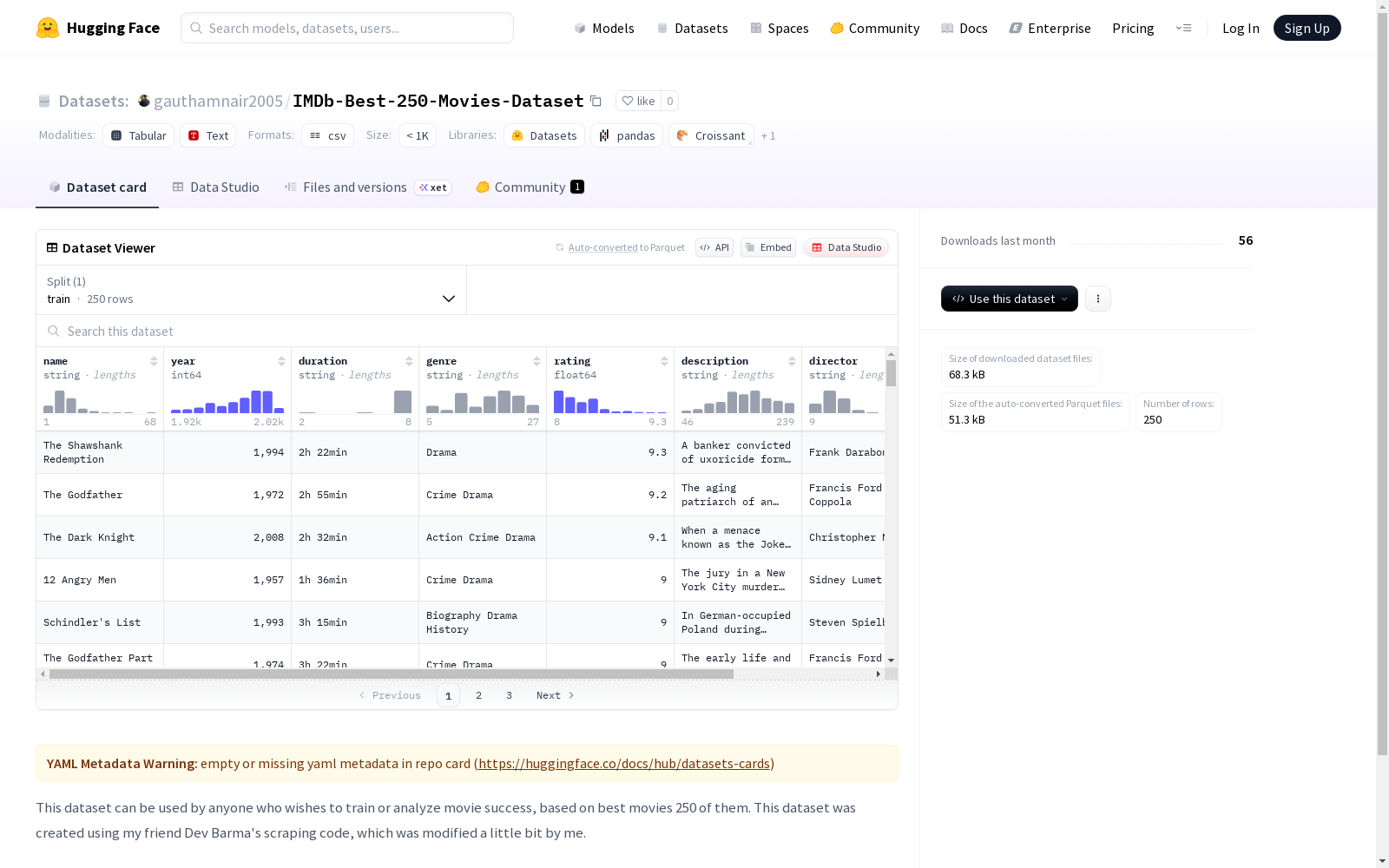
构建方式
在电影数据分析领域,IMDb-Best-250-Movies-Dataset的构建依托于网络爬虫技术。该数据集通过改进Dev Barma开发的原始爬虫代码,系统性地从互联网电影数据库(IMDb)中提取了排名前250部的优质电影信息,涵盖了影片的基本属性、评分数据及观众反馈等多维度结构化数据。
特点
该数据集的核心特点在于其聚焦于IMDb官方认证的顶级电影作品,具有高度的权威性和代表性。数据集不仅包含电影名称与评分,还整合了导演、演员、上映年份及用户评论数量等关键字段,为研究电影艺术成就与市场成功之间的关联提供了高质量、多变量的分析基础。
使用方法
研究人员可利用该数据集进行电影成功因素建模、观众偏好分析或推荐系统算法训练。典型应用包括通过机器学习方法预测影片评分,或结合自然语言处理技术挖掘评论情感倾向。数据以表格形式存储,支持Pandas或SQL直接加载,兼容常见数据分析框架如Scikit-learn和TensorFlow。
背景与挑战
背景概述
互联网电影数据库(IMDb)作为全球权威的电影信息平台,其发布的Top 250榜单自21世纪初便成为衡量影片艺术价值与观众认可度的重要指标。该数据集由独立研究者基于公开榜单构建,旨在为电影推荐系统、票房预测模型及文化传播研究提供结构化数据支持,推动了影视数据分析领域的实证研究发展。
当前挑战
该数据集需解决电影多维度评价指标融合的复杂性,包括用户评分与专业评论的权重平衡、时间因素对排名稳定性的影响等构建挑战。数据采集过程中需应对网页结构动态变更导致的爬取稳定性问题,且需处理非结构化文本转化为标准化数值数据的语义解析难题。
常用场景
经典使用场景
在电影产业与数据科学交叉领域,IMDb-Best-250-Movies-Dataset常被用于构建电影成功预测模型。研究者通过分析250部顶级影片的元数据特征,探索票房表现与影片要素之间的潜在关联,为电影行业的量化研究提供基准数据支撑。
衍生相关工作
基于该数据集衍生了多项标志性研究,包括基于深度学习的电影票房预测框架、多模态电影内容分析系统以及文化维度测量模型。这些工作不仅拓展了娱乐计算的研究边界,更为跨学科的数字人文研究提供了方法论借鉴。
数据集最近研究
最新研究方向
在电影推荐系统与商业智能分析领域,IMDb-Best-250-Movies-Dataset作为高质量电影评价的基准数据,正推动基于深度学习的多模态情感分析与票房预测模型的创新。结合自然语言处理技术,研究者利用该数据集挖掘影评文本与电影成功要素之间的隐含关联,探索观众情感倾向与电影艺术价值、市场表现之间的复杂映射关系。这类研究不仅深化了对电影社会文化影响力的理解,也为智能影视创作与个性化推荐系统提供了关键数据支撑,显著促进了影视工业与人工智能的交叉融合。
以上内容由遇见数据集搜集并总结生成


