ISIA Food-500
收藏arXiv2020-08-13 更新2024-06-21 收录
下载链接:
http://123.57.42.89/FoodComputing-Dataset/ISIA-Food500.html
下载链接
链接失效反馈官方服务:
资源简介:
ISIA Food-500是由中国科学院计算技术研究所智能信息处理重点实验室创建的大型食品识别数据集,包含500个类别和约40万张图像。该数据集通过从维基百科构建食品概念系统,并从多个搜索引擎爬取图像,确保了广泛覆盖和高度多样性。数据集的创建过程包括构建食品类别列表、收集食品图像、图像清洗和预处理以及扩展数据集。ISIA Food-500旨在推动大规模食品识别算法的发展,特别是在饮食管理、健康意识推荐和自助餐厅等应用领域。
ISIA Food-500 is a large-scale food recognition dataset developed by the Key Laboratory of Intelligent Information Processing, Institute of Computing Technology, Chinese Academy of Sciences. It contains 500 categories and approximately 400,000 images. The dataset was constructed by building a food concept system based on Wikipedia and crawling images from multiple search engines, which ensures its extensive coverage and high diversity. The dataset creation workflow includes establishing a food category list, collecting food images, performing image cleaning and preprocessing, as well as expanding the dataset. ISIA Food-500 aims to advance the development of large-scale food recognition algorithms, particularly in application domains such as dietary management, health-conscious recommendation systems, and self-service cafeterias.
提供机构:
中国科学院计算技术研究所智能信息处理重点实验室
创建时间:
2020-08-13
搜集汇总
数据集介绍
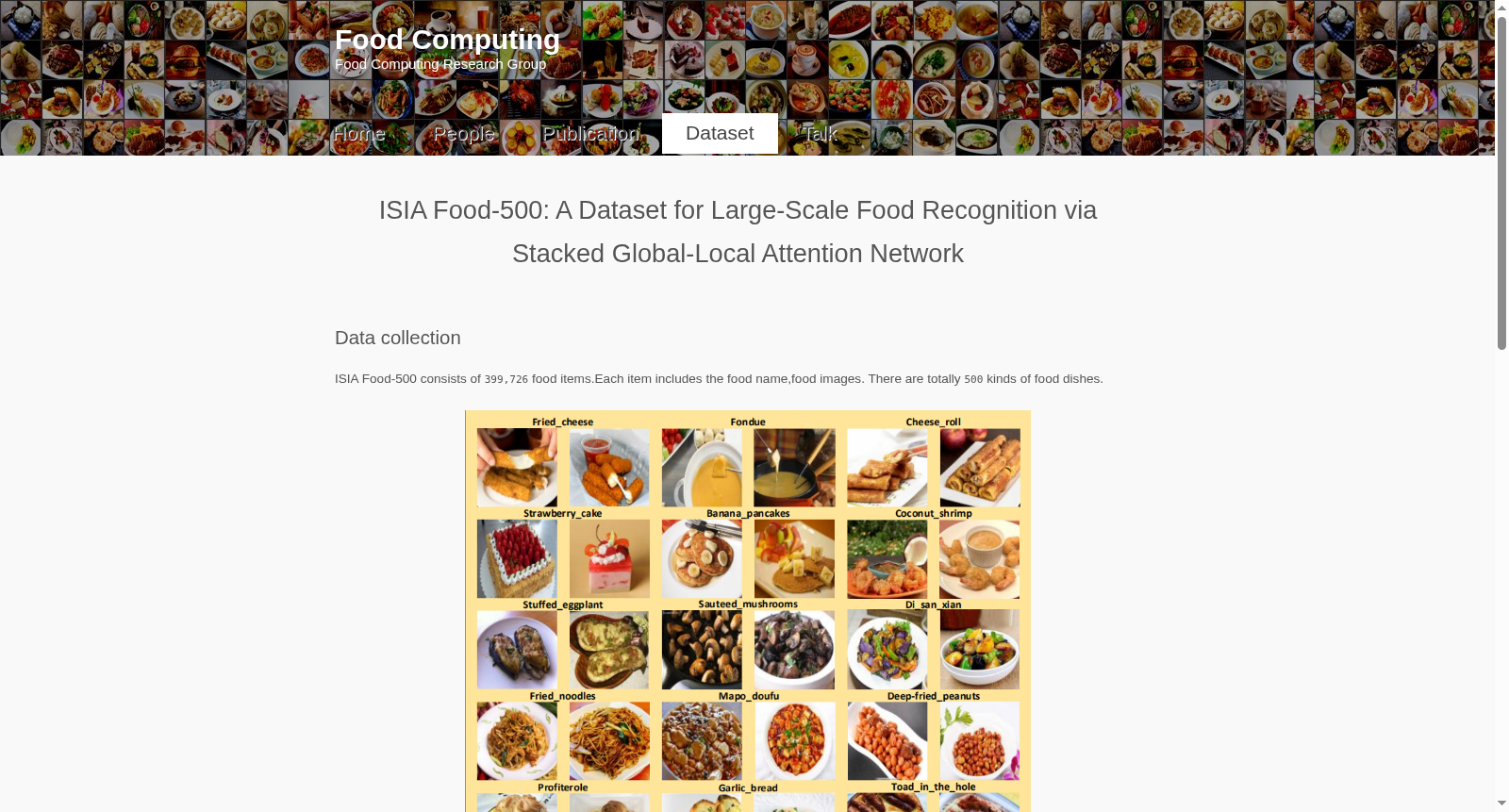
构建方式
在食品计算领域,大规模高质量数据集的构建是推动算法发展的关键。ISIA Food-500的构建遵循了系统化流程:首先,研究团队以维基百科的食品分类体系为基础,通过深度优先搜索算法构建了初始食品概念列表,经过冗余去除与同义词合并,最终筛选出覆盖广泛的食品类别。随后,利用多个搜索引擎进行图像爬取,并通过添加“food”等关键词确保图像相关性,结合哈希去重技术消除重复数据。在数据清洗阶段,采用自动与人工相结合的方式,通过训练食品/非食品二分类器过滤噪声图像,并由人工进行最终校验。为提升数据规模,团队还将类别名称翻译为多种语言进行二次采集,并整合了多个食谱分享网站的资源,最终形成了包含500个类别、近40万张图像的高质量数据集。
特点
ISIA Food-500作为食品识别领域的重要基准数据集,展现出多维度显著特征。其核心优势在于规模与覆盖广度:数据集包含399,726张图像,涵盖500个食品类别,平均每类约800张图像,在数据量与类别数量上均超越了同期主流数据集。多样性方面,该数据集融合了东西方多元饮食文化,覆盖肉类、谷物、蔬菜、水果等11个食品类型,具有高度的文化包容性与视觉差异性。此外,数据集构建过程中注重质量把控,通过多轮清洗确保了图像的纯净度与标注准确性,为模型训练提供了可靠基础。这些特征共同使其成为支持大规模食品识别算法研发的理想测试平台。
使用方法
该数据集适用于食品识别与细粒度分类任务的算法评估与模型训练。研究人员可将数据集按60%、10%、30%的比例划分为训练集、验证集与测试集,以此评估模型在复杂食品类别上的泛化能力。基于该数据集的特性,建议采用能够融合全局与局部特征的网络架构,例如论文中提出的堆叠全局-局部注意力网络(SGLANet),以同时捕捉食品的纹理形状等全局信息与食材区域等局部细节。在实验设置上,可采用中心裁剪的单图测试或十裁剪的多图测试策略,并以Top-1与Top-5准确率作为核心评估指标。此外,该数据集也可用于迁移学习研究,其预训练模型能够有效提升在其他食品数据集上的性能表现。
背景与挑战
背景概述
在多媒体计算领域,食品识别因其在饮食管理与自助餐厅等现实应用中的广泛潜力而备受关注。ISIA Food-500数据集由中国科学院计算技术研究所智能信息处理重点实验室与美团点评集团于2020年联合创建,旨在解决大规模食品识别算法发展中缺乏高质量基准数据的问题。该数据集包含来自维基百科的500个食品类别及近40万张图像,在类别覆盖范围与数据规模上均超越了ETH Food-101等现有流行基准,为食品计算领域提供了更全面的资源,推动了深度学习模型在复杂食品识别任务中的进步。
当前挑战
食品识别作为细粒度图像分类任务,面临类内差异大与类间差异小的核心挑战。具体而言,全球食品图像在整体外观、形状与纹理上存在显著类内变化,而不同类别间的判别性细节往往极为微妙,难以通过传统卷积神经网络充分捕捉。在数据集构建过程中,研究团队需应对数据收集与清洗的多重困难:从多个搜索引擎爬取图像时需保证高覆盖率与多样性,同时通过自动分类器与人工核查有效剔除非食品图像及重复样本,并借助多语言查询与食谱网站扩充数据规模,以确保最终数据集的质与量达到研究要求。
常用场景
经典使用场景
在食品计算领域,大规模图像识别任务常受限于数据集的规模与多样性。ISIA Food-500凭借其涵盖500个类别、近40万张图像的高质量数据,成为食品细粒度识别研究的经典基准。该数据集广泛应用于训练和评估深度神经网络模型,特别是在验证全局与局部特征融合方法的有效性方面,为研究者提供了丰富的实验平台,推动了食品识别算法在复杂场景下的性能提升。
实际应用
在实际应用层面,ISIA Food-500为智能餐饮管理、健康膳食监测和自助餐厅系统等场景提供了关键技术支撑。基于该数据集训练的模型能够准确识别多样化食品,辅助用户进行营养分析、卡路里估算,并提升餐饮服务的自动化水平。此外,其高泛化性能使得算法能够适应不同地域的饮食文化,为跨区域食品分析与推荐系统提供了可靠的技术保障。
衍生相关工作
围绕ISIA Food-500,学术界衍生了一系列经典研究工作,例如基于注意力机制的堆叠全局-局部网络(SGLANet)被提出作为该数据集的强基线模型。后续研究进一步探索了多尺度特征聚合、成分引导识别以及跨模态食品分析等方向,如IG-CMAN和MSMVFA等方法均在ISIA Food-500上进行了验证与优化。这些工作共同推动了食品识别领域向更精细、更鲁棒的技术方向发展。
以上内容由遇见数据集搜集并总结生成


