maharshipandya/spotify-tracks-dataset
收藏Hugging Face2023-12-01 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/maharshipandya/spotify-tracks-dataset
下载链接
链接失效反馈官方服务:
资源简介:
---
license: bsd
task_categories:
- feature-extraction
- tabular-classification
- tabular-regression
language:
- en
tags:
- music
- art
pretty_name: Spotify Tracks Dataset
size_categories:
- 100K<n<1M
---
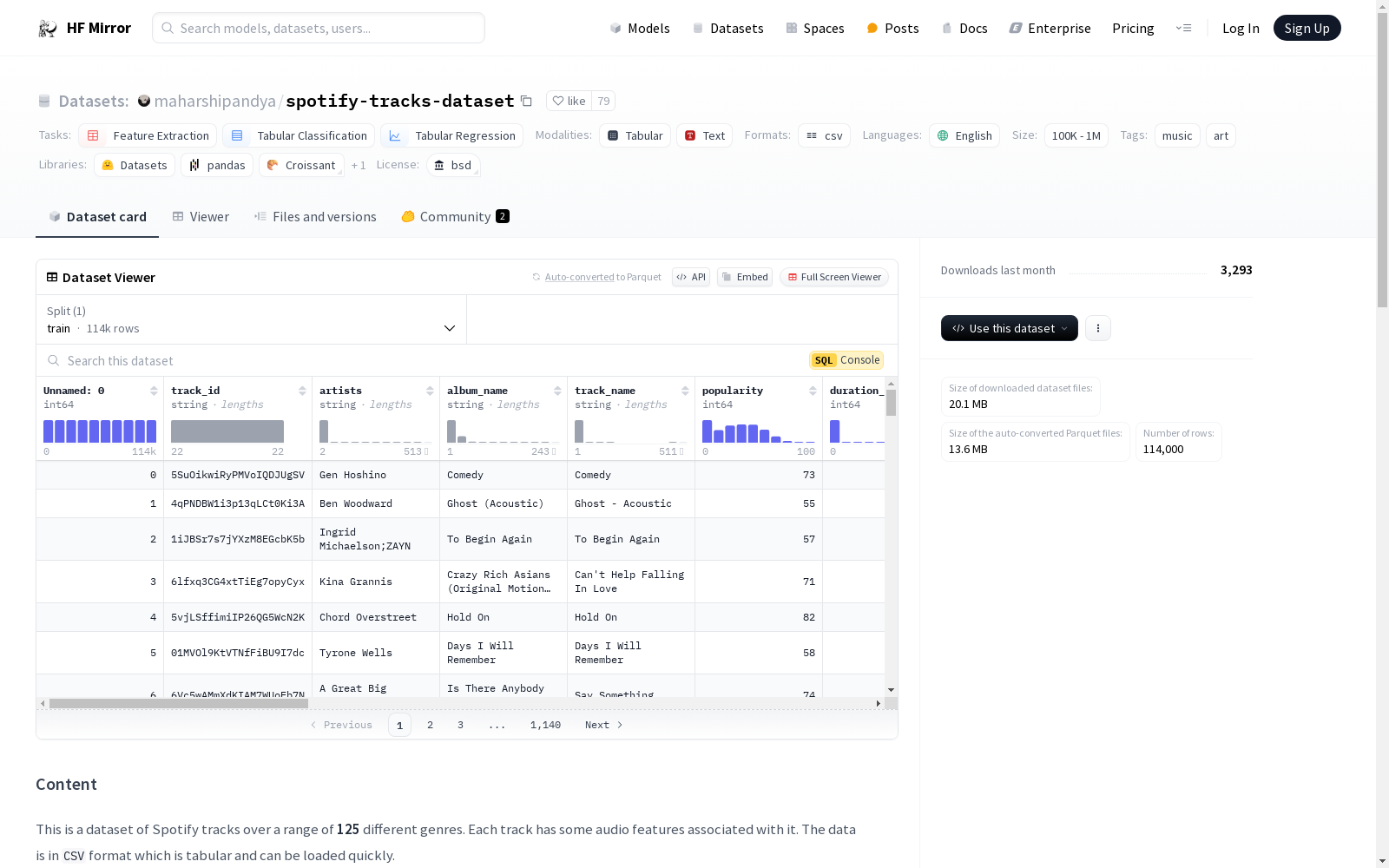
# Content
This is a dataset of Spotify tracks over a range of **125** different genres. Each track has some audio features associated with it. The data is in `CSV` format which is tabular and can be loaded quickly.
# Usage
The dataset can be used for:
- Building a **Recommendation System** based on some user input or preference
- **Classification** purposes based on audio features and available genres
- Any other application that you can think of. Feel free to discuss!
# Column Description
- **track_id**: The Spotify ID for the track
- **artists**: The artists' names who performed the track. If there is more than one artist, they are separated by a `;`
- **album_name**: The album name in which the track appears
- **track_name**: Name of the track
- **popularity**: **The popularity of a track is a value between 0 and 100, with 100 being the most popular**. The popularity is calculated by algorithm and is based, in the most part, on the total number of plays the track has had and how recent those plays are. Generally speaking, songs that are being played a lot now will have a higher popularity than songs that were played a lot in the past. Duplicate tracks (e.g. the same track from a single and an album) are rated independently. Artist and album popularity is derived mathematically from track popularity.
- **duration_ms**: The track length in milliseconds
- **explicit**: Whether or not the track has explicit lyrics (true = yes it does; false = no it does not OR unknown)
- **danceability**: Danceability describes how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable
- **energy**: Energy is a measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity. Typically, energetic tracks feel fast, loud, and noisy. For example, death metal has high energy, while a Bach prelude scores low on the scale
- **key**: The key the track is in. Integers map to pitches using standard Pitch Class notation. E.g. `0 = C`, `1 = C♯/D♭`, `2 = D`, and so on. If no key was detected, the value is -1
- **loudness**: The overall loudness of a track in decibels (dB)
- **mode**: Mode indicates the modality (major or minor) of a track, the type of scale from which its melodic content is derived. Major is represented by 1 and minor is 0
- **speechiness**: Speechiness detects the presence of spoken words in a track. The more exclusively speech-like the recording (e.g. talk show, audio book, poetry), the closer to 1.0 the attribute value. Values above 0.66 describe tracks that are probably made entirely of spoken words. Values between 0.33 and 0.66 describe tracks that may contain both music and speech, either in sections or layered, including such cases as rap music. Values below 0.33 most likely represent music and other non-speech-like tracks
- **acousticness**: A confidence measure from 0.0 to 1.0 of whether the track is acoustic. 1.0 represents high confidence the track is acoustic
- **instrumentalness**: Predicts whether a track contains no vocals. "Ooh" and "aah" sounds are treated as instrumental in this context. Rap or spoken word tracks are clearly "vocal". The closer the instrumentalness value is to 1.0, the greater likelihood the track contains no vocal content
- **liveness**: Detects the presence of an audience in the recording. Higher liveness values represent an increased probability that the track was performed live. A value above 0.8 provides strong likelihood that the track is live
- **valence**: A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry)
- **tempo**: The overall estimated tempo of a track in beats per minute (BPM). In musical terminology, tempo is the speed or pace of a given piece and derives directly from the average beat duration
- **time_signature**: An estimated time signature. The time signature (meter) is a notational convention to specify how many beats are in each bar (or measure). The time signature ranges from 3 to 7 indicating time signatures of `3/4`, to `7/4`.
- **track_genre**: The genre in which the track belongs
# Sources and Methodology
The data was collected and cleaned using Spotify's Web API and Python.
license: BSD
任务类别:
- 特征提取
- 表格分类
- 表格回归
语言:
- 英语
标签:
- 音乐
- 艺术
美观名称: Spotify歌曲数据集(Spotify Tracks Dataset)
数据规模:
- 10万 < 样本量 < 100万
# 内容
本数据集涵盖了覆盖**125**种不同音乐流派的Spotify平台歌曲,每首歌曲均附带对应的音频特征。数据采用`CSV`格式,为结构化表格形式,可快速加载使用。
# 使用方法
本数据集可应用于以下场景:
- 基于用户输入或偏好构建**推荐系统(Recommendation System)**
- 基于音频特征与现有歌曲流派完成**分类(Classification)**任务
- 以及其他你所能想到的各类应用,欢迎共同探讨交流!
# 字段说明
每个字段的详细说明如下:
- **歌曲ID(track_id)**:歌曲在Spotify平台的唯一标识符
- **艺术家(artists)**:演唱该歌曲的艺术家姓名,若包含多位艺术家,以`;`分隔
- **专辑名称(album_name)**:该歌曲所属专辑的名称
- **歌曲名称(track_name)**:歌曲的正式名称
- **流行度(popularity)**:歌曲流行度,取值范围为0至100,100代表最高流行度。该数值由算法计算得出,主要基于歌曲的总播放量与播放时效性。一般而言,近期播放量较高的歌曲流行度会高于过往热门歌曲。重复歌曲(如同首歌曲分别来自单曲专辑与完整专辑)会被独立评分。艺术家与专辑的流行度由歌曲流行度通过数学方式推导得出。
- **时长(duration_ms)**:歌曲时长,单位为毫秒
- **低俗内容标识(explicit)**:标记歌曲是否包含低俗歌词(`true`代表包含,`false`代表不包含或无法确认)
- **可舞性(danceability)**:基于节奏稳定性、节拍强度与整体规整性等多项音乐元素综合评估的歌曲适配舞蹈的程度,取值范围为0.0至1.0,0.0代表最不适宜跳舞,1.0代表最适宜跳舞
- **活力值(energy)**:取值范围为0.0至1.0的感知强度与活跃度度量指标。通常高活力值的歌曲节奏快、音量大且充满氛围感,例如死亡金属类歌曲活力值较高,而巴赫前奏曲则得分较低
- **调式(key)**:歌曲所属的调,整数对应标准音高分类记法,例如`0 = C`,`1 = C♯/D♭`,`2 = D`,以此类推。若未检测到调式信息,则取值为-1
- **响度(loudness)**:歌曲的整体响度,单位为分贝(dB)
- **调式类型(mode)**:指示歌曲的调式(大调或小调),即旋律所基于的音阶类型。大调以1表示,小调以0表示
- **语音度(speechiness)**:检测歌曲中口语内容的占比。录音内容越偏向口语化(如脱口秀、有声书、诗歌朗诵),该属性值越接近1.0。取值高于0.66的歌曲大概率完全由口语内容构成;取值介于0.33与0.66之间的歌曲可能同时包含音乐与口语内容(如分段呈现或叠加的形式,包括说唱音乐);取值低于0.33的歌曲则大概率为纯音乐或非口语化内容
- **原声度(acousticness)**:置信度度量指标,取值范围为0.0至1.0,用于评估歌曲是否为原声录制。1.0代表极高置信度确认该歌曲为原声录制
- **器乐性(instrumentalness)**:预测歌曲是否不含人声。“喔”“啊”类的衬音在此语境下被视为器乐声,而说唱或口语类歌曲则明确属于人声范畴。器乐性取值越接近1.0,代表歌曲不含人声的可能性越高
- **现场感(liveness)**:检测录音中是否存在现场观众。现场感数值越高,代表歌曲为现场录制的概率越大。取值高于0.8的歌曲有极高概率为现场录制版本
- **愉悦度(valence)**:取值范围为0.0至1.0的度量指标,用于描述歌曲传递的音乐正面情绪。高愉悦度的歌曲听起来更积极(如欢快、愉悦、兴奋),而低愉悦度的歌曲则更消极(如悲伤、沮丧、愤怒)
- **节拍速度(tempo)**:歌曲的整体预估节拍速度,单位为每分钟节拍数(BPM)。在音乐术语中,节拍速度指乐曲的快慢节奏,直接由平均节拍时长推导得出
- **拍号(time_signature)**:预估的歌曲拍号。拍号(节拍标记)是用于指定每小节(或每单元)内节拍数的记法规范,取值范围为3至7,分别对应`3/4`至`7/4`的拍号
- **歌曲流派(track_genre)**:该歌曲所属的音乐流派
# 来源与方法论
本数据集通过Spotify的Web API与Python编程语言完成数据采集与清洗工作。
提供机构:
maharshipandya
原始信息汇总
数据集概述
基本信息
- 许可证: BSD
- 任务类别:
- 特征提取
- 表格分类
- 表格回归
- 语言: 英语
- 标签: 音乐、艺术
- 美观名称: Spotify Tracks Dataset
- 大小类别: 10万<n<100万
内容
- 数据集包含125种不同音乐流派的Spotify曲目,每首曲目附带音频特征。
- 数据格式为CSV,便于快速加载。
用途
- 构建基于用户输入或偏好的推荐系统。
- 基于音频特征和可用流派的分类。
- 其他任何创意应用。
列描述
- track_id: Spotify曲目ID
- artists: 表演艺术家的名称,多个艺术家用
;分隔。 - album_name: 曲目所属专辑名称。
- track_name: 曲目名称。
- popularity: 曲目流行度,范围0-100,100为最流行。
- duration_ms: 曲目时长,单位为毫秒。
- explicit: 曲目是否包含明确歌词(true=是;false=否或未知)。
- danceability: 描述曲目适合跳舞的程度,0.0为最不适合,1.0为最适合。
- energy: 能量值,范围0.0-1.0,代表感知到的强度和活跃度。
- key: 曲目所在的音调,使用标准音调类符号表示。
- loudness: 曲目整体响度,单位为分贝。
- mode: 曲目的调式(1=大调,0=小调)。
- speechiness: 检测曲目中口语的存在,值越高表示口语成分越多。
- acousticness: 曲目为原声的置信度,范围0.0-1.0。
- instrumentalness: 预测曲目是否不含人声,值越接近1.0表示越可能不含人声。
- liveness: 检测现场录制的存在,值越高表示越可能是现场录制。
- valence: 描述曲目传达的音乐积极性,范围0.0-1.0。
- tempo: 曲目的估计节奏,单位为每分钟节拍。
- time_signature: 估计的时间签名,表示每小节的拍数。
- track_genre: 曲目所属流派。
数据收集与处理
- 数据通过Spotify的Web API和Python收集并清洗。
搜集汇总
数据集介绍
构建方式
该数据集通过Spotify的Web API采集并使用Python进行清洗,涵盖了125种不同音乐流派的曲目。每首曲目均附带一系列音频特征,如舞蹈性、能量、音调、响度等,这些特征通过算法计算得出,确保数据的准确性和多样性。数据以CSV格式存储,便于快速加载和处理。
使用方法
该数据集适用于多种应用场景,包括但不限于构建基于用户输入或偏好的推荐系统、进行音频特征和流派的分类任务,以及探索其他创新应用。用户可以通过加载CSV格式的数据,利用其中的音频特征和流派信息进行模型训练和验证,从而实现个性化的音乐推荐或深入的音乐特征分析。
背景与挑战
背景概述
音乐分析与推荐系统领域近年来取得了显著进展,其中Spotify Tracks Dataset作为一个涵盖125种不同音乐流派的音频特征数据集,为研究者提供了丰富的资源。该数据集由Spotify Web API采集并经Python处理,包含了每首歌曲的详细音频特征,如舞蹈性、能量、音调、响度等,以及歌曲的流行度、时长和所属流派等信息。这些数据不仅支持音乐推荐系统的构建,还为音乐分类和回归分析提供了基础,极大地推动了音乐信息检索和个性化推荐技术的发展。
当前挑战
尽管Spotify Tracks Dataset为音乐分析提供了丰富的数据资源,但其构建和应用过程中仍面临若干挑战。首先,数据集的多样性要求算法能够有效处理不同流派和风格的音乐特征,这对分类和推荐系统的准确性提出了高要求。其次,数据清洗和标准化过程中,如何确保音频特征的准确性和一致性是一个技术难题。此外,随着音乐流行趋势的变化,如何动态更新和维护数据集的时效性,以保持推荐系统的有效性,也是一个持续的挑战。
常用场景
经典使用场景
Spotify Tracks Dataset 在音乐推荐系统构建中展现了其经典应用价值。通过分析音频特征如舞蹈性、能量、节奏等,结合用户偏好,该数据集可用于个性化音乐推荐,提升用户体验。此外,其丰富的音频特征和多样的音乐流派信息,使其在音乐分类任务中同样表现出色,能够根据音频特征对音乐进行精准分类。
解决学术问题
该数据集通过提供详细的音频特征和流派信息,解决了音乐推荐和分类中的关键学术问题。其高维度的音频特征数据为研究音乐情感分析、音乐风格识别等提供了丰富的素材,推动了音乐信息检索领域的研究进展。同时,数据集中的流行度指标为研究音乐流行趋势提供了量化依据,具有重要的学术价值。
实际应用
在实际应用中,Spotify Tracks Dataset 被广泛用于音乐流媒体平台的推荐系统优化,通过分析用户历史行为和偏好,提供个性化的音乐推荐服务。此外,该数据集还可用于音乐创作辅助工具的开发,帮助音乐人根据特定风格或情感需求生成音乐片段。其应用范围涵盖了从商业推荐系统到艺术创作的多个领域。
数据集最近研究
最新研究方向
在音乐分析与推荐系统领域,maharshipandya/spotify-tracks-dataset数据集的最新研究方向主要集中在利用音频特征进行个性化推荐和音乐情感分析。该数据集通过丰富的音频特征(如舞蹈性、能量、情感等)为研究者提供了深入探索音乐与用户偏好之间关系的宝贵资源。近年来,随着深度学习和强化学习技术的发展,研究者们开始构建基于用户历史行为的智能推荐系统,旨在提高推荐的精准度和用户满意度。此外,音乐情感分析也成为热点,研究者通过分析音乐的情感特征,探索音乐对人类情绪的影响机制,为心理健康和音乐疗法等领域提供了新的研究视角。这些研究不仅推动了音乐科技的进步,也为音乐产业的发展提供了科学依据。
以上内容由遇见数据集搜集并总结生成


