SafeSora
收藏Hugging Face2024-06-20 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/PKU-Alignment/SafeSora
下载链接
链接失效反馈官方服务:
资源简介:
SafeSora是一个专注于文本到视频生成任务的人类偏好数据集,旨在通过安全对齐研究提升大型视觉模型(LVM)的有用性和无害性。该数据集包含三个主要部分:一个包含57k+文本-视频对的分类数据集,用于多标签分类12种伤害标签;一个包含51k+实例的人类偏好数据集,涉及有用性和无害性的比较关系以及有用性的四个子维度;以及一个包含600个人类编写提示的评估数据集,其中300个为安全中性提示,另外300个根据12种伤害类别构建为红队提示。
SafeSora is a human preference dataset focused on text-to-video generation tasks, aiming to enhance the usefulness and harmlessness of large vision models (LVMs) through safety alignment research. The dataset includes three main components: a classification dataset with over 57k text-video pairs for multi-label classification of 12 harm tags; a human preference dataset with more than 51k instances, covering comparative relationships regarding usefulness and harmlessness as well as four sub-dimensions of usefulness; and an evaluation dataset containing 600 human-written prompts, among which 300 are safety-neutral prompts and the remaining 300 are red-teaming prompts constructed based on the 12 harm categories.
创建时间:
2024-06-10
原始信息汇总
数据集概述
基本信息
- 许可证: cc-by-nc-4.0
- 任务类别: text-to-video
- 语言: 英语
- 标签:
- human-feedback
- preference
- ai safety
- large vision model (LVM)
- large language model (LLM)
- alignment
- 数据规模: 10K<n<100K
数据集配置
- 配置名称: default
- 训练集: config-train.json.gz
- 测试集: config-test.json.gz
数据集内容
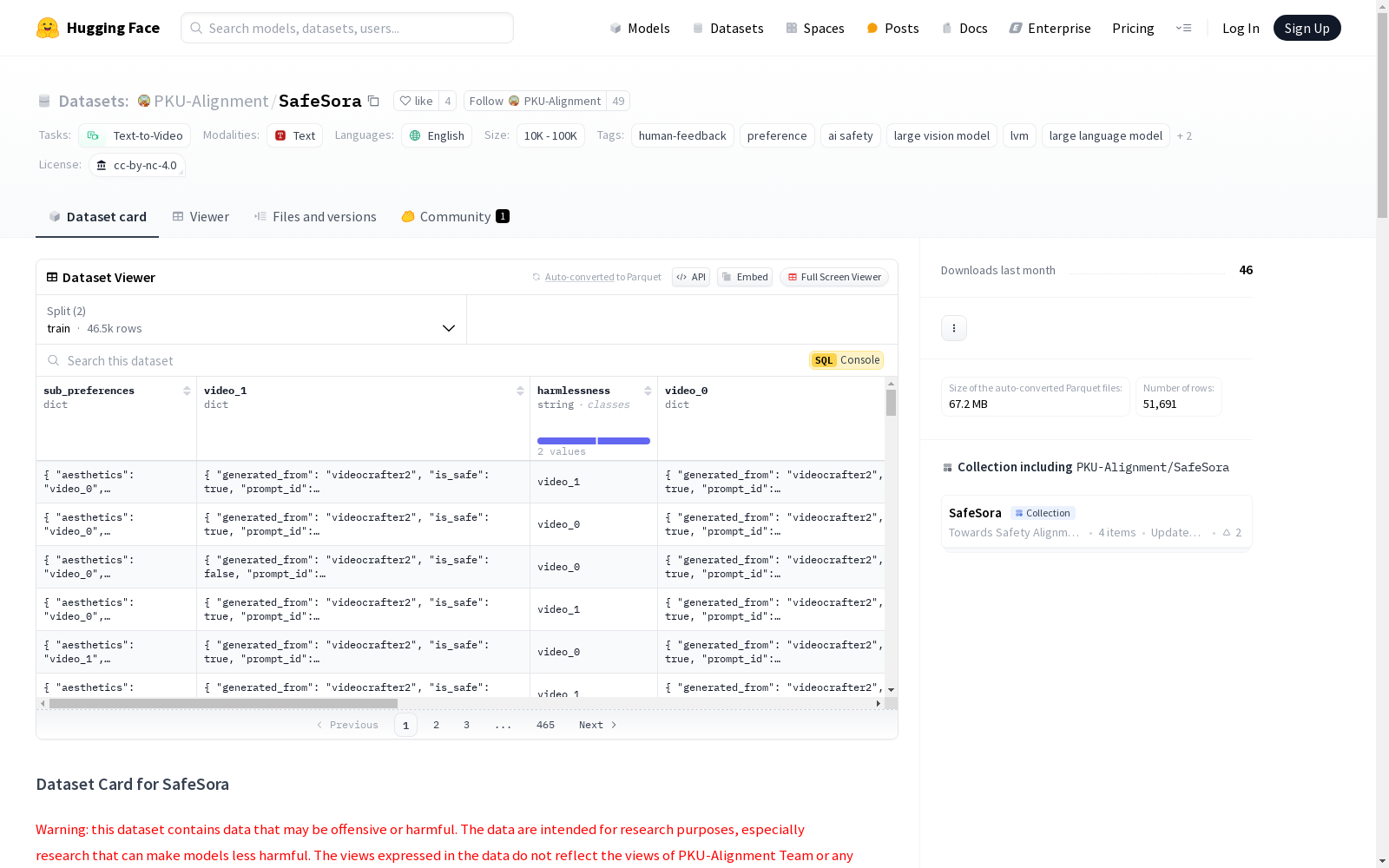
SafeSora 是一个人类偏好数据集,旨在支持文本到视频生成领域的安全对齐研究,目标是提高大型视觉模型(LVMs)的有用性和无害性。目前包含以下三种数据类型:
- 分类数据集 (SafeSora-Label): 包含超过 57k 个文本-视频对,涉及 12 种有害标签的多标签分类。
- 人类偏好数据集 (SafeSora): 包含超过 51k 个实例,涉及文本到视频生成任务中的有用性和无害性的比较关系,以及四个有用性的子维度。
- 评估数据集 (SafeSora-Eval): 包含 600 个人工编写的提示,其中 300 个是安全中性的,另外 300 个根据 12 种有害类别构建为红队提示。
人类偏好数据集详细信息
SafeSora 是一个包含超过 51k 个实例的人类偏好数据集,涉及文本到视频生成任务中的有用性和无害性的比较关系,以及四个有用性的子维度。每个数据点包含用户输入和两个生成的视频。通过基于启发式的标注过程,获得了在 helpfulness 和 harmlessness 维度上的人类偏好。此外,由于预标注启发式过程,还包含了四个有用性子维度的人类偏好,这些子维度是:
Instruction FollowingCorrectnessInformativenessAesthetics
数据点可视化示例
数据点的具体标注过程和可视化示例如下图所示:


搜集汇总
数据集介绍
构建方式
SafeSora数据集的构建基于人类偏好标注,旨在支持文本到视频生成领域的安全对齐研究。数据集包含51,000多个实例,每个实例由用户输入和两个生成的视频组成。通过启发式标注流程,获取了人类在‘有用性’和‘无害性’维度上的偏好,并进一步细化为四个子维度:指令遵循、正确性、信息量和美学。此外,数据集还包含57,000多个文本-视频对的分类数据,以及600个人工编写的提示词用于评估。
使用方法
SafeSora数据集的使用方法主要围绕文本到视频生成模型的安全对齐研究展开。研究人员可以利用数据集中的分类数据(SafeSora-Label)进行多标签分类任务,以识别和减少模型生成内容中的有害性。同时,人类偏好数据(SafeSora)可用于训练和评估模型在‘有用性’和‘无害性’方面的表现。评估数据集(SafeSora-Eval)则提供了人工编写的提示词,可用于测试模型在安全性和中立性上的表现。未来,数据集还将开源一些基线对齐算法,进一步支持相关研究。
背景与挑战
背景概述
SafeSora数据集由PKU-Alignment团队开发,旨在支持文本到视频生成领域的安全对齐研究,特别是针对大型视觉模型(LVMs)的有用性和无害性进行优化。该数据集包含超过51,000个实例,涵盖了文本到视频生成任务中的人类偏好数据,涉及有用性和无害性的比较关系,以及四个有用性子维度。SafeSora的创建标志着在AI安全领域的一个重要进展,尤其是在如何通过人类反馈来减少模型生成有害内容方面。该数据集不仅为研究者提供了丰富的实验材料,也为未来开发更安全的AI模型奠定了基础。
当前挑战
SafeSora数据集在构建和应用过程中面临多重挑战。首先,文本到视频生成任务本身具有高度复杂性,如何准确捕捉和量化人类偏好,尤其是在有用性和无害性之间的权衡,是一个技术难题。其次,数据集的构建依赖于大量的人工标注,如何确保标注的一致性和准确性,尤其是在处理涉及有害内容的敏感数据时,是一个重要的挑战。此外,如何设计有效的基线对齐算法以利用这些数据集进行模型优化,也是当前研究中的一个关键问题。这些挑战不仅考验了数据集的构建质量,也对未来AI安全研究提出了更高的要求。
常用场景
经典使用场景
SafeSora数据集在文本到视频生成领域的研究中扮演着关键角色,特别是在提升大型视觉模型(LVMs)的安全性和无害性方面。该数据集通过提供大量的人类偏好数据,帮助研究人员评估和优化模型在生成视频时的帮助性和无害性。其经典使用场景包括模型对齐研究、安全评估以及多维度的人类反馈分析。
解决学术问题
SafeSora数据集解决了文本到视频生成模型在安全对齐方面的核心问题。通过提供详细的分类数据和人类偏好数据,研究人员能够深入分析模型在生成内容时的潜在危害,并设计出更安全的算法。该数据集还支持多维度评估,如指令遵循、正确性、信息量和美学,为模型优化提供了全面的反馈机制。
实际应用
在实际应用中,SafeSora数据集被广泛用于开发更安全的文本到视频生成系统。例如,在社交媒体平台和内容创作工具中,该数据集帮助开发者识别和减少有害内容的生成。此外,它还被用于教育领域,确保生成的教学视频既准确又无害,从而提升学习体验。
数据集最近研究
最新研究方向
在文本到视频生成领域,SafeSora数据集的最新研究方向聚焦于通过人类反馈优化大型视觉模型(LVMs)的安全对齐。该数据集不仅包含了超过57,000个文本-视频对的分类数据,还提供了51,000多个实例的人类偏好数据,这些数据在帮助性和无害性方面进行了详细的比较。此外,SafeSora还包含一个评估数据集,该数据集由600个人类编写的提示组成,旨在测试模型在安全中性及12种有害类别提示下的表现。这些数据为研究者提供了一个独特的平台,以探索和开发新的算法,从而提高生成内容的质量和安全性,减少潜在的负面影响。随着人工智能技术的快速发展,SafeSora数据集的研究和应用将对推动AI伦理和安全标准的发展产生重要影响。
以上内容由遇见数据集搜集并总结生成


