n8n-nodes-catalog
收藏Hugging Face2026-05-13 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/automatelab/n8n-nodes-catalog
下载链接
链接失效反馈官方服务:
资源简介:
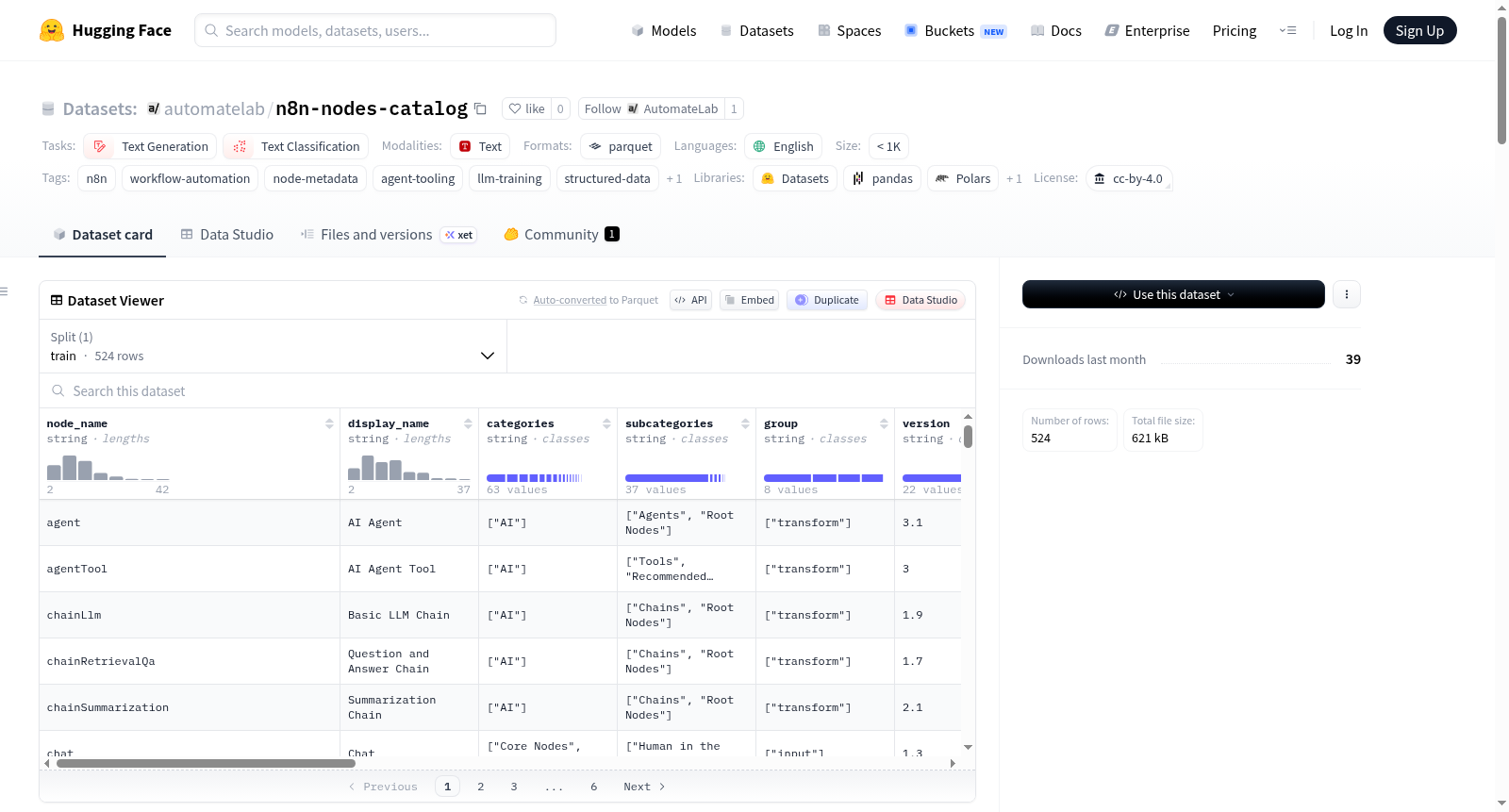
n8n节点目录是一个结构化、机器可读的n8n节点元数据目录,直接从n8n GitHub仓库提取。该数据集基于n8n@2.20.6版本,包含524个节点,其中431个来自packages/nodes-base,93个来自packages/@n8n/nodes-langchain,并每月更新。其目的是提供节点级元数据,以填补现有n8n数据集(如工作流集合和构建器训练集)的空白,使AI代理能够推理使用哪些节点及其支持的功能,而无需依赖过时的训练数据猜测。数据集适用于大型语言模型(LLM)的训练和微调、推理时的代理工具、开发者参考以及n8n节点生态系统的定量研究。数据以JSON数组(nodes.json)和列式Parquet格式(nodes.parquet)提供,包含13个字段,详细描述每个节点的名称、类别、支持的操作、凭证要求、属性模式、源位置等信息。提取方法通过一个Python脚本(extract.py)实现,从n8n发布tarball中解析TypeScript源文件,并排除版本化或实现子目录中的文件。数据集添加内容使用CC-BY-4.0许可,而上游节点元数据则遵循n8n可持续使用许可证。
The n8n node directory is a structured, machine-readable directory of n8n node metadata, extracted directly from the n8n GitHub repository. This dataset is based on n8n@2.20.6, containing 524 nodes (431 from packages/nodes-base and 93 from packages/@n8n/nodes-langchain) and is updated monthly. It aims to provide node-level metadata to fill gaps in existing n8n datasets (such as workflow collections and builder training sets), enabling AI agents to reason about which nodes to use and their supported functionalities without relying on outdated training data guesses. The dataset is suitable for LLM training and fine-tuning, agent tools at inference time, developer reference, and quantitative research on the n8n node ecosystem. Data is provided in JSON array (nodes.json) and columnar Parquet (nodes.parquet) formats, with 13 fields detailing each nodes name, category, supported operations, credential requirements, property schema, source location, and more. Extraction is implemented via a Python script (extract.py) that parses TypeScript source files from n8n release tarballs, excluding files in versioned or implementation subdirectories. The dataset added content is licensed under CC-BY-4.0, while upstream node metadata follows the n8n Sustainable Use License.
创建时间:
2026-05-13
搜集汇总
数据集介绍
构建方式
该数据集通过自动化脚本从n8n开源仓库中提取节点元数据构建而成。具体而言,脚本会下载指定版本的n8n发布压缩包,遍历packages/nodes-base与packages/@n8n/nodes-langchain两个核心包中的.node.ts文件,并利用正则表达式与抽象语法树解析技术提取每个节点的描述信息、类别标签、操作列表、凭据需求以及属性模式等字段。同时,脚本会读取同级.node.json文件中的代码元数据作为类别依据。多版本节点通过读取baseDescription与defaultVersion字段统一处理,版本化实现子目录中的文件则被排除。最终输出为UTF-8编码的JSON数组与Snappy压缩的Parquet列式文件,脚本具备幂等性,支持通过--tag参数锁定特定版本。
特点
本数据集的核心优势在于填补了现有n8n工作流数据集在节点级元数据层面的空白,提供了524个节点的结构化描述信息。所有记录均包含节点名称、显示名称、类别与子类别、执行组别、版本号、简要描述、凭据类型列表、支持操作列表以及顶层属性模式JSON。特别地,github_permalink字段将每条记录锚定至提取时的具体版本标签,确保了数据回溯的稳定性。此外,脚本每月自动更新,使模型训练与智能体推理均能基于最新的节点能力信息,有效避免了因训练数据过时而产生的幻觉问题。
使用方法
用户可通过多种方式便捷地使用该数据集。基于Python的数据科学家可利用pandas库读取Parquet文件,并通过json.loads解析列表字段,快速筛选支持特定操作或凭据类型的节点。HuggingFace datasets API支持直接加载数据集并通过列表推导式进行过滤查询。对于高级分析场景,DuckDB的SQL引擎能够直接查询Parquet文件,通过UNNEST函数展开类别数组实现聚合统计。此外,该数据集还适配了大语言模型的微调与推理上下文注入,开发者可将其作为工具选择与操作验证的外部知识库,嵌入到自动化智能体的工作流程中。
背景与挑战
背景概述
随着工作流自动化平台如n8n的普及,人工智能代理在构建复杂自动化流程时面临关键挑战:如何精准理解并调用数百个功能各异的节点。2026年,由AutomateLab团队创建的n8n-nodes-catalog数据集应运而生,旨在填补节点级元数据的空白。该数据集从n8n官方代码仓库中系统性提取了524个节点的结构化元数据,涵盖名称、类别、支持操作、凭据需求及属性模式等关键信息,为大型语言模型的训练和推理阶段提供实时、准确的节点能力参考。其创新性在于将分散的文档转化为机器可读的规范格式,显著降低模型对节点名称与操作签名的幻觉现象,为无代码自动化场景下的智能代理决策奠定了数据基础。
当前挑战
该数据集主要面临双向挑战。从领域问题角度看,工作流自动化中的人工智能代理常因缺乏精确的节点级知识而产生错误调用,例如混淆节点名称或使用不兼容的操作参数,而传统文档浏览方式效率低下且难以被模型直接利用。从构建过程看,数据提取需要从TypeScript源码中解析高度异构的节点描述结构,处理多版本节点的默认版本选择逻辑,以及排除分散于子目录中的版本化实现文件。此外,上游节点元数据遵循n8n可持续使用许可,确保了数据源的开放性,但也要求严格遵循许可条款进行社区维护与分发。
常用场景
经典使用场景
在低代码与工作流自动化领域,n8n-Nodes-Catalog 数据集扮演着核心知识基座的角色。其最经典的用途在于为大型语言模型(LLM)提供结构化的节点元数据语料,使模型能够精准理解 n8n 平台上 524 个节点的名称、类别、凭证需求与操作签名。这一数据集填补了现有工作流集合数据集只关注组合方式的空白,转而聚焦于每个节点的内在属性,因此成为构建智能工作流助手不可或缺的语境来源。通过对节点属性、依赖关系和版本信息的系统化编排,研究者与开发者能够高效检索、比较和验证节点功能,从而在设计自动化流水线时做出更明智的决策。
衍生相关工作
基于 n8n-Nodes-Catalog,学术界与工业界已衍生出多项富有价值的工作。例如,研究者以其为基础训练领域特化的语言模型微调任务,使模型在生成工作流时能够精确引用节点全名与可用操作集合,显著降低幻觉率。有工作进一步将其与工作流执行轨迹数据集耦合,构建端到端的智能自动化推荐系统,实现从任务描述到完整流水线的自动化映射。此外,该数据集的元数据抽取方法论已被推广至其他低代码平台(如 Zapier、Make),催生了跨平台节点目录的对齐与迁移研究。其标准化的 Parquet 格式也为边缘设备上的推理缓存、节点依赖图构建以及变更影响分析提供了可复用的技术路线。
数据集最近研究
最新研究方向
随着低代码与无代码平台的迅猛发展,工作流自动化领域正迎来智能化转型的浪潮。n8n-nodes-catalog数据集通过系统性地提取n8n生态中524个节点的元数据,构建了首个结构化、机器可读的节点能力目录,为人工智能代理在运行时推理与工作流生成提供了精准的上下文基础。这一数据资源填补了现有工作流集合数据集仅关注组装模式而非节点底层能力的空白,使得大型语言模型在微调后能够避免对节点名称和操作签名的幻觉,显著提升自动化任务的可靠性。该数据集的发布不仅推动了基于LLM的智能体在自动化场景中的应用落地,也为生态系统的量化分析与演化追踪奠定了数据基石,对低代码平台的智能化演进具有里程碑式的意义。
以上内容由遇见数据集搜集并总结生成


