Med-REFL-DPO
收藏Hugging Face2025-06-19 更新2025-06-20 收录
下载链接:
https://huggingface.co/datasets/HANI-LAB/Med-REFL-DPO
下载链接
链接失效反馈官方服务:
资源简介:
Med-REFL数据集是一种用于提高大型语言模型在医疗领域推理和反思能力的直接偏好优化(DPO)数据集。该数据集通过利用树状思维(Tree-of-Thought)方法生成和评估多样化的推理轨迹来构建,包含两个子集:推理增强数据集和反思增强数据集。推理增强数据集包含大约12,000个用于提高一般推理辨识度的偏好对,而反思增强数据集则包含大约21,000个用于模型自我校正的偏好对。
The Med-REFL dataset is a direct preference optimization (DPO) dataset developed to enhance the reasoning and reflection capabilities of large language models (LLMs) in the medical domain. Constructed by leveraging the Tree-of-Thought (ToT) method to generate and evaluate diverse reasoning trajectories, this dataset comprises two subsets: the reasoning-enhanced dataset and the reflection-enhanced dataset. The reasoning-enhanced dataset contains approximately 12,000 preference pairs intended to improve the discernment of general reasoning, while the reflection-enhanced dataset includes roughly 21,000 preference pairs tailored for model self-correction.
创建时间:
2025-06-10
原始信息汇总
Med-REFL-DPO 数据集概述
基本信息
- 许可证: Apache-2.0
- 任务类别: 问答、文本生成
- 语言: 英语
- 标签: 医学、推理、反思、DPO
数据集配置
-
Reasoning Enhancement
- 配置文件:
reasoning_enhancement - 数据文件:
data/Med-REFL-Data/Reasoning Enhancement.json - 数据量: 约12,000个偏好对
- 配置文件:
-
Reflection Enhancement
- 配置文件:
reflection_enhancement - 数据文件:
data/Med-REFL-Data/Reflection Enhancement.json - 数据量: 约21,000个偏好对
- 配置文件:
数据集简介
- 目的: 通过Med-REFL框架提升大型语言模型在医学领域的推理和反思能力。
- 构建方法: 使用低成本、可扩展的流水线,基于Tree-of-Thought (ToT)方法生成和评估多样化的推理轨迹。
- 特点:
- 通过系统比较正确和错误的推理路径,自动构建偏好对。
- 减少对昂贵专家标注的依赖。
子集描述
-
Reasoning Enhancement Data
- 旨在提升一般推理辨别能力。
- 每个偏好对包含高质量的正确推理轨迹与看似合理但错误的推理轨迹。
-
Reflection Enhancement Data
- 专门针对模型的自我纠正能力。
- 偏好对明确奖励有效的反思(在推理过程中和之后),而非有缺陷或无效的尝试。
相关资源
- 论文: https://arxiv.org/abs/2506.13793
- GitHub仓库: https://github.com/TianYin123/Med-REFL
引用
bibtex @misc{yang2025medreflmedicalreasoningenhancement, title={Med-REFL: Medical Reasoning Enhancement via Self-Corrected Fine-grained Reflection}, author={Zongxian Yang and Jiayu Qian and Zegao Peng and Haoyu Zhang and Zhi-An Huang}, year={2025}, eprint={2506.13793}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2506.13793}, }
搜集汇总
数据集介绍
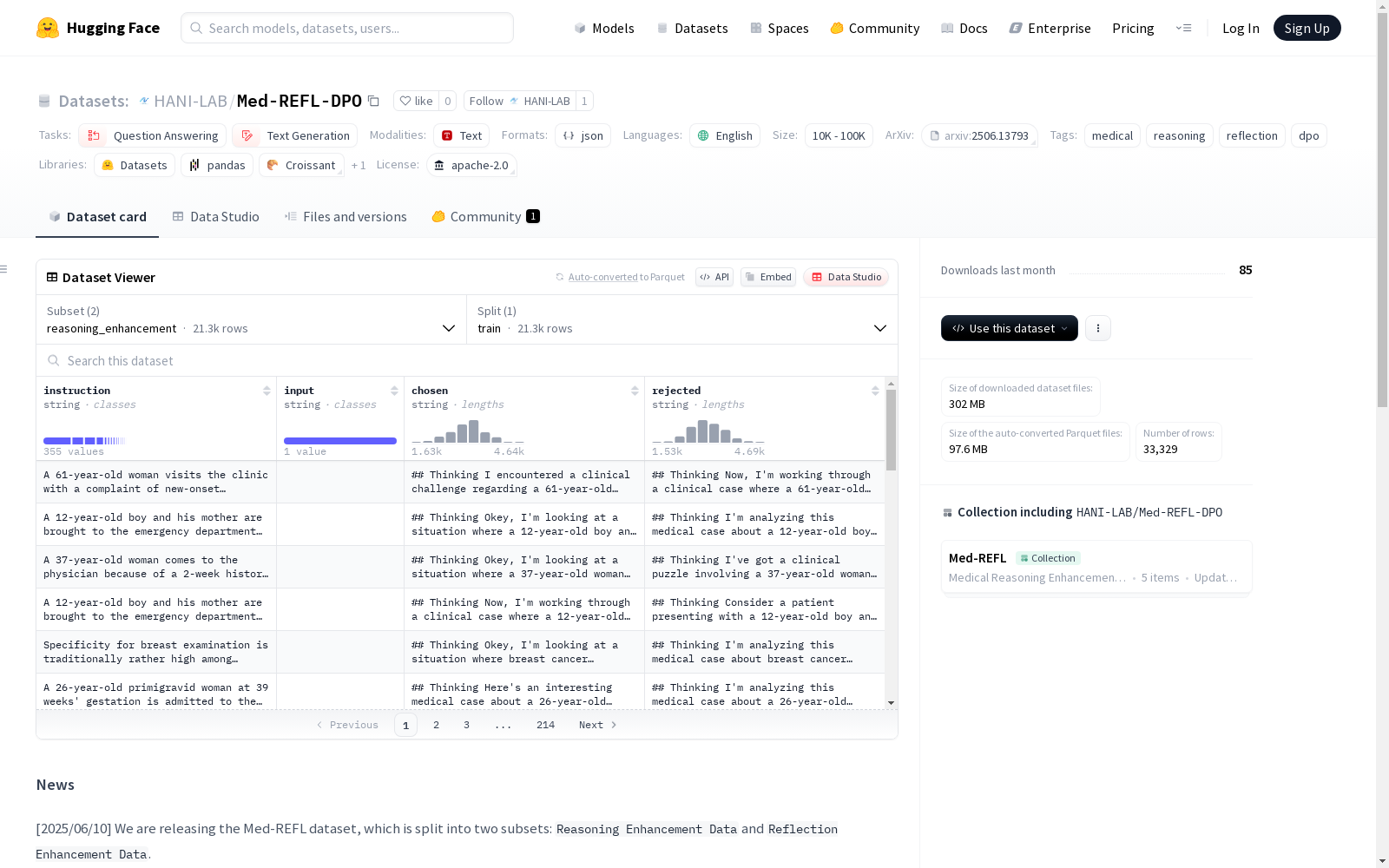
构建方式
在医学知识推理领域,Med-REFL-DPO数据集采用创新的Tree-of-Thought方法构建,通过系统化对比正确与错误推理路径,自动生成偏好对。这种低成本的扩展性流程显著降低了专家标注的依赖,数据集包含两个子集:推理增强数据通过12000组对比轨迹提升模型辨别力,反思增强数据则通过21000组专项训练提升自我纠错能力。
特点
作为专精医学领域的优化数据集,其核心价值体现在细粒度的反思机制设计上。推理增强子集强调逻辑轨迹的优劣判别,反思增强子集则聚焦推理过程中的自我修正能力。独特的双路径对比结构使模型能够识别潜在逻辑缺陷,这种层级化的设计在医疗决策支持场景中具有显著优势。
使用方法
该数据集适用于医疗问答系统的强化训练,研究者可直接加载两个子集进行对比学习。推理增强数据建议用于基础能力培养,反思增强数据则适合高阶调优。通过HuggingFace平台的标准接口,用户可便捷获取JSON格式的偏好对数据,配合DPO算法实现模型微调。具体参数设置可参考附带的GitHub代码库。
背景与挑战
背景概述
Med-REFL-DPO数据集由Zongxian Yang等研究人员于2025年提出,旨在提升大型语言模型在医学领域的推理与反思能力。该数据集依托于Med-REFL框架,采用低成本、可扩展的构建流程,通过树状思维(Tree-of-Thought)方法生成并评估多样化的推理路径。其核心研究问题聚焦于如何通过自动构建偏好对,减少对昂贵专家标注的依赖,同时有效提升模型识别逻辑缺陷和自我纠正的能力。该数据集的发布为医学自然语言处理领域提供了重要的基准资源,推动了模型在复杂医学推理任务中的性能优化。
当前挑战
Med-REFL-DPO数据集面临的挑战主要体现在两个方面。在领域问题层面,医学推理任务具有高度的专业性和复杂性,如何准确捕捉和对比正确与错误的推理路径,以提升模型的判别能力,是该数据集需要解决的核心难题。在构建过程中,生成多样且真实的错误推理轨迹,同时确保偏好对的自动标注质量,避免引入噪声或偏差,是技术实现上的主要挑战。此外,平衡数据集的规模与标注成本,保持其可扩展性,也是构建过程中需要克服的关键问题。
常用场景
经典使用场景
在医疗人工智能领域,Med-REFL-DPO数据集为提升大型语言模型的推理与反思能力提供了关键支持。该数据集通过树状思维(ToT)方法生成多样化的推理轨迹,并自动构建偏好对,特别适用于训练模型识别错误逻辑并进行自我修正。经典使用场景包括医疗问答系统的优化,其中模型需要准确理解复杂的医学问题并提供可靠的解答。
实际应用
该数据集在实际应用中广泛用于医疗咨询平台和临床决策支持系统。通过增强模型的推理和反思能力,Med-REFL-DPO能够帮助医生快速获取准确的医学建议,减少诊断错误。此外,它还被应用于医学教育,为学生提供即时的反馈和纠正,从而提升学习效率。
衍生相关工作
Med-REFL-DPO数据集衍生了多项经典工作,包括基于树状思维的医疗推理优化框架和自动化偏好对生成技术。相关研究进一步探索了模型在罕见病诊断和个性化治疗建议中的应用,推动了医疗AI领域的技术创新。这些工作不仅扩展了数据集的使用范围,还为后续研究提供了重要的方法论支持。
以上内容由遇见数据集搜集并总结生成


