govbrnews
收藏Hugging Face2024-11-27 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/nitaibezerra/govbrnews
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含多个字段,如唯一标识符、发布机构、发布日期、标题、URL、类别、标签、内容和提取时间。数据集被分为训练集,包含30633个样本,总大小为110941926字节。数据集的下载大小为55969726字节。
创建时间:
2024-11-22
原始信息汇总
GovBR News Dataset
概述
GovBR News Dataset 是一个通过自动抓取 gov.br 域名下政府机构发布的最新新闻而形成的数据集。该数据集定期更新,便于监测、分析和研究政府信息。
数据集内容
数据集包含以下结构化字段:
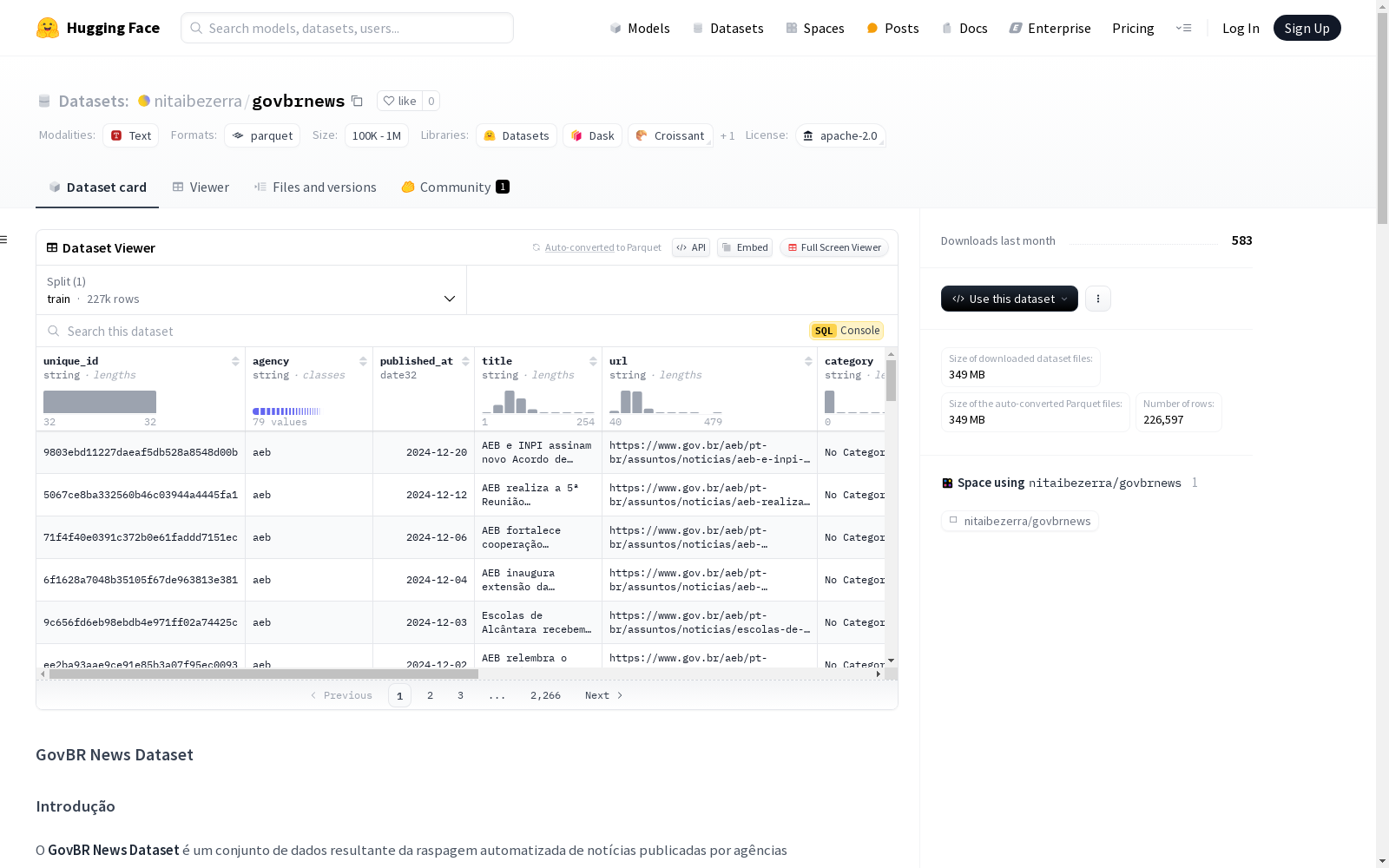
unique_id: 每条新闻的唯一标识符。agency: 发布新闻的政府机构名称。published_at: 新闻发布日期。title: 新闻标题。url: 新闻的原始URL。category: 新闻类别(如果可用)。tags: 与新闻相关的标签列表(如果可用)。content: 新闻的完整内容。extracted_at: 新闻被抓取的日期和时间。
数据集配置
config_name: defaultdata_files:split: trainpath: data/train-*
数据集大小
download_size: 67602734 bytesdataset_size: 138501834 bytessplits:train:num_bytes: 138501834 bytesnum_examples: 45905
使用方法
-
安装
datasets库 bash pip install datasets -
加载数据集 python from datasets import load_dataset
dataset = load_dataset("nitaibezerra/govbrnews")
-
探索数据 使用
datasets库的功能来探索、过滤和分析数据。
更新流程
数据集通过以下自动化流程进行更新:
-
自动抓取
- 每日从项目官方仓库列出的政府机构网站抓取新闻。
-
去重和排序
- 在发布前,数据集经过去重处理,并按
agency(升序)和published_at(降序)排序。
- 在发布前,数据集经过去重处理,并按
-
发布到 Hugging Face
- 更新直接发布到此仓库。
搜集汇总
数据集介绍
构建方式
GovBR News Dataset的构建基于自动化爬取技术,定期从巴西政府机构网站(gov.br域名)抓取新闻内容。数据集通过每日自动化的爬取流程获取最新新闻,并经过去重和排序处理,确保数据的唯一性和时效性。数据按发布机构和发布时间进行排序,最终发布在Hugging Face平台上,便于用户访问和使用。
特点
该数据集涵盖了政府机构发布的新闻及其元数据,包括新闻的唯一标识符、发布机构、发布日期、标题、原始URL、分类、标签以及完整内容。数据集以结构化格式和CSV文件形式提供,支持灵活的数据分析和处理。此外,数据按发布机构和年份进行细分,便于用户根据特定需求进行筛选和查询。
使用方法
用户可以通过Hugging Face平台直接加载数据集,使用Python中的`datasets`库进行数据加载和探索。安装`datasets`库后,用户只需调用`load_dataset`函数即可加载数据集,并利用库提供的功能进行数据分析和处理。此外,数据集还提供CSV格式文件,用户可直接下载并使用其他工具进行数据处理,满足多样化的分析需求。
背景与挑战
背景概述
GovBR News数据集是由巴西政府机构发布的新闻文章自动抓取而成的数据集,旨在为政府信息的监控、分析和研究提供便利。该数据集由巴西管理与公共服务创新部(MGI)维护,作为其集中化和结构化政府信息实验的一部分。数据集包含新闻文章的元数据,如标题、发布日期、类别、标签、原始URL和内容,并定期更新以包含最新信息。该数据集的结构化格式和CSV文件的提供,使其能够广泛应用于多种分析工具和研究场景。
当前挑战
GovBR News数据集在解决政府新闻信息分析领域的问题时,面临多重挑战。首先,政府新闻的多样性和复杂性要求数据集能够准确捕捉和分类不同主题和类别的新闻,这对数据标注和分类算法提出了较高要求。其次,数据抓取过程中可能遇到的技术问题,如网站结构的变化或反爬虫机制,增加了数据获取的难度。此外,数据集的更新频率和完整性依赖于自动化抓取和处理的效率,任何技术故障或延迟都可能影响数据的时效性。最后,确保数据的准确性和一致性,尤其是在处理多源数据时,需要复杂的去重和验证机制。
常用场景
经典使用场景
GovBR News数据集广泛应用于政府新闻的文本分析与信息提取研究。通过该数据集,研究者能够对政府发布的新闻进行主题分类、情感分析以及趋势预测。其结构化的数据格式和丰富的元信息为自然语言处理任务提供了坚实的基础,尤其是在处理多源异构文本数据时,展现了其独特的优势。
解决学术问题
该数据集有效解决了政府新闻数据分散、难以获取的问题,为研究者提供了统一的、标准化的数据源。通过该数据集,学者们能够深入探讨政府信息传播的机制、公众对政策的反应以及新闻内容的语义分析。这不仅推动了政府信息公开研究的发展,还为政策制定者提供了数据支持,促进了政府与公众之间的信息透明化。
衍生相关工作
基于GovBR News数据集,研究者们开发了多种自然语言处理模型,如新闻分类器、主题提取工具以及情感分析系统。这些工作不仅提升了政府新闻数据的处理效率,还为相关领域的研究提供了新的思路。例如,一些研究利用该数据集构建了政府新闻的语义网络,揭示了不同政策主题之间的关联性,为政策分析提供了新的视角。
以上内容由遇见数据集搜集并总结生成


