Vript 英文视频-文本数据集
收藏魔搭社区2026-05-23 更新2024-05-15 收录
下载链接:
https://modelscope.cn/datasets/mutonix/Vript
下载链接
链接失效反馈官方服务:
资源简介:
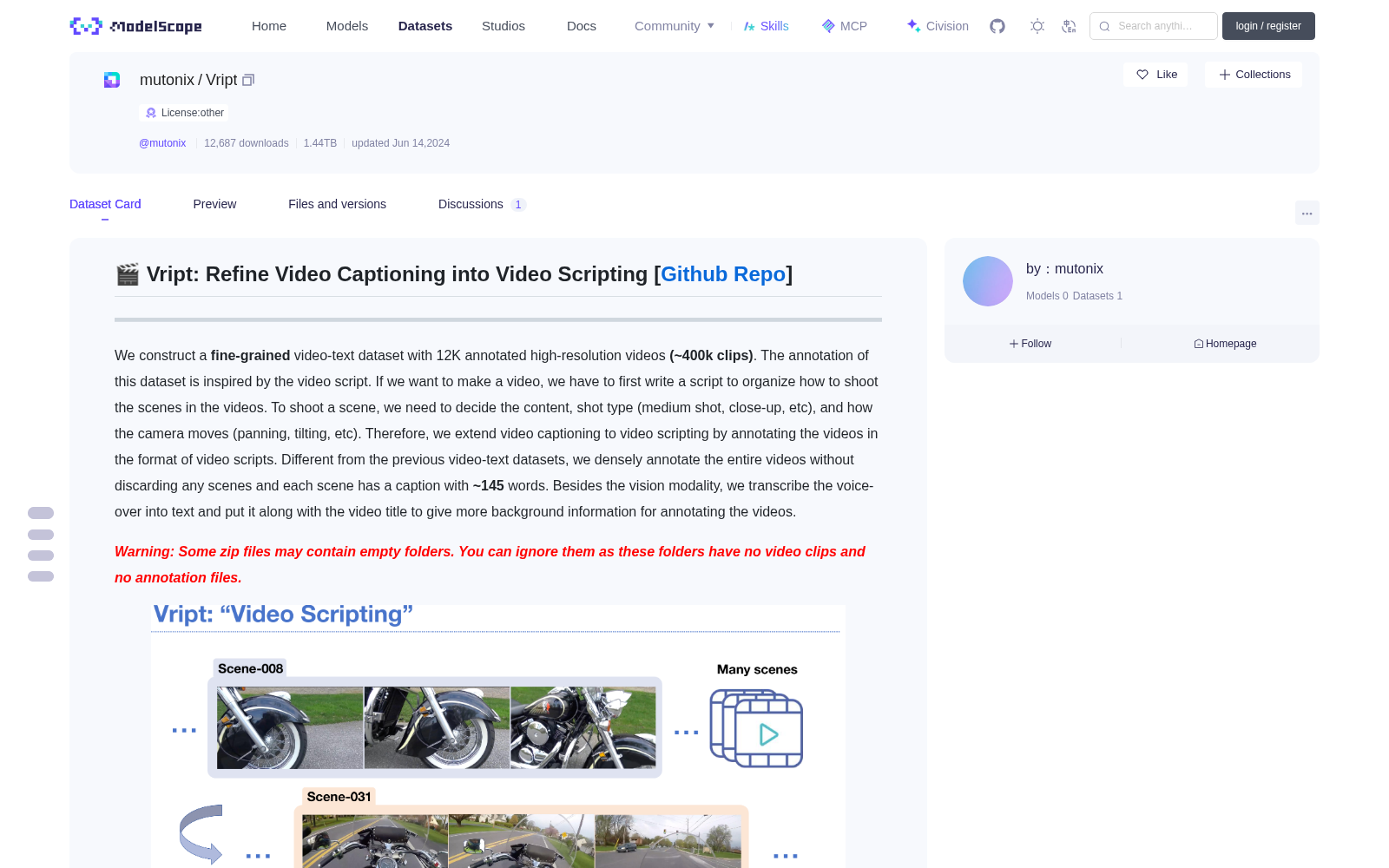
Vript是一个带有12K个注释的高分辨率视频(超过400k片段)的细粒度视频文本数据集。该数据集的注释受到视频脚本的启发。如果我们想做一个视频,我们必须首先写一个脚本来组织如何拍摄视频中的场景。为了拍摄一个场景,我们需要决定内容,拍摄类型(中景,特写等),以及相机如何移动(平移,倾斜等)。因此,受到视频脚本格式的启发,我们以视频脚本的方式对视频进行注释。与之前的视频文本数据集不同,我们在不丢弃任何场景的情况下对整个视频来进行密集注释,每个场景都有一个约145个单词的标题。除了视觉模态,我们还将画外音转录成文字,并与视频标题放在一起,为视频注释提供更多的背景信息。
Vript is a fine-grained video-text dataset comprising high-resolution videos (over 400k clips) paired with 12,000 annotations. The annotations of this dataset are inspired by video scripts. To produce a video, one must first draft a script to outline the shooting plan for each scene in the video. For shooting a single scene, decisions must be made regarding its content, shot type (e.g., medium shot, close-up) and camera movements (e.g., pan, tilt). Thus, drawing inspiration from the structure of video scripts, we annotate videos following the standard video script format. Unlike prior video-text datasets, we conduct dense annotation across the entire video without discarding any scene, with each scene accompanied by a descriptive caption of approximately 145 words. In addition to the visual modality, we also transcribe voiceovers into text and align them with the video captions to provide additional contextual information for the video annotations.
提供机构:
maas
创建时间:
2024-06-14
搜集汇总
数据集介绍
背景与挑战
背景概述
Vript是一个细粒度的英文视频-文本数据集,包含约12K个高分辨率视频(约400K个片段),标注格式采用视频脚本风格,涵盖镜头类型、摄像机运动和内容描述等详细信息。数据集提供完整视频、剪辑视频、字幕和元数据,分辨率达720p,并严格限制为学术研究使用。
以上内容由遇见数据集搜集并总结生成


