Magpie-Phi3-Pro-300K-Filtered
收藏Hugging Face2024-07-03 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Magpie-Align/Magpie-Phi3-Pro-300K-Filtered
下载链接
链接失效反馈官方服务:
资源简介:
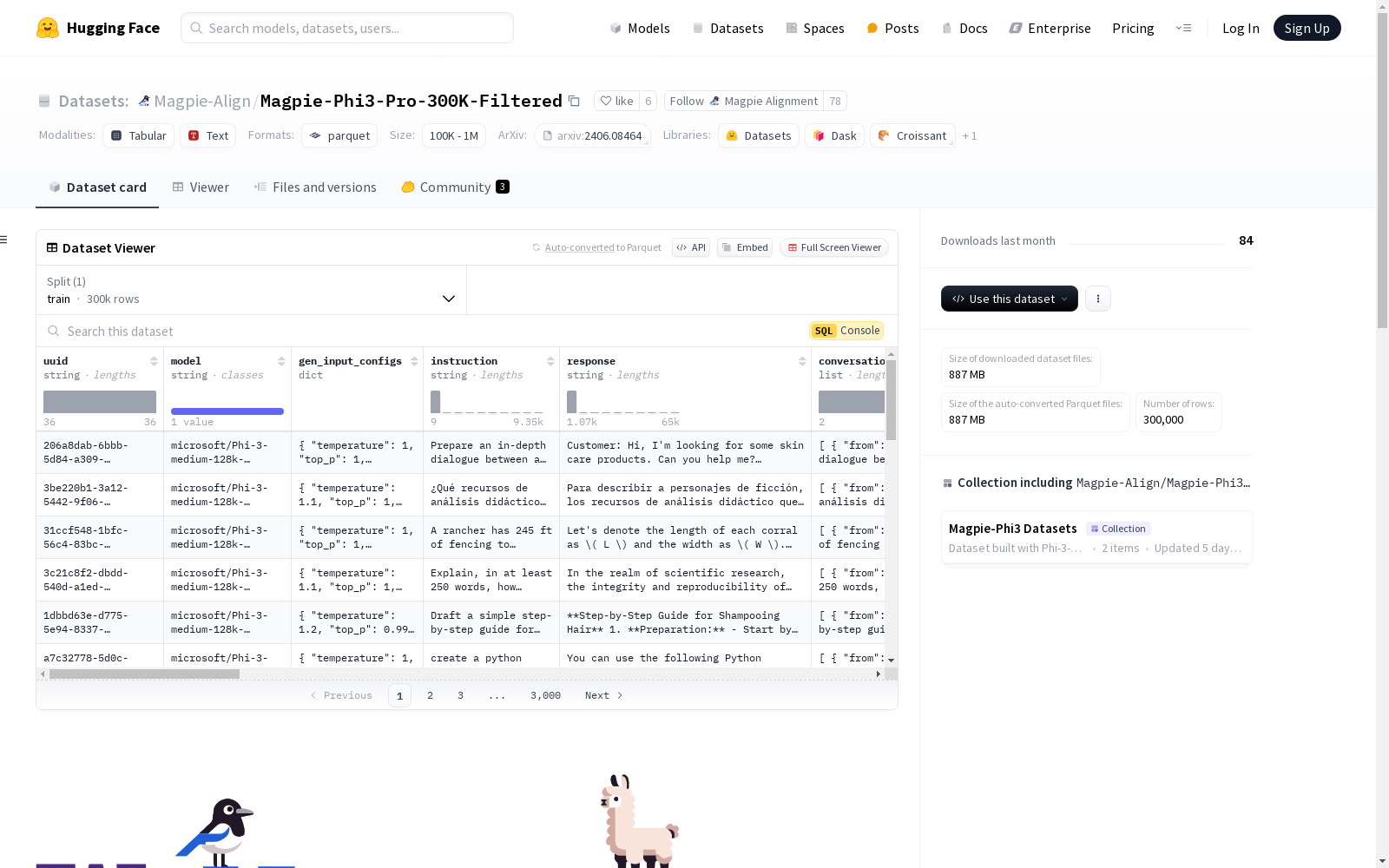
该数据集由microsoft/Phi-3-medium-128k-instruct模型使用Magpie方法生成,包含300,000个高质量实例。数据集的特征包括uuid、模型名称、生成输入配置、指令、响应、对话、任务类别等。数据集通过特定的过滤条件(如输入质量、指令奖励等)筛选出高质量的数据。
创建时间:
2024-06-25
原始信息汇总
数据集概述
数据集信息
-
特征列表:
uuid: 字符串model: 字符串gen_input_configs: 结构体temperature: 浮点数top_p: 浮点数input_generator: 字符串seed: 空值extract_input: 字符串
instruction: 字符串response: 字符串conversations: 列表from: 字符串value: 字符串
task_category: 字符串other_task_category: 字符串序列task_category_generator: 字符串difficulty: 字符串intent: 字符串knowledge: 字符串difficulty_generator: 字符串input_quality: 字符串quality_explanation: 字符串quality_generator: 字符串llama_guard_2: 字符串reward_model: 字符串instruct_reward: 浮点数min_neighbor_distance: 浮点数repeat_count: 整数min_similar_uuid: 字符串instruction_length: 整数response_length: 整数language: 字符串
-
数据分割:
train: 300,000个样本,1,574,922,147.473432字节
-
数据集大小:
- 下载大小:886,548,523字节
- 数据集大小:1,574,922,147.473432字节
配置信息
- 默认配置:
- 数据文件路径:
data/train-*
- 数据文件路径:
可用标签
- 输入长度:指令中的字符总数
- 输出长度:响应中的字符总数
- 任务类别:指令的具体类别
- 输入质量:指令的清晰度、特异性和连贯性,评级为非常差、差、一般、好和优秀
- 输入难度:处理指令所需知识的水平,评级为非常简单、简单、中等、困难或非常困难
- 最小邻居距离:数据集中最近邻居的嵌入距离,可用于过滤重复或相似的实例
- 安全性:由meta-llama/Meta-Llama-Guard-2-8B标记的安全标签
- 奖励:奖励模型给出的特定指令-响应对的输出
- 语言:指令的语言
过滤设置
- 输入质量:>= 好
- 指令奖励:>=-10
- 移除重复和不完整的指令(例如,以:结尾)
- 选择300K具有最长响应的数据
搜集汇总
数据集介绍
构建方式
Magpie-Phi3-Pro-300K-Filtered数据集是通过自合成方法构建的,利用对齐的大型语言模型(如Llama-3-Instruct)生成用户查询和响应。具体而言,模型通过输入左侧模板至用户消息预留位置,利用其自回归特性生成指令和响应。随后,从生成的400万条指令中筛选出30万条高质量实例,确保数据的多样性和质量。
使用方法
Magpie-Phi3-Pro-300K-Filtered数据集适用于监督微调(SFT)任务,可用于训练和优化大型语言模型。用户可通过Hugging Face平台下载数据集,并结合提供的技术报告和代码库进行深入研究和实验。数据集的高质量特性使其在多个对齐基准测试中表现出色,能够显著提升模型的性能。
背景与挑战
背景概述
Magpie-Phi3-Pro-300K-Filtered数据集由微软Phi-3-medium-128k-instruct模型生成,基于Magpie项目开发。该数据集旨在解决大语言模型(LLMs)对齐过程中高质量指令数据稀缺的问题。Magpie项目提出了一种自合成方法,通过从已对齐的LLMs(如Llama-3-Instruct)中提取用户查询,生成大规模对齐数据。该方法利用LLMs的自回归特性,仅输入左侧模板即可生成用户查询,从而显著降低了数据生成的成本和复杂性。数据集包含300K高质量指令-响应对,涵盖了多种任务类别和难度级别,旨在提升LLMs在监督微调(SFT)中的表现。研究结果表明,使用Magpie数据进行SFT的模型在某些任务中表现优于其他公开数据集,甚至在未进行偏好优化的情况下也能取得显著效果。
当前挑战
Magpie-Phi3-Pro-300K-Filtered数据集在构建过程中面临多重挑战。首先,高质量指令数据的生成依赖于对齐LLMs的准确性和多样性,然而LLMs的生成能力受限于其训练数据的广度和深度,可能导致生成数据的多样性和质量不足。其次,数据过滤和选择过程中需平衡数据的多样性和质量,避免重复或低质量样本的引入。此外,数据集的构建需考虑指令的清晰性、任务难度和安全性等多维度因素,确保生成的数据能够有效支持LLMs的对齐任务。最后,数据集的规模和质量直接影响模型微调的效果,如何在有限资源下最大化数据集的效用,是构建过程中亟待解决的核心问题。
常用场景
经典使用场景
Magpie-Phi3-Pro-300K-Filtered数据集在自然语言处理领域中被广泛应用于大语言模型(LLMs)的对齐任务。通过对齐模型的自我合成方法,该数据集能够生成高质量的指令数据,用于模型的监督微调(SFT)。其经典使用场景包括在AlpacaEval、ArenaHard和WildBench等对齐基准测试中,评估模型在多样化任务中的表现。
解决学术问题
该数据集解决了大语言模型对齐数据稀缺和多样性的问题。通过从已对齐的LLMs中提取指令数据,Magpie-Phi3-Pro-300K-Filtered提供了一种高效且低成本的数据生成方法,显著提升了公开对齐数据集的质量和规模。这一创新不仅推动了AI民主化进程,还为研究社区提供了丰富的数据资源,助力模型在复杂任务中的表现优化。
实际应用
在实际应用中,Magpie-Phi3-Pro-300K-Filtered数据集被用于训练和优化大语言模型,特别是在需要高质量指令数据的场景中。例如,在智能客服、教育辅助工具和内容生成系统中,该数据集能够帮助模型生成更准确、连贯且符合用户需求的响应,从而提升用户体验和系统性能。
数据集最近研究
最新研究方向
在大型语言模型(LLMs)对齐领域,Magpie-Phi3-Pro-300K-Filtered数据集的推出标志着一种新的数据生成方法的兴起。该数据集通过自合成方法从已对齐的LLMs中提取高质量指令数据,解决了传统方法中人力成本高、数据多样性受限的问题。研究表明,使用Magpie数据集进行监督微调(SFT)的模型在多个对齐基准测试中表现优异,甚至超越了使用其他公开数据集进行SFT和偏好优化的模型。这一发现不仅验证了Magpie数据集的实用性和高效性,也为未来LLMs对齐研究提供了新的思路和工具。此外,该数据集的安全性和质量过滤机制确保了数据的可靠性和多样性,为研究者提供了一个高质量的资源,推动了LLMs对齐技术的进一步发展。
以上内容由遇见数据集搜集并总结生成


