Lunara Aesthetic Dataset
收藏arXiv2026-01-16 更新2026-01-17 收录
下载链接:
https://huggingface.co/datasets/moonworks/lunara-aesthetic
下载链接
链接失效反馈官方服务:
资源简介:
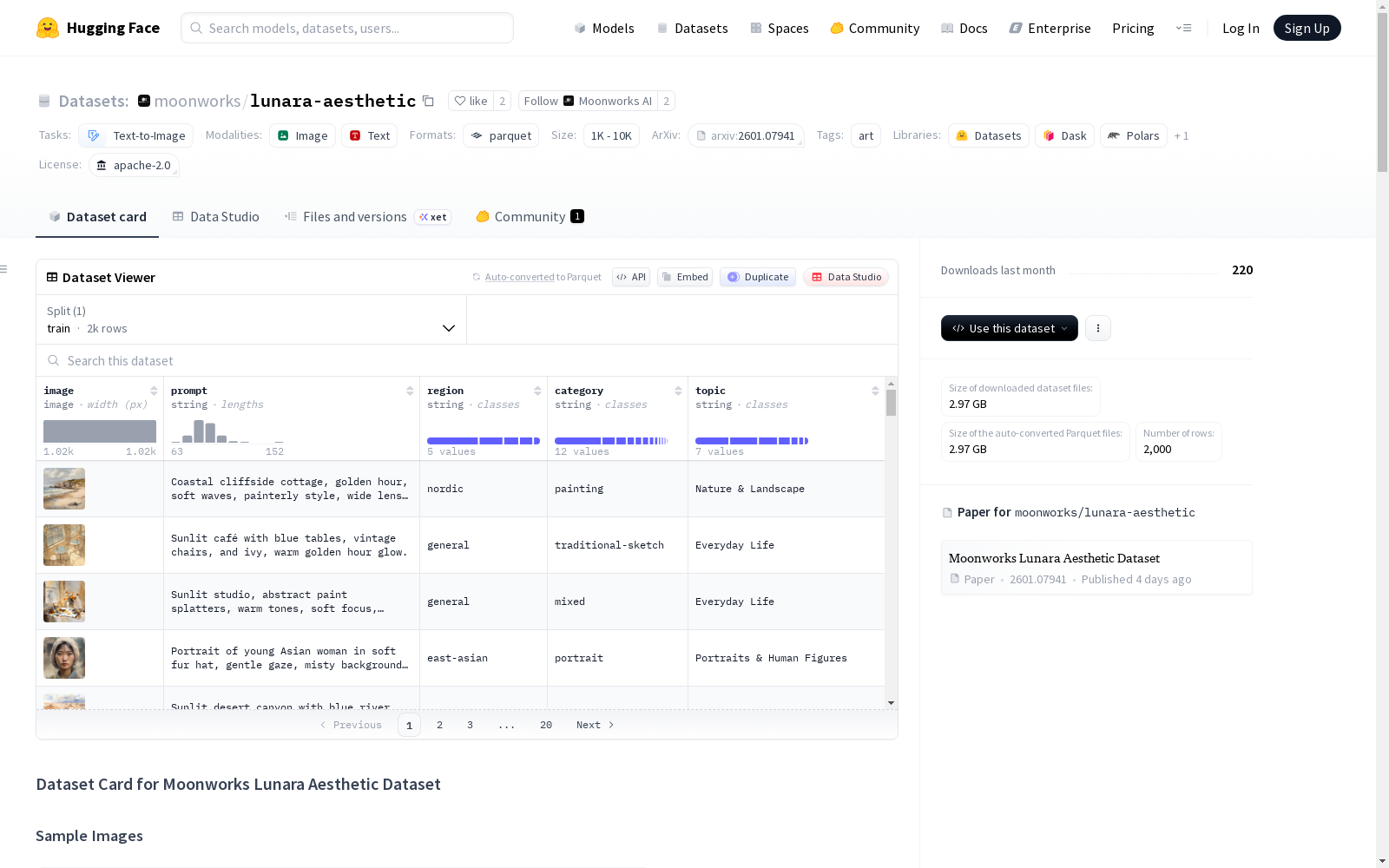
Lunara美学数据集由Moonworks AI构建,是首个专注于文本到图像生成系统中风格调控与提示锚定的公开数据集,包含2000组1024×1024分辨率的图像-提示对。数据覆盖中东、北欧、东亚和南亚等地域美学风格,以及素描、油画等通用艺术类别,所有图像均通过Lunara模型生成并经过人工提示优化与结构化标注。该数据集通过主动学习框架构建,强调美学质量与文化多样性,适用于生成模型风格微调、跨文化视觉表征研究及图像检索任务,为解决现有数据集中美学噪声与版权不透明问题提供了标准化基准。
The Lunara Aesthetics Dataset, developed by Moonworks AI, is the first public dataset dedicated to style control and prompt anchoring in text-to-image generation systems. It comprises 2000 image-prompt pairs with a resolution of 1024×1024. The dataset encompasses aesthetic styles from regions including the Middle East, Northern Europe, East Asia and South Asia, as well as general art categories such as sketches and oil paintings. All images are generated using the Lunara model, and are subsequently subjected to manual prompt optimization and structured annotation. Built upon an active learning framework, the dataset prioritizes aesthetic quality and cultural diversity, and is applicable to style fine-tuning of generative models, cross-cultural visual representation research, and image retrieval tasks. It serves as a standardized benchmark for addressing the issues of aesthetic noise and copyright opacity in existing datasets.
提供机构:
Moonworks AI
创建时间:
2026-01-13
原始信息汇总
Moonworks Lunara Aesthetic 数据集概述
数据集基本信息
- 数据集名称: Moonworks Lunara Aesthetic Dataset
- 发布者/作者: Yan Wang, M M Sayeef Abdullah, Partho Hassan, Sabit Hassan
- 许可证: Apache 2.0
- 发布日期: 2026年
- 引用信息:
- 标题: Moonworks Lunara Aesthetic Dataset
- 作者: Yan Wang, M M Sayeef Abdullah, Partho Hassan, Sabit Hassan
- 年份: 2026
- arXiv ID: 2601.07941
- 链接: https://arxiv.org/abs/2601.07941
数据集内容与规模
- 核心内容: 包含2000个高质量的图像-提示词对。
- 数据用途: 专为文本到图像生成中的提示词落地、风格调节和美学对齐的受控研究而设计。
- 图像来源: 所有图像均由Moonworks Lunara模型生成。该模型是一个推理时参数量小于100亿的扩散混合架构模型,并使用Moonworks CAT方法进行训练。
- 提示词来源: 图像配对的提示词经过人工精炼,并带有结构化标签。
- 数据特点: 强调清晰度、一致性和许可透明度,而非规模。
数据结构与特征
- 数据分割: 仅包含训练集。
- 样本数量: 2000个示例。
- 数据大小:
- 数据集大小: 2953317713字节
- 下载大小: 2970387971字节
- 特征字段:
image: 生成的图像(1024×1024像素)。prompt: 描述性的自然语言提示词。region: 宽泛的区域美学标签。category: 艺术风格或媒介。topic: 高级语义主题。
任务类别与标签
- 主要任务类别: 文本到图像生成。
- 标签:
- 艺术
- 规模类别: 1K < n < 10K。
访问与使用
- Hugging Face数据集地址: https://huggingface.co/datasets/moonworks/lunara-aesthetic
- 加载方式: 可通过Hugging Face
datasets库的load_dataset函数加载。 - 可视化代码: README文件中提供了在Google Colab中随机可视化10个样本的完整代码示例。
搜集汇总
数据集介绍
构建方式
在文本到图像生成领域,追求高质量美学输出与精确提示跟随的研究常受限于公开数据集的稀缺。Lunara美学数据集的构建采用了系统化的生成与精炼流程,首先利用Moonworks Lunara模型生成初始图像,该模型基于复合主动迁移方法训练,专精于捕捉多样艺术风格。随后,通过人工审核对每张图像的提示文本进行精细化修订,确保其准确描述图像中的显著物体、属性、关系及风格线索,并剔除不符合质量标准的配对。此外,数据集还经过两轮标注流程,统一了主题、区域与风格分类体系,从而保证了标注的一致性与精确性。
特点
该数据集的核心特征体现在其卓越的美学质量与丰富的风格多样性上。量化评估显示,其平均美学评分显著超越现有通用乃至专注美学的数据集,其中超过三分之一图像的评分高于常用高美学阈值。数据集涵盖中东、北欧、东亚及南亚等地域性美学风格,同时包含素描、油画等通用艺术媒介,形成了17种独特的风格组合。每对图像与提示均经过人工精炼,语义对齐度高,且视觉多样性丰富,不同类别间的感知差异明显,为风格分析与跨文化视觉表征研究提供了理想素材。
使用方法
该数据集主要服务于生成模型的可控风格学习与标准化评估。研究人员可利用其进行模型微调实验,以获取特定美学、区域或媒介的风格条件生成能力,从而系统分析风格学习机制。同时,它可作为基准数据集,用于评估不同图像生成模型在美学质量与提示跟随性能上的表现。其高质量的人工标注也使其适用于提升视觉语言模型的主题理解,或用于基于风格与语义的图像检索任务。数据集采用Apache 2.0许可,支持无限制的学术与商业用途。
背景与挑战
背景概述
随着文本到图像生成技术的迅猛发展,模型在构图一致性和渲染保真度方面取得了显著进步,然而,高质量、可公开使用的数据集在美学建模与风格条件化研究领域仍显匮乏。Lunara美学数据集由Moonworks AI团队于2026年首次公开发布,旨在为提示词接地与风格条件化的可控研究提供支持。该数据集包含2000个图像-提示词对,覆盖中东、北欧、东亚和南亚等地域美学,以及素描、油画等通用艺术风格,所有图像均通过Lunara模型生成,并经过人工精炼与标注。其核心研究问题聚焦于提升生成图像的美学质量与风格多样性,为视觉-语言模型的微调与评估提供了标准化基准,对推动跨文化美学表征与可控生成研究具有重要影响力。
当前挑战
在文本到图像生成领域,如何精确实现提示词接地与复杂风格条件化仍是一个核心挑战,现有大规模网络爬取数据集常因标注噪声与语义模糊而难以支撑可控实验。Lunara美学数据集构建过程中面临双重挑战:其一,在领域问题层面,需克服模型生成图像在复杂构图与细粒度空间约束下可能出现的结构不一致与伪影问题,确保美学质量与风格保真度;其二,在构建过程中,需通过人工精炼与两轮标注流程来保证提示词的语义准确性与风格标签的一致性,同时维持地域美学表达的丰富性与文化敏感性,避免对艺术传统进行过度简化或刻板表征。
常用场景
经典使用场景
在文本到图像生成领域,Lunara Aesthetic Dataset 为研究者提供了精准的风格调控与提示词接地研究平台。该数据集通过精心构建的2000个图像-提示词对,覆盖了中东、北欧、东亚和南亚等多元文化区域的美学风格,以及素描、油画等通用艺术媒介,使得研究者能够在受控环境下系统探究模型如何响应特定文化或艺术风格的生成指令。这种设计特别适用于分析生成模型在跨文化美学表达上的忠实度与一致性,为风格条件化研究奠定了标准化基准。
实际应用
在实际应用层面,Lunara Aesthetic Dataset 能够支持定制化艺术创作工具与跨文化视觉内容生成系统的开发。基于其丰富的区域美学与艺术风格标注,开发者可微调图像生成模型以产出符合特定文化语境或媒介风格的高质量视觉内容,例如为数字媒体、教育或文化遗产项目生成风格化插图。同时,数据集的高质量标注也适用于增强视觉语言模型的主题理解能力,或作为图像检索系统的基准,助力构建更精准的文化敏感型视觉应用。
衍生相关工作
围绕该数据集,已衍生出多项聚焦于美学建模与风格条件化的经典研究工作。例如,研究者利用其进行扩散模型在跨文化风格上的微调实验,系统分析模型对不同艺术传统的捕捉能力;亦有工作基于其构建了标准化美学评估基准,用于比较不同生成模型在高质量视觉输出上的性能。这些研究不仅深化了对生成模型中风格学习机制的理解,也为后续开发更细粒度、更具文化包容性的艺术生成数据集提供了方法论借鉴与数据基础。
以上内容由遇见数据集搜集并总结生成


