DuBLaB-en-fr-0.7-f-0.5
收藏Hugging Face2025-02-22 更新2025-02-23 收录
下载链接:
https://huggingface.co/datasets/amine-khelif/DuBLaB-en-fr-0.7-f-0.5
下载链接
链接失效反馈官方服务:
资源简介:
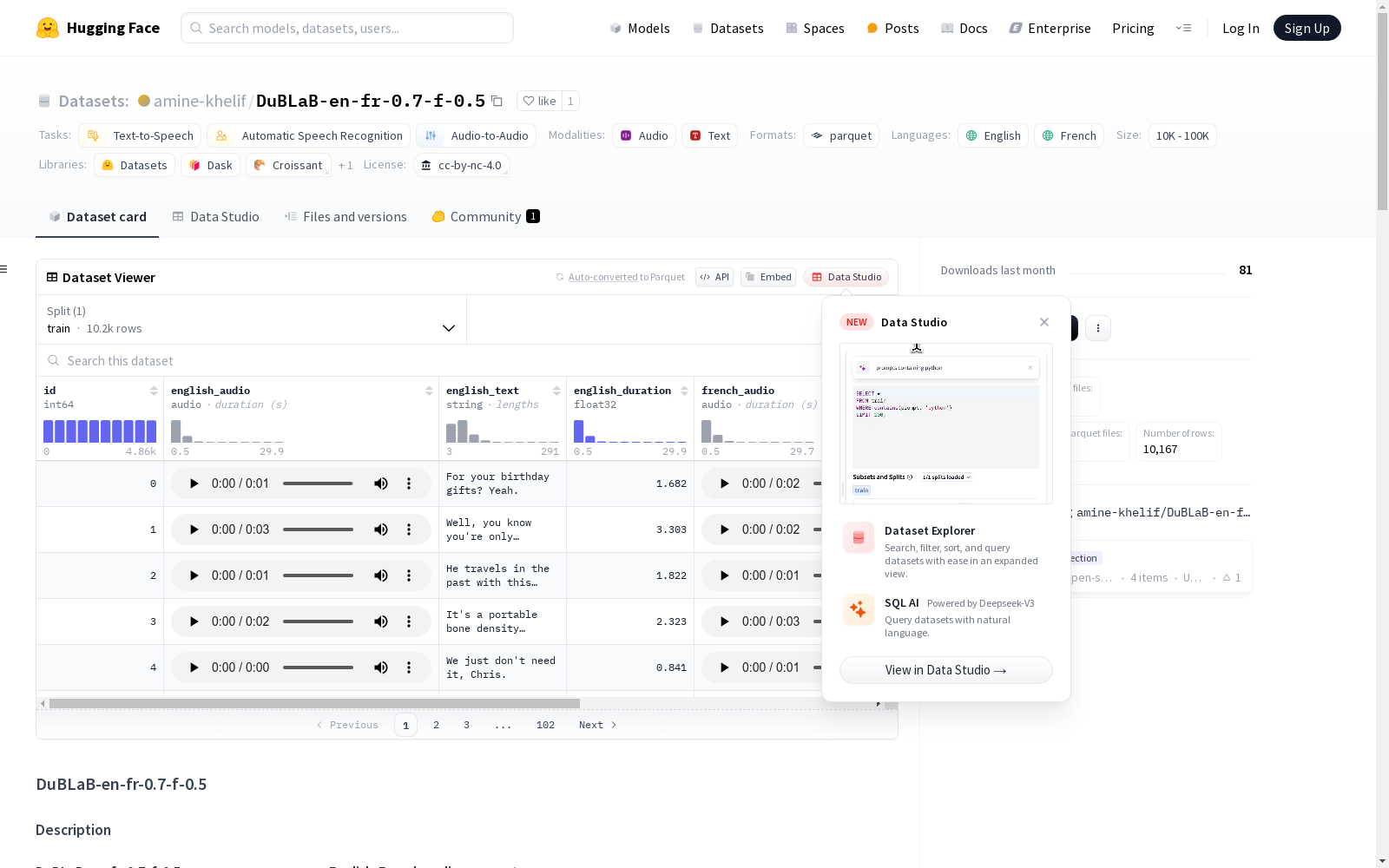
DuBLaB-en-fr-0.7-f-0.5是一个英语-法语双语音频片段数据集,从视听资源中提取并对齐,用于自动语音识别、机器翻译、跨语言风格映射和文本到语音应用。此版本基于0.7版本构建,并通过过滤去除了每秒单词密度低于0.5的片段,以提高数据集质量。
创建时间:
2025-02-18
搜集汇总
数据集介绍
构建方式
DuBLaB-en-fr-0.7-f-0.5数据集是基于视听资源提取的双语(英语-法语)音频片段集合,其构建过程涉及对原始0.7版本的筛选,移除每秒词数密度低于0.5的片段,从而提升数据集质量,适用于自动语音识别、机器翻译、跨语言风格映射和文本转语音等应用。
特点
该数据集的特点在于其音频片段的双语对齐,以及通过过滤过程减少了包含过量静默或背景噪声的片段,使得数据集在整体质量上得到显著提升。数据集包含独特的标识符、英语和法语的音频文件、文本转录、时长信息以及英法语片段的重叠比率。
使用方法
使用该数据集时,可以通过Hugging Face的datasets库进行加载。用户可以访问数据集中的音频和文本信息,进行自动语音识别、机器翻译等研究。数据集遵循CC BY-NC 4.0许可证,可用于非商业目的。
背景与挑战
背景概述
DuBLaB-en-fr-0.7-f-0.5数据集是由Amine Khelif研究人员构建的双语音频段数据集,创建于2025年,旨在服务于自动语音识别(ASR)、机器翻译、跨语言风格映射以及文本到语音(TTS)等领域。该数据集基于0.7版本构建,并通过过滤过程移除了每秒单词密度低于0.5的音频段,以减少过量的静音或背景噪音,从而提升数据集的整体质量。该数据集的构建与发布,对于推动多语言语音处理技术的发展和应用具有重要意义。
当前挑战
在研究领域问题上,DuBLaB-en-fr-0.7-f-0.5数据集面临的挑战包括提高跨语言语音识别的准确性、优化机器翻译的效率以及提升文本到语音转换的自然度。在构建过程中,研究人员遭遇的挑战主要涉及如何精确对齐不同语言的音频段,如何有效过滤噪声和静音,以及如何在保证数据质量的同时,确保数据集的规模足够大以支持深度学习模型的训练。
常用场景
经典使用场景
在自动语音识别(ASR)、机器翻译、跨语风格映射以及文本转语音(TTS)等领域,DuBLaB-en-fr-0.7-f-0.5数据集的应用显得尤为重要。该数据集以其英语和法语音频段落的对齐与提取特性,成为研究者在这些技术领域进行探索的基础资源。
衍生相关工作
基于DuBLaB-en-fr-0.7-f-0.5数据集,研究者们已开展了一系列相关工作,如开发新的跨语种语音识别模型、探索语音风格转换技术,以及改进语音合成算法等,推动了语音处理领域的研究进展和技术发展。
数据集最近研究
最新研究方向
近期,围绕DuBLaB-en-fr-0.7-f-0.5数据集的研究主要集中于自动语音识别、机器翻译、跨语种风格映射以及文本到语音的应用。学者们正深入探索该数据集在提升多语言语音处理技术中的效能,特别是在降低词汇密度阈值以提升数据质量的基础上,进一步挖掘其在交叉语言信息处理和语音合成领域的潜力。此数据集的应用研究不仅推动了语音识别技术的精确度,也为多语言交流的无障碍化提供了重要支持。
以上内容由遇见数据集搜集并总结生成


