有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
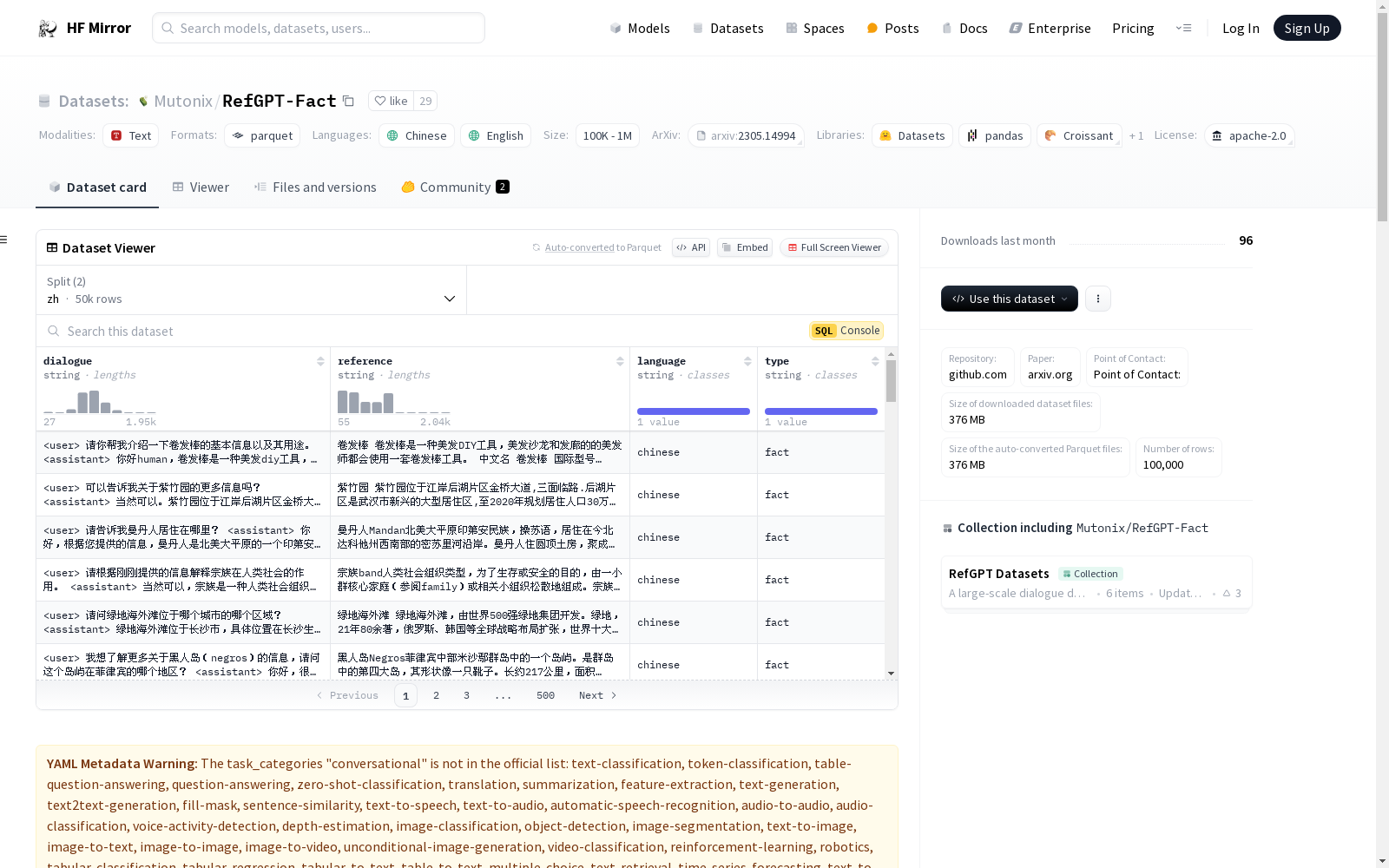
名称: RefGPT-Fact
语言: 中文, 英文
数据集大小: 10K<n<100K
任务类别: 对话式
数据集结构:
数据集内容:
使用注意事项:
许可证: Apache-2.0
LinkedIn Salary Insights Dataset
LinkedIn Salary Insights Dataset 提供了全球范围内的薪资数据,包括不同职位、行业、地理位置和经验水平的薪资信息。该数据集旨在帮助用户了解薪资趋势和市场行情,支持职业规划和薪资谈判。
www.linkedin.com 收录
TCIA
TCIA(The Cancer Imaging Archive)是一个公开的癌症影像数据集,包含多种癌症类型的医学影像数据,如CT、MRI、PET等。这些数据通常与临床和病理信息相结合,用于癌症研究和临床试验。
www.cancerimagingarchive.net 收录
OMIM (Online Mendelian Inheritance in Man)
OMIM是一个包含人类基因和遗传疾病信息的在线数据库。它提供了详细的遗传疾病描述、基因定位、相关文献和临床信息。数据集内容包括疾病名称、基因名称、基因定位、遗传模式、临床特征、相关文献引用等。
www.omim.org 收录
UniProt
UniProt(Universal Protein Resource)是全球公认的蛋白质序列与功能信息权威数据库,由欧洲生物信息学研究所(EBI)、瑞士生物信息学研究所(SIB)和美国蛋白质信息资源中心(PIR)联合运营。该数据库以其广度和深度兼备的蛋白质信息资源闻名,整合了实验验证的高质量数据与大规模预测的自动注释内容,涵盖从分子序列、结构到功能的全面信息。UniProt核心包括注释详尽的UniProtKB知识库(分为人工校验的Swiss-Prot和自动生成的TrEMBL),以及支持高效序列聚类分析的UniRef和全局蛋白质序列归档的UniParc。其卓越的数据质量和多样化的检索工具,为基础研究和药物研发提供了无可替代的支持,成为生物学研究中不可或缺的资源。
www.uniprot.org 收录
NuminaMath-CoT
数据集包含约86万道数学题目,每道题目的解答都采用思维链(Chain of Thought, CoT)格式。数据来源包括中国高中数学练习题以及美国和国际数学奥林匹克竞赛题目。数据主要从在线考试试卷PDF和数学讨论论坛收集。处理步骤包括从原始PDF中进行OCR识别、分割成问题-解答对、翻译成英文、重新对齐以生成CoT推理格式,以及最终答案格式化。
huggingface 收录