ABP
收藏Hugging Face2025-05-15 更新2025-05-16 收录
下载链接:
https://huggingface.co/datasets/smileying/ABP
下载链接
链接失效反馈官方服务:
资源简介:
Align Beyond Prompts是一个用于评估文本到图像生成模型与现实世界知识对应程度的全面基准,包含了2000多个覆盖六个不同现实场景的精心设计提示。
创建时间:
2025-05-14
原始信息汇总
数据集概述:Align Beyond Prompts (ABP)
基本信息
- 许可证: CC-BY-4.0
- 目标: 评估文本到图像(T2I)生成模型在超越显式提示的世界知识对齐方面的表现
数据集内容
- 规模: 包含超过2,000个精心设计的提示
- 覆盖场景: 6种不同的现实世界知识场景
- 物理场景
- 化学场景
- 动物场景
- 植物场景
- 人类场景
- 事实场景
评估指标
- ABPScore: 利用多模态大语言模型(MLLMs)评估生成图像与世界知识的对齐程度
- 与人类判断的Spearmans ρ相关性: 43.4
- 与人类判断的Kendalls τ相关性: 32.3
模型表现
-
评估模型: 8种流行的T2I模型
- SDXL
- SD3-M
- SD3.5-L
- CogView4
- Midjourney V6
- Gemini 2.0
- DALL-E 3
- GPT-4o
-
最佳表现模型: GPT-4o
- 总体得分: 0.8213
- 各场景得分:
- 物理场景: 0.8180
- 化学场景: 0.7702
- 动物场景: 0.8243
- 植物场景: 0.8421
- 人类场景: 0.8152
- 事实场景: 0.8581
改进方法
- Inference-Time Knowledge Injection (ITKI): 一种无需训练的策略
- 在200个挑战性样本上应用
- ABPScore提升约43%
搜集汇总
数据集介绍
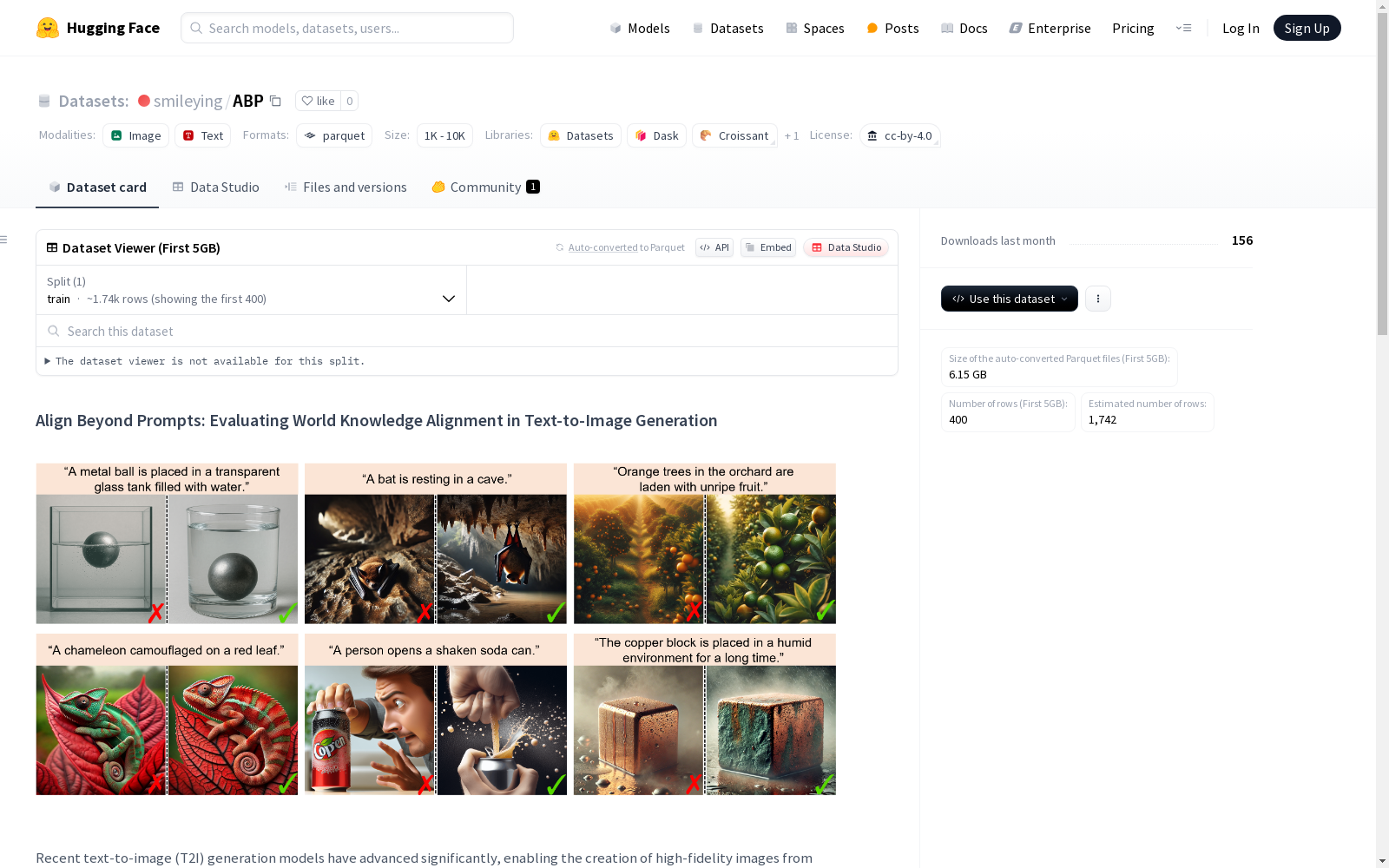
构建方式
在文本到图像生成领域,评估生成图像与真实世界知识的一致性是一个关键挑战。ABP数据集通过精心设计的构建流程,涵盖了2000多个涵盖六个不同场景的提示词,包括物理场景、化学场景、动物场景、植物场景、人类场景和事实场景。这些提示词经过严格筛选,确保能够全面评估生成模型在隐含知识对齐方面的表现。数据集的构建还引入了ABPScore这一创新性评估指标,该指标利用多模态大语言模型(MLLMs)来量化生成图像与真实世界知识的一致性,并与人类判断具有高度相关性。
特点
ABP数据集以其全面性和创新性评估方法脱颖而出。它不仅覆盖了多样化的现实世界场景,还通过ABPScore这一专门设计的评估指标,提供了对生成图像与隐含知识对齐程度的量化分析。数据集的独特之处在于其能够揭示当前最先进的文本到图像生成模型在整合常识性知识方面的局限性。例如,即使是GPT-4o这样的先进模型,在简单常识知识的整合上仍存在明显不足。此外,数据集还包含了一个无需训练的优化策略——推理时知识注入(ITKI),该策略在200个具有挑战性的样本上实现了约43%的ABPScore提升。
使用方法
使用ABP数据集进行文本到图像生成模型的评估,首先需要准备待评估的模型生成相应提示词的图像。随后,利用数据集提供的ABPScore指标对这些生成图像进行评估,该指标通过多模态大语言模型计算生成图像与真实世界知识的一致性分数。研究人员可以通过比较不同模型在六个场景中的表现,全面了解模型在隐含知识对齐方面的能力。对于希望改进模型性能的用户,可以尝试应用数据集提供的推理时知识注入策略,通过优化提示词或生成过程来提升知识对齐效果。数据集还提供了详细的评估结果表格,方便研究者进行横向比较和分析。
背景与挑战
背景概述
随着文本到图像(T2I)生成技术的迅猛发展,高保真度图像的生成能力已成为研究热点。然而,现有评估基准多聚焦于生成图像与提示词之间的显式对齐,忽视了与提示词之外的真实世界知识的隐性关联。为此,Align Beyond Prompts(ABP)数据集应运而生,旨在填补这一研究空白。该数据集由国际知名研究团队于近期构建,包含逾2000条精心设计的提示词,覆盖物理、化学、动植物、人类及事实场景等六大领域。通过引入创新的ABPScore评估指标,该数据集首次系统性地衡量了生成图像与世界知识的深层对齐程度,为T2I模型的认知能力评估提供了全新范式。研究显示,即便如GPT-4o等顶尖模型,在常识知识整合方面仍存在显著局限,这一发现对推动生成式AI的认知理解能力发展具有重要启示。
当前挑战
ABP数据集面临的核心挑战体现在两个维度:在领域问题层面,现有T2I模型对隐含世界知识的表达能力存在固有局限,例如化学键可视化或生物行为模拟等场景中,模型常产生违背科学常识的视觉输出;在构建技术层面,如何设计既能触发深层知识表征又不包含显式偏见的提示词构成重大挑战,研究团队需通过多轮专家验证确保提示体系的科学严谨性。此外,评估指标的设计需平衡计算效率与人类判断一致性,ABPScore虽展现出43.4%的斯皮尔曼相关系数突破,但对多模态大语言模型的依赖仍制约其广泛应用。这些挑战共同指向T2I技术亟待突破的认知建模瓶颈。
常用场景
经典使用场景
在文本到图像生成领域,ABP数据集被广泛用于评估生成图像与真实世界知识的一致性。通过涵盖物理场景、化学场景、动物场景、植物场景、人类场景和事实场景六大类别,ABP为研究者提供了一个全面的基准,用于测试模型在生成图像时是否能够准确反映常识性知识。例如,在评估GPT-4o等先进模型时,ABP揭示了这些模型在整合简单常识知识方面的局限性。
实际应用
ABP数据集在实际应用中具有广泛潜力,特别是在需要高精度图像生成的领域,如教育、医疗和娱乐。例如,在教育领域,ABP可以帮助评估生成的科普图像是否准确反映了科学知识;在医疗领域,ABP可以确保生成的解剖图像符合医学常识。此外,ABP提出的推理时知识注入(ITKI)策略,为优化生成模型提供了一种无需额外训练的高效方法,进一步拓展了其应用场景。
衍生相关工作
ABP数据集的推出催生了一系列相关研究,特别是在文本到图像生成模型的评估和优化方面。基于ABP的研究不仅改进了现有模型的常识整合能力,还推动了新型评估指标的发展。例如,ABPScore的提出为多模态评估提供了新思路,后续研究在此基础上进一步优化了评估的准确性和效率。此外,ITKI策略的引入也为推理时模型优化开辟了新的研究方向。
以上内容由遇见数据集搜集并总结生成


