MIND, Electronics, Prime Pantry
收藏arXiv2024-12-05 更新2024-12-11 收录
下载链接:
http://arxiv.org/abs/2412.04107v1
下载链接
链接失效反馈官方服务:
资源简介:
本文使用的数据集包括MIND、Electronics和Prime Pantry,这些数据集由香港城市大学和腾讯公司共同创建,用于评估序列推荐模型的性能。数据集涵盖了大量用户与物品的交互记录,分别包含9,667,540、5,137,265和115,004条交互数据。数据集的创建过程涉及对用户历史行为的序列化处理,旨在捕捉用户兴趣的动态变化。这些数据集主要应用于推荐系统领域,特别是解决冷启动问题和提升推荐效果。
The datasets used in this paper include MIND, Electronics, and Prime Pantry. These datasets were jointly created by City University of Hong Kong and Tencent Inc., and are employed to evaluate the performance of sequential recommendation models. They cover a large number of user-item interaction records, with 9,667,540, 5,137,265, and 115,004 interaction entries respectively. The creation process of these datasets involves serializing users' historical behaviors, aiming to capture the dynamic changes of user interests. These datasets are mainly applied in the field of recommendation systems, particularly for addressing cold-start problems and enhancing recommendation performance.
提供机构:
香港城市大学
创建时间:
2024-12-05
搜集汇总
数据集介绍
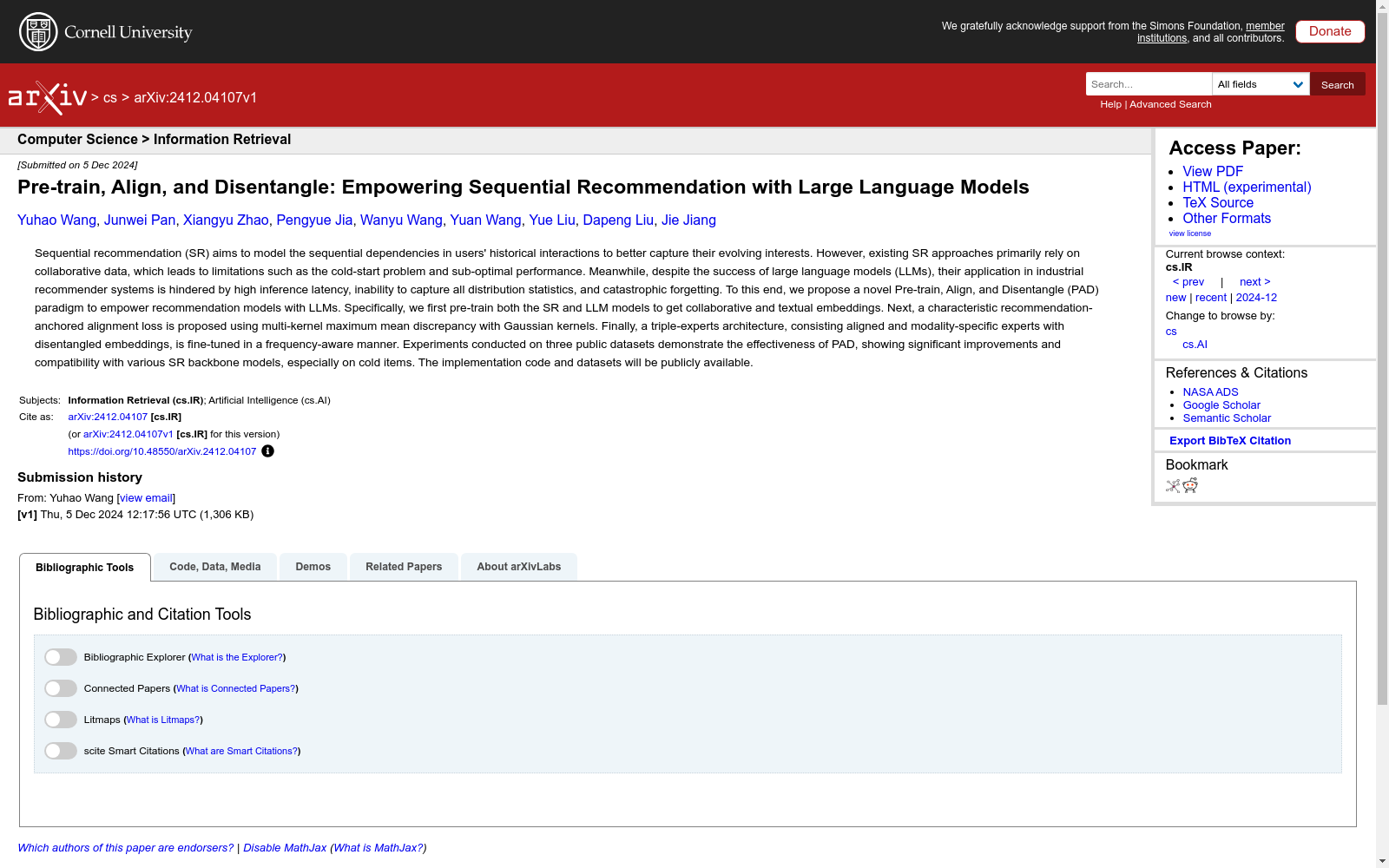
构建方式
该数据集通过结合大规模语言模型(LLMs)与序列推荐模型(SR)进行构建。首先,预训练LLM和SR模型,分别生成文本嵌入和协同嵌入。接着,通过多核最大均值差异(MK-MMD)与高斯核进行特征对齐,确保文本嵌入与协同嵌入在统计分布上的一致性。最后,采用三专家架构,包括对齐专家、LLM专家和推荐专家,通过频率感知的门控机制进行微调,以实现模态间的解耦和推荐性能的提升。
使用方法
该数据集可用于评估和训练序列推荐模型,特别是在处理冷启动问题和多模态数据融合方面。使用者可以通过预训练的LLM和SR模型生成嵌入,并利用对齐损失函数进行模态间的对齐。随后,通过三专家架构进行微调,结合频率感知的门控机制,优化推荐性能。实验结果表明,该方法在多个公开数据集上均表现出显著的性能提升,尤其在冷启动场景下效果更为突出。
背景与挑战
背景概述
MIND、Electronics和Prime Pantry数据集是由香港城市大学和腾讯公司联合开发的三组公开数据集,旨在推动序列推荐系统(Sequential Recommendation System, SRS)的研究。这些数据集的核心研究问题是如何利用用户历史交互数据中的序列依赖性来捕捉用户的动态兴趣,从而提升推荐系统的性能。研究团队提出了一种名为Pre-train, Align, and Disentangle(PAD)的新范式,通过结合大规模语言模型(LLMs)来增强序列推荐系统的能力。该研究的主要贡献在于解决了现有方法中存在的冷启动问题和性能瓶颈,尤其是在处理冷门物品时表现尤为突出。
当前挑战
这些数据集在构建和应用过程中面临多个挑战。首先,序列推荐系统依赖于协同过滤数据,这导致了冷启动问题,即新用户或新物品难以被有效推荐。其次,尽管大规模语言模型在自然语言处理中表现出色,但将其应用于工业推荐系统时,面临推理延迟高、无法捕捉所有数据分布统计信息以及灾难性遗忘等问题。此外,现有方法在数据对齐过程中使用非特征核函数,无法完全捕捉数据分布的统计特性,导致性能受限。最后,多模态学习中的灾难性遗忘问题也是一个关键挑战,即在对齐过程中,协同嵌入可能会丢失部分信息,影响推荐效果。
常用场景
经典使用场景
MIND、Electronics 和 Prime Pantry 数据集的经典使用场景主要集中在序列推荐任务中,旨在通过建模用户历史交互序列中的顺序依赖性,捕捉用户的动态兴趣。这些数据集通过结合大规模语言模型(LLMs)的能力,帮助推荐系统更好地理解用户的长期和短期偏好,尤其是在冷启动问题和稀疏数据场景中表现尤为突出。
解决学术问题
这些数据集解决了传统序列推荐模型在冷启动问题上的局限性,尤其是在处理新用户、新物品以及稀疏交互场景时表现不佳的问题。通过引入大规模语言模型,数据集能够更好地捕捉数据分布的统计特性,避免了传统方法中的灾难性遗忘问题,从而显著提升了推荐系统的性能。
实际应用
在实际应用中,MIND、Electronics 和 Prime Pantry 数据集被广泛用于电子商务平台和新闻推荐系统中。例如,在亚马逊的电子产品和Prime Pantry商品推荐中,数据集帮助系统更准确地预测用户的购买行为;在微软新闻推荐中,数据集则用于预测用户对新闻的点击行为。这些应用场景通过结合大规模语言模型的语义理解能力,显著提升了推荐的准确性和用户满意度。
数据集最近研究
最新研究方向
近年来,序列推荐系统(Sequential Recommendation, SR)领域的前沿研究逐渐聚焦于如何有效利用大规模语言模型(Large Language Models, LLMs)来提升推荐性能。传统的SR方法主要依赖协同过滤数据,存在冷启动问题和性能瓶颈。为此,最新的研究提出了一种名为Pre-train, Align, and Disentangle(PAD)的新范式,通过预训练、对齐和解耦三个阶段,将LLMs的能力引入推荐系统。该方法首先预训练SR模型和LLMs,获取协同和文本嵌入;接着通过多核最大均值差异(MK-MMD)进行特征对齐,并引入推荐锚定损失以避免灾难性遗忘;最后通过三专家架构进行微调,确保不同模态信息的有效融合。实验结果表明,PAD在冷启动项目上表现尤为突出,显著提升了推荐系统的整体性能。
相关研究论文
- 1Pre-train, Align, and Disentangle: Empowering Sequential Recommendation with Large Language Models香港城市大学 · 2024年
以上内容由遇见数据集搜集并总结生成


