symile-m3
收藏Hugging Face2024-11-14 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/arsaporta/symile-m3
下载链接
链接失效反馈官方服务:
资源简介:
Symile-M3 是一个多语言的多模态数据集,包含音频、图像和文本样本。数据集设计用于测试模型在三种不同高维数据类型之间捕捉高阶信息的能力。具体来说,数据集包含多个语言版本的音频、图像和文本,要求模型通过音频和文本共同预测图像,而单独的音频或文本不足以完成任务。数据集包含多个配置版本,每个版本有不同的语言数量和数据规模。每个样本包含语言代码、音频数据、图像数据、文本、目标类别名称及其ID等信息。
Symile-M3 is a multilingual multimodal dataset containing audio, image, and text samples. This dataset is designed to test a model's ability to capture high-order information across three distinct high-dimensional data modalities. Specifically, the dataset includes audio, image, and text samples in multiple language versions, requiring the model to jointly predict the image using both audio and text, where either audio alone or text alone is insufficient to complete the task. The dataset features multiple configuration variants, each with varying numbers of languages and data scales. Each sample contains information such as language code, audio data, image data, text, target category name, and its corresponding ID.
创建时间:
2024-11-12
原始信息汇总
Symile-M3 数据集概述
基本信息
- 许可证: CC BY-NC-SA 4.0
- 任务类别:
- 零样本分类
- 零样本图像分类
- 语言:
- 阿拉伯语 (ar)
- 希腊语 (el)
- 英语 (en)
- 印地语 (hi)
- 日语 (ja)
- 韩语 (ko)
- 泰卢固语 (te)
- 泰语 (th)
- 乌克兰语 (uk)
- 中文 (zh)
- 标签:
- 多模态
- 表示学习
- 多语言
- 数据集名称: Symile-M3
- 数据集大小: 10M < n < 100M
配置信息
symile-m3-5-m
- 特征:
lang: 字符串audio: 音频image: 图像text: 字符串cls: 字符串cls_id: int64target_text: 字符串
- 分割:
train: 725049451643.0 字节, 5000000 样本val: 35602464495.0 字节, 250000 样本test: 36207897705.0 字节, 250000 样本
- 下载大小: 798705714640 字节
- 数据集大小: 796859813843.0 字节
symile-m3-5-s
- 特征:
lang: 字符串audio: 音频image: 图像text: 字符串cls: 字符串cls_id: int64target_text: 字符串
- 分割:
train: 142185812397.0 字节, 1000000 样本val: 7217779117.0 字节, 50000 样本test: 7586183683.0 字节, 50000 样本
- 下载大小: 159628727029 字节
- 数据集大小: 156989775197.0 字节
symile-m3-5-xs
- 特征:
lang: 字符串audio: 音频image: 图像text: 字符串cls: 字符串cls_id: int64target_text: 字符串
- 分割:
train: 70410563197.0 字节, 500000 样本val: 3607295872.0 字节, 25000 样本test: 3624041386.0 字节, 25000 样本
- 下载大小: 80003029310 字节
- 数据集大小: 77641900455.0 字节
数据集结构
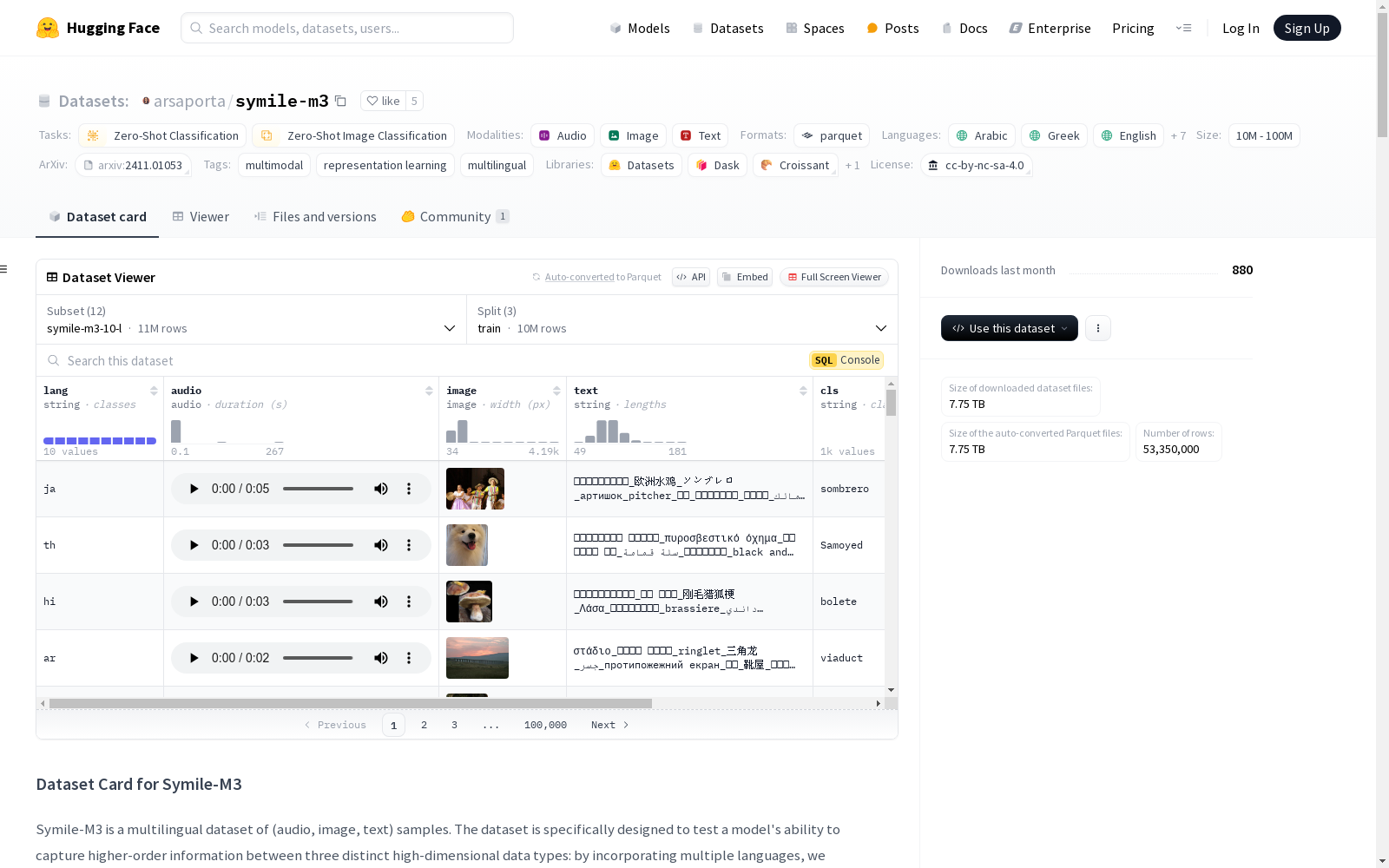
每个样本包含以下字段:
lang: 音频剪辑的语言代码audio: 音频数据path: Common Voice 文件名array: 原始音频波形sampling_rate: 采样率 (Hz)
image: PIL Image 对象 (RGB, 尺寸可变)text: 包含 w 个单词的文本 (每个语言一个单词), 用下划线分隔cls: 目标单词的英文类名cls_id: 类 ID (0 到 999)target_text: 目标单词 (音频语言中的类名)
数据集变体
- Symile-M3-2: 2 种语言 (英语, 希腊语)
- Symile-M3-5: 5 种语言 (英语, 希腊语, 印地语, 日语, 乌克兰语)
- Symile-M3-10: 10 种语言 (阿拉伯语, 希腊语, 英语, 印地语, 日语, 韩语, 泰卢固语, 泰语, 乌克兰语, 中文)
每个变体有四种大小:
- Large (l): 10M 训练样本, 500K 验证样本, 500K 测试样本
- Medium (m): 5M 训练样本, 250K 验证样本, 250K 测试样本
- Small (s): 1M 训练样本, 50K 验证样本, 50K 测试样本
- Extra Small (xs): 500K 训练样本, 25K 验证样本, 25K 测试样本
搜集汇总
数据集介绍
构建方式
Symile-M3数据集的构建过程体现了多模态数据融合的复杂性。该数据集通过从Common Voice中随机抽取音频片段,并结合ImageNet中的图像,生成了包含多种语言的文本。每个样本由音频、图像和文本三部分组成,其中文本包含多个语言的单词,且其中一个单词与音频语言和图像类别相关。这种构建方式确保了模型必须同时依赖音频和文本信息才能准确预测图像,从而提升了多模态学习的挑战性。
特点
Symile-M3数据集以其多语言、多模态的特性脱颖而出。它涵盖了10种语言,包括阿拉伯语、希腊语、英语、印地语、日语、韩语、泰卢固语、泰语、乌克兰语和中文。数据集中的每个样本包含音频、图像和文本三种模态,且文本部分由多种语言的单词组成。这种设计使得数据集不仅适用于零样本分类任务,还能有效评估模型在多模态表示学习中的表现。此外,数据集提供了多种规模和配置,便于研究者根据需求选择合适的数据量。
使用方法
使用Symile-M3数据集时,首先需安装必要的音频和图像处理库,如librosa、soundfile和pillow。通过Hugging Face的datasets库,可以轻松加载特定配置的数据集,例如`symile-m3-5-xs`。数据集支持流式加载,适合处理大规模数据。此外,用户还可以下载原始数据文件,包括ImageNet图像和Common Voice音频,以便进行更深入的分析和实验。数据集的CSV文件提供了详细的路径信息,便于直接访问原始数据。
背景与挑战
背景概述
Symile-M3数据集由Adriel Saporta等人于2024年提出,旨在解决多模态表示学习中的复杂问题。该数据集结合了音频、图像和文本三种高维数据类型,涵盖了阿拉伯语、希腊语、英语、印地语、日语、韩语、泰卢固语、泰语、乌克兰语和中文等十种语言。通过引入多语言环境,Symile-M3设计了一个任务,要求模型在仅依赖音频和文本的情况下预测图像,且单独依赖文本或音频无法完成任务。该数据集的构建基于Common Voice和ImageNet等公开数据集,其核心研究问题在于探索多模态数据之间的高阶信息交互,推动了多模态表示学习领域的发展。
当前挑战
Symile-M3数据集在构建和应用过程中面临多重挑战。首先,数据集的设计要求模型能够捕捉音频、图像和文本之间的联合信息,这对模型的表示学习能力提出了极高的要求。其次,多语言环境的引入增加了数据处理的复杂性,尤其是在不同语言之间的语义对齐和跨模态信息融合方面。此外,数据集的规模庞大,处理和管理海量数据对计算资源和存储能力提出了严峻挑战。在构建过程中,如何确保音频、图像和文本之间的高质量对齐,以及如何在不同语言之间保持数据的一致性,也是需要克服的技术难题。
常用场景
经典使用场景
Symile-M3数据集在多模态学习领域中被广泛用于零样本分类任务,尤其是在音频、图像和文本的联合信息捕捉方面。通过设计复杂的任务,该数据集要求模型在给定音频和文本的情况下,预测出最相关的图像,从而评估模型在多模态数据中的表现能力。这种任务设计不仅挑战了模型的跨模态理解能力,还推动了多模态表示学习的发展。
衍生相关工作
Symile-M3数据集衍生了许多经典的多模态学习研究工作,尤其是在零样本分类和跨模态检索领域。基于该数据集的研究成果,推动了多模态表示学习模型的优化,如对比学习、多模态Transformer等。这些工作不仅提升了模型在复杂任务中的表现,还为多模态数据的处理提供了新的方法论。
数据集最近研究
最新研究方向
在跨模态学习领域,Symile-M3数据集的最新研究方向聚焦于多语言环境下的零样本分类与图像检索任务。该数据集通过整合音频、图像和文本三种模态,构建了一个复杂的多语言任务场景,要求模型能够捕捉不同模态之间的高阶信息。当前研究热点包括如何提升模型在多语言环境下的跨模态表示学习能力,特别是在零样本设置下,如何通过联合信息推断出正确的图像类别。这一研究方向不仅推动了多模态表示学习的前沿发展,还为多语言环境下的智能应用提供了重要的技术支撑。
以上内容由遇见数据集搜集并总结生成


