multimodal_textbook
收藏魔搭社区2026-01-09 更新2025-01-11 收录
下载链接:
https://modelscope.cn/datasets/DAMO-NLP-SG/multimodal_textbook
下载链接
链接失效反馈官方服务:
资源简介:
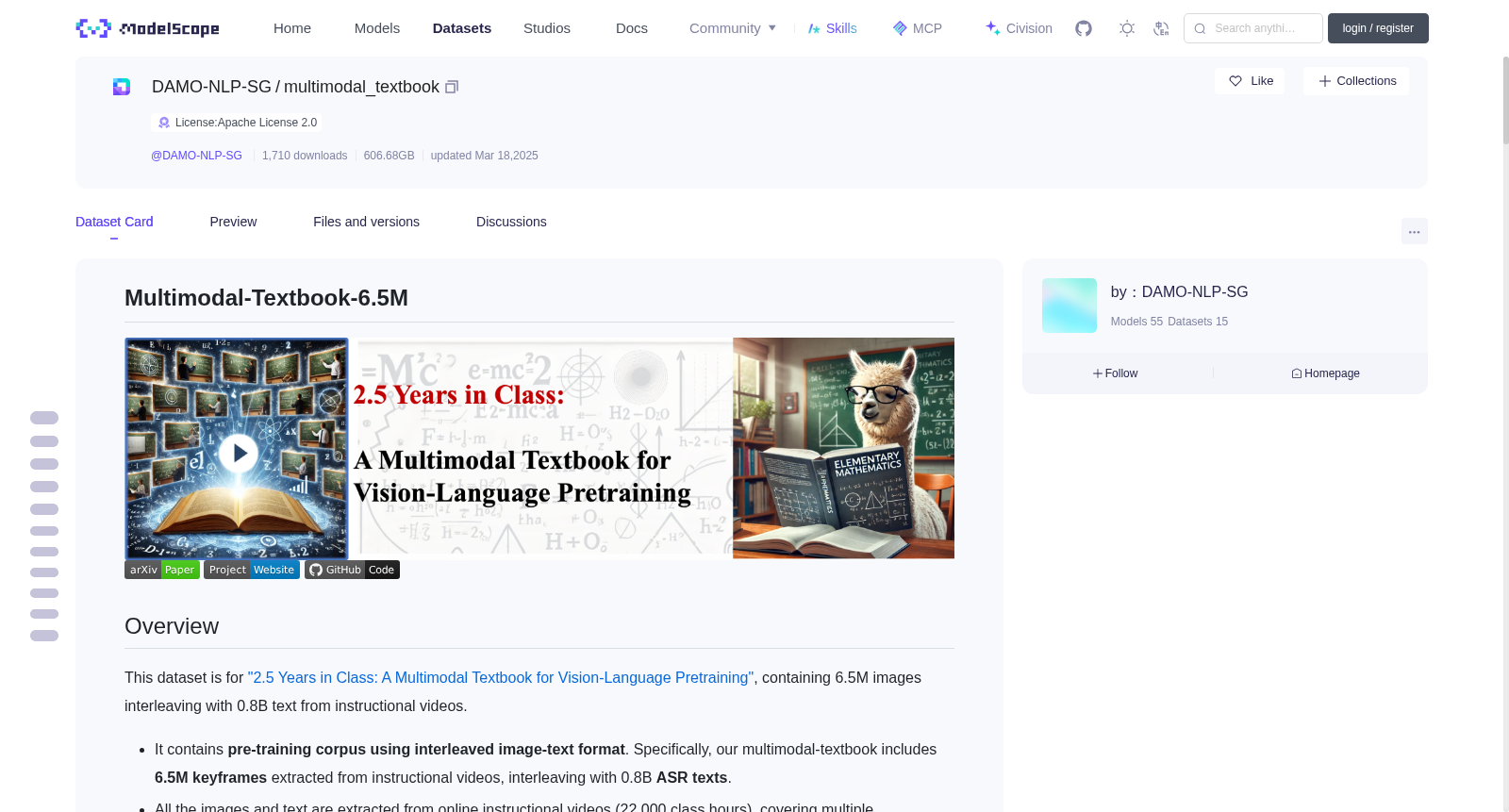
# Multimodal-Textbook-6.5M
<img src="./src/logo.png" alt="Image" style="width: 900px;">
[](https://arxiv.org/abs/2501.00958) [](https://multimodal-interleaved-textbook.github.io/) [](https://github.com/DAMO-NLP-SG/multimodal_textbook/tree/master)
## Overview
This dataset is for ["2.5 Years in Class: A Multimodal Textbook for Vision-Language Pretraining"](https://arxiv.org/abs/2501.00958), containing 6.5M images interleaving with 0.8B text from instructional videos.
- It contains **pre-training corpus using interleaved image-text format**. Specifically, our multimodal-textbook includes **6.5M keyframes** extracted from instructional videos, interleaving with 0.8B **ASR texts**.
- All the images and text are extracted from online instructional videos (22,000 class hours), covering multiple fundamental subjects, e.g., mathematics, physics, and chemistry.
- Our textbook corpus providing a more coherent context and richer knowledge for image-text aligning.
- Our code can be found in [Multimodal-Textbook](https://github.com/DAMO-NLP-SG/multimodal_textbook/tree/master).
Note: We have uploaded the annotation file (`./multimodal_textbook.json` and `multimodal_textbook_face_v1_th0.04.json`)and image folder (`./dataset_images_interval_7.tar.gz`), which contains keyframes, processed asr and ocr texts. For more details, please refer to [Using Multimodal Textbook](#using-multimodal-textbook). `multimodal_textbook_face_v1_th0.04.json` has filtered most human face images.
<img src="./src/page_fig.png" alt="Image" style="width: 900px;">
## Visualize Our Textbook
Due to the large size of the dataset (our complete textbook dataset is 11GB for JSON files and 0.7TB for images), we sampled 100 samples and the corresponding images and stored them in the `example_data` folder: `./example_data/textbook_sample_100.json`.
Each sample is stored in dict format as follows:
```
[
{'images': [keyframe1, None, keyframe2, None, keyframe3, None,.....],
'texts': [None, asr1, None, asr2, None, asr3,.....],
'text_ocr_list': [None, asr1+ocr1, None, asr2+ocr2, None, asr3+ocr3,.....],
'metadata': [...],
'image_num': 15,
'text_num': 425,
'token_num': 9065},
....
]
```
Just like [OBELICS](https://github.com/huggingface/OBELICS), the "images" and "texts" are arranged interleavely:
- "Images" list contains multiple keyframes and "None", where "None" represents that the current position is text.
- "texts" list contain multiple asr text. The position of "None" in "texts" list is image.
- "text_ocr_list": In addition to asr text, "text_ocr_list" also includes OCR text.
- "image_num", "text_num", "token_num": respectively represent the number of images, the number of asr text tokens, and the estimated total number of tokens in this sample.
To view our dataset more conveniently, we have written a jupyter notebook: `./llava/dataset/show_interleaved_dataset.ipynb`
```
cd example_data
show_interleaved_dataset.ipynb
```
In the notebook, you can see keyframes interleaving with text.
## Dataset Statistics
We utilize GPT-4o to synthesize our knowledge taxonomy with 3915 knowledge points across 6 subjects, which enabled us to automatically collect 159K English instructional videos based on this taxonomy.
Following our video-totextbook pipeline, we filter 53% low-quality or repetitive videos and retain 75K videos (22,697 class hours) with an average duration of 18 minutes.
Then we extract 6.5M keyframes and 0.75B text (ASR+OCR) tokens from these videos. To enhance training efficiency, we concatenate multiple video clips into a single sample, producing a total of 610K interleaved samples. Each sample contains an average of 10.7 keyframes and 1,230 text tokens. The detailed statistics for each subject are shown as follows:
<img src="./src/table.png" alt="Image" style="width: 900px;">
## Using Multimodal Textbook
### Description of Dataset
We provide the annotation file (json file) and corresponding images folder for textbook:
- Dataset json-file: `./multimodal_textbook.json` (600k samples ~ 11GB) and `multimodal_textbook_face_v1_th0.04.json`
- Dataset image_folder: `./dataset_images_interval_7.tar.gz` (6.5M image ~ 600GB) (**Due to its large size, we split it into 20 sub-files as `dataset_images_interval_7.tar.gz.part_00, dataset_images_interval_7.tar.gz.part_01, ...`**)
- Videometa_data: `video_meta_data/video_meta_data1.json` and `video_meta_data/video_meta_data2.json` contains the meta information of the collected videos, including video vid, title, description, duration, language, and searched knowledge points. Besides, we also provide `multimodal_textbook_meta_data.json.zip` records the textbook in its video format, not in the OBELICS format.
- Original video: You can downloaded original video using our provided video-id in `video_meta_data`.
### Learning about image_folder
After you download 20 image segmentation files (`dataset_images_interval_7.tar.gz.part_*`), you need to merge them first and then decompress. Please do not unzip a single segmentation file alone. It will lead to an error.
```
cd multimodal_textbook
cat dataset_images_interval_7.tar.gz.part_* > dataset_images_interval_7.tar.gz
tar -xzvf dataset_images_interval_7.tar.gz
```
After the above steps, you will get the image folder `dataset_images_interval_7`, which is approximately 600GB and contains 6 million keyframes. Each sub-folder in the `dataset_images_interval_7` is named with the video id.
### Naming Rule of keyframe
For each keyframe, its naming format rule is:
`video id@start-time_end-time#keyframe-number.jpg`. For example, the path and file name of a keyframe is `dataset_images_interval_7/-1uixJ1V-As/-1uixJ1V-As@10.0_55.0#2.jpg`.
This means that this image is extracted from the video (`-1uixJ1V-As`). It is the second keyframe (#2) in the video clip from 10.0 to 55.0 seconds. You can access the original video through [https://www.youtube.com/watch?v=-1uixJ1V-As](https://www.youtube.com/watch?v=-1uixJ1V-As).
### Learning about annotation file
The format of each sample in `multimodal_textbook_face_v1_th0.04.json` is as follows, that is, images and texts are interleaved:
```
"images": [
"/mnt/workspace/zwq_data/interleaved_dataset/dataset_images_interval_7/-1uixJ1V-As/-1uixJ1V-As@0.0_10.0#1.jpg",
null,
"/mnt/workspace/zwq_data/interleaved_dataset/dataset_images_interval_7/-1uixJ1V-As/-1uixJ1V-As@10.0_55.0#6.jpg",
null,
......
],
"texts": [
null,
"Hi everyone, and welcome to another lesson in our Eureka Tips for computers series .....",
null,
"I'm actually trying to use the number line to find the sum for each. So to start I'm going to use the paint tool to demonstrate. Let's use the number line for four plus five. We're going to start at four then we're going to count up five. One two three four five. That equals nine. Now let's do three plus six for the next one.",
....
],
```
Each sample has approximately 10.7 images and 1927 text tokens. You need to replace the each image path (`/mnt/workspace/zwq_data/interleaved_dataset/`) with your personal image folder path.
### Learning about metadata of instructional video
The format of the `./video_meta_data/video_meta_data1.json`:
```
{
"file_path": xxx,
"file_size (MB)": 85.54160022735596,
"file_name": "-r7-s1z3lFY.mp4",
"video_duration": 0,
"unique": true,
"asr_path": xxxx,
"asr_len": 2990,
"caption_path": xxx,
"caption_len": 0,
"search_keyword": "1.3B parameter size models comparison",
"title": "DeepSeek Coder LLM | A Revolutionary Coder Model",
"desc": "In this video, we are going to test out Deepseek Coder, a coding LLM.....,
"llm_response": " The video appears to be a detailed and technical analysis of DeepSeek Coder LLM..... ###Score: 10###",
"language": "en",
"asr is repetive": false,
"deepseek_score": 10,
"llama_score": 2,
"deepseek_score long context": 10
},
```
In addition, the `multimodal_textbook_meta_data.json.zip` records the textbook in video format. Each "video clip" is stored as a dict. Each sample includes multiple consecutive video clips from the same video. Sometimes one sample may also include video clips from different long videos. When a long video ends, it will store as `End of a Video`.
```
{'token_num': 1657,
'conversations': [
{
'vid': video id-1,
'clip_path': video id-1-clip1,
'asr': ASR transcribed from audio,
'extracted_frames': Extract keyframe sequences according to time intervals as [image1, image2,....].,
'image_tokens': xxx,
'token_num': xxx,
'refined_asr': Refine the original ASR,
'ocr_internvl_8b': OCR obtained using internvl_8b,
'ocr_image': the image does OCR come from,
'ocr_internvl_8b_deduplicates': xxx,
'keyframe_ssim': Keyframe sequence extracted according to SSIM algorithm,
'asr_token_num': xxx,
'ocr_qwen2_vl_72b': '...............'
},
{
'vid': video id-1,
'clip_path': video id-1-clip2,
'asr': ASR transcribed from audio,
'extracted_frames': Extract keyframe sequences according to time intervals as [image3, image4,....].,
.....
},
{
'vid': 'End of a Video',
'clip_path': xxxx,
'image_tokens': 0,
'token_num': 0
},
{
'vid': video id-2,
'clip_path': video id-2-clip1,
'asr': ASR transcribed from audio,
'extracted_frames': Extract keyframe sequences according to time intervals as [image5, image6,....].,
....
},
....
]
}
```
In this example above, the first two video clips are from the same video. Then the third dict represents the end of the current video. The fourth video clip is from a new video.
## Citation
```
@article{zhang20252,
title={2.5 Years in Class: A Multimodal Textbook for Vision-Language Pretraining},
author={Zhang, Wenqi and Zhang, Hang and Li, Xin and Sun, Jiashuo and Shen, Yongliang and Lu, Weiming and Zhao, Deli and Zhuang, Yueting and Bing, Lidong},
journal={arXiv preprint arXiv:2501.00958},
year={2025}
}
```
# Multimodal-Textbook-6.5M
<img src="./src/logo.png" alt="Image" style="width: 900px;">
[](https://arxiv.org/abs/2501.00958) [](https://multimodal-interleaved-textbook.github.io/) [](https://github.com/DAMO-NLP-SG/multimodal_textbook/tree/master)
## 概述
本数据集对应论文《2.5 Years in Class: A Multimodal Textbook for Vision-Language Pretraining》(https://arxiv.org/abs/2501.00958),包含从教学视频中提取的650万张交错搭配8亿文本的图像。
- 本数据集采用交错式图文格式构建预训练语料库。具体而言,本多模态教科书包含650万关键帧(keyframes),从教学视频中提取而来,并搭配8亿字的自动语音识别(Automatic Speech Recognition, ASR)文本。
- 所有图像与文本均来自在线教学视频(累计22000课时),覆盖数学、物理、化学等多个基础学科领域。
- 本教科书语料库可为图文对齐任务提供更连贯的上下文与更丰富的知识支撑。
- 本项目代码可在[Multimodal-Textbook](https://github.com/DAMO-NLP-SG/multimodal_textbook/tree/master)获取。
## 说明
注:本项目已上传标注文件(`./multimodal_textbook.json`与`multimodal_textbook_face_v1_th0.04.json`)及包含关键帧、处理后的自动语音识别与光学字符识别(Optical Character Recognition, OCR)文本的图像文件夹(`./dataset_images_interval_7.tar.gz`)。更多细节请参见[使用多模态教科书](#using-multimodal-textbook)章节。其中`multimodal_textbook_face_v1_th0.04.json`已过滤绝大多数人脸图像。
<img src="./src/page_fig.png" alt="Image" style="width: 900px;">
## 可视化本教科书
由于本数据集体量庞大(完整教科书数据集的JSON文件约11GB,图像文件约0.7TB),我们从中采样了100条样本及其对应图像,存储于`example_data`文件夹下的`./example_data/textbook_sample_100.json`文件中。
每条样本以字典格式存储,示例如下:
[
{'images': [keyframe1, None, keyframe2, None, keyframe3, None,.....],
'texts': [None, asr1, None, asr2, None, asr3,.....],
'text_ocr_list': [None, asr1+ocr1, None, asr2+ocr2, None, asr3+ocr3,.....],
'metadata': [...],
'image_num': 15,
'text_num': 425,
'token_num': 9065},
....
]
与[OBELICS](https://github.com/huggingface/OBELICS)类似,本数据集的`images`与`texts`列表采用交错排布方式:
- `images`列表包含多个关键帧与空值,其中空值代表当前位置为文本段。
- `texts`列表包含多条自动语音识别文本,`texts`列表中的空值位置对应图像。
- `text_ocr_list`:除自动语音识别文本外,`text_ocr_list`还包含光学字符识别文本。
- `image_num`、`text_num`与`token_num`:分别代表本样本中的图像数量、自动语音识别文本的Token(Token)数以及估算的总Token数。
为方便用户查看本数据集,我们编写了Jupyter Notebook工具:`./llava/dataset/show_interleaved_dataset.ipynb`
cd example_data
show_interleaved_dataset.ipynb
在该Notebook中,你可以查看交错排布的关键帧与文本。
## 数据集统计
我们使用GPT-4o构建了涵盖6个学科、共3915个知识点的知识分类体系,并基于该体系自动收集了15.9万条英文教学视频。
基于我们的视频转教科书流水线,我们过滤了53%的低质量或重复视频,最终保留7.5万条视频(累计22697课时),平均单条视频时长为18分钟。
随后我们从这些视频中提取了650万关键帧与7.5亿字的自动语音识别+光学字符识别文本Token。为提升训练效率,我们将多个视频片段拼接为单条样本,最终生成共61万个交错式样本。每条样本平均包含10.7个关键帧与1230个文本Token。各学科的详细统计数据如下:
<img src="./src/table.png" alt="Image" style="width: 900px;">
## 使用多模态教科书
### 数据集说明
我们提供了本教科书数据集的标注文件(JSON格式)与对应的图像文件夹:
- 数据集JSON文件:`./multimodal_textbook.json`(含60万条样本,约11GB)与`multimodal_textbook_face_v1_th0.04.json`
- 数据集图像文件夹:`./dataset_images_interval_7.tar.gz`(含650万张图像,约600GB)。**由于文件体量过大,我们将其拆分为20个分卷文件:`dataset_images_interval_7.tar.gz.part_00`、`dataset_images_interval_7.tar.gz.part_01`等**
- 视频元数据:`video_meta_data/video_meta_data1.json`与`video_meta_data/video_meta_data2.json`包含收集到的视频的元信息,包括视频ID(vid)、标题、描述、时长、语言以及搜索得到的知识点。此外,我们还提供了`multimodal_textbook_meta_data.json.zip`,该文件以视频格式而非OBELICS格式记录了本教科书数据集。
- 原始视频:你可以通过`video_meta_data`中提供的视频ID下载原始视频。
### 图像文件夹使用说明
在你下载完成20个图像分卷文件(`dataset_images_interval_7.tar.gz.part_*`)后,需先合并所有分卷再进行解压。请勿单独解压单个分卷文件,否则会导致错误。
cd multimodal_textbook
cat dataset_images_interval_7.tar.gz.part_* > dataset_images_interval_7.tar.gz
tar -xzvf dataset_images_interval_7.tar.gz
完成上述步骤后,你将得到图像文件夹`dataset_images_interval_7`,其大小约为600GB,内含600万张关键帧。`dataset_images_interval_7`中的每个子文件夹均以视频ID命名。
### 关键帧命名规则
每张关键帧的命名格式规则如下:
`视频ID@起始时间_结束时间#关键帧序号.jpg`。例如,某关键帧的路径与文件名为`dataset_images_interval_7/-1uixJ1V-As/-1uixJ1V-As@10.0_55.0#2.jpg`。
该文件名表示该图像来自视频`-1uixJ1V-As`,是该视频10.0秒至55.0秒片段中的第2个关键帧(#2)。你可通过[https://www.youtube.com/watch?v=-1uixJ1V-As](https://www.youtube.com/watch?v=-1uixJ1V-As)访问该原始视频。
### 标注文件说明
`multimodal_textbook_face_v1_th0.04.json`中每条样本的格式如下,即图像与文本交错排布:
"images": [
"/mnt/workspace/zwq_data/interleaved_dataset/dataset_images_interval_7/-1uixJ1V-As/-1uixJ1V-As@0.0_10.0#1.jpg",
null,
"/mnt/workspace/zwq_data/interleaved_dataset/dataset_images_interval_7/-1uixJ1V-As/-1uixJ1V-As@10.0_55.0#6.jpg",
null,
......
],
"texts": [
null,
"Hi everyone, and welcome to another lesson in our Eureka Tips for computers series .....",
null,
"I'm actually trying to use the number line to find the sum for each. So to start I'm going to use the paint tool to demonstrate. Let's use the number line for four plus five. We're going to start at four then we're going to count up five. One two three four five. That equals nine. Now let's do three plus six for the next one.",
....
],
每条样本平均包含10.7个图像与1927个文本Token。你需将示例中的图像路径前缀(`/mnt/workspace/zwq_data/interleaved_dataset/`)替换为你本地的图像文件夹路径。
### 教学视频元数据说明
`./video_meta_data/video_meta_data1.json`的格式如下:
{
"file_path": xxx,
"file_size (MB)": 85.54160022735596,
"file_name": "-r7-s1z3lFY.mp4",
"video_duration": 0,
"unique": true,
"asr_path": xxxx,
"asr_len": 2990,
"caption_path": xxx,
"caption_len": 0,
"search_keyword": "1.3B parameter size models comparison",
"title": "DeepSeek Coder LLM | A Revolutionary Coder Model",
"desc": "In this video, we are going to test out Deepseek Coder, a coding LLM.....,
"llm_response": " The video appears to be a detailed and technical analysis of DeepSeek Coder LLM..... ###Score: 10###",
"language": "en",
"asr is repetive": false,
"deepseek_score": 10,
"llama_score": 2,
"deepseek_score long context": 10
},
此外,`multimodal_textbook_meta_data.json.zip`以视频格式记录了本教科书数据集。每个“视频片段”以字典形式存储。每条样本可包含来自同一视频的多个连续视频片段,有时也可包含来自不同长视频的片段。当一个长视频结束时,会以`End of a Video`标记。
{'token_num': 1657,
'conversations': [
{
'vid': video id-1,
'clip_path': video id-1-clip1,
'asr': ASR transcribed from audio,
'extracted_frames': Extract keyframe sequences according to time intervals as [image1, image2,....].,
'image_tokens': xxx,
'token_num': xxx,
'refined_asr': Refine the original ASR,
'ocr_internvl_8b': OCR obtained using internvl_8b,
'ocr_image': the image does OCR come from,
'ocr_internvl_8b_deduplicates': xxx,
'keyframe_ssim': Keyframe sequence extracted according to SSIM algorithm,
'asr_token_num': xxx,
'ocr_qwen2_vl_72b': '...............'
},
{
'vid': video id-1,
'clip_path': video id-1-clip2,
'asr': ASR transcribed from audio,
'extracted_frames': Extract keyframe sequences according to time intervals as [image3, image4,....].,
.....
},
{
'vid': 'End of a Video',
'clip_path': xxxx,
'image_tokens': 0,
'token_num': 0
},
{
'vid': video id-2,
'clip_path': video id-2-clip1,
'asr': ASR transcribed from audio,
'extracted_frames': Extract keyframe sequences according to time intervals as [image5, image6,....].,
....
},
....
]
}
在上述示例中,前两个视频片段来自同一视频,第三个字典代表当前视频的结束,第四个视频片段则来自新的视频。
## 引用
@article{zhang20252,
title={2.5 Years in Class: A Multimodal Textbook for Vision-Language Pretraining},
author={Zhang, Wenqi and Zhang, Hang and Li, Xin and Sun, Jiashuo and Shen, Yongliang and Lu, Weiming and Zhao, Deli and Zhuang, Yueting and Bing, Lidong},
journal={arXiv preprint arXiv:2501.00958},
year={2025}
}
提供机构:
maas
创建时间:
2025-01-20
搜集汇总
数据集介绍
背景与挑战
背景概述
multimodal_textbook数据集包含6.5M图像和0.8B文本,以交错格式排列,覆盖多个基础学科,适用于视觉-语言预训练任务。数据集提供了详细的元数据和注释文件,便于用户使用和分析。
以上内容由遇见数据集搜集并总结生成


