myspellchecker-resources
收藏Hugging Face2025-12-20 更新2025-12-21 收录
下载链接:
https://huggingface.co/datasets/thettwe/myspellchecker-resources
下载链接
链接失效反馈官方服务:
资源简介:
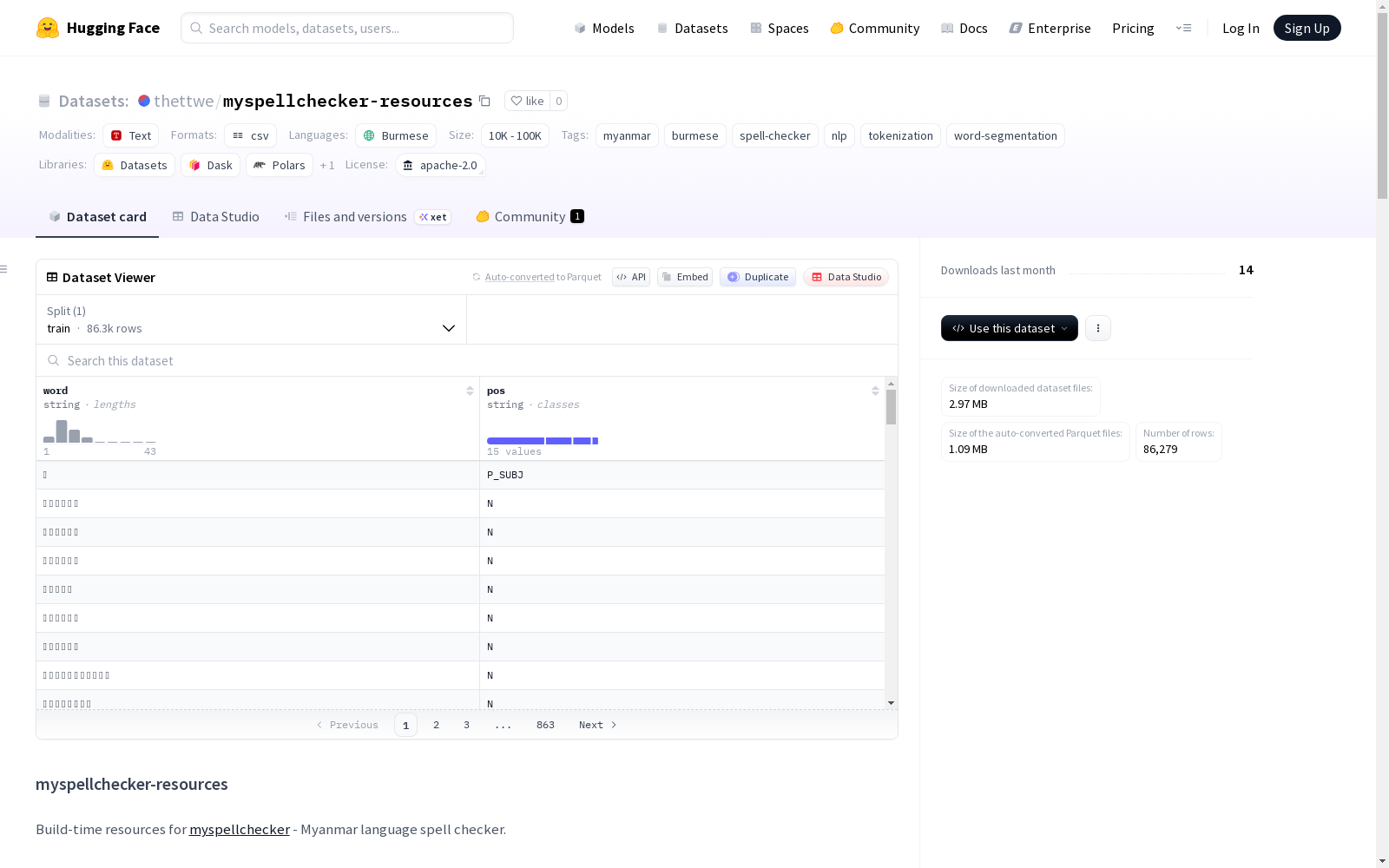
该数据集是用于缅甸语拼写检查器(myspellchecker)的构建时资源,包含三个主要部分:1) segmentation/目录下的内存映射字典(segmentation.mmap),用于缅甸语分词,使用Viterbi算法计算单字和双字的对数概率;2) models/目录下的条件随机场模型(wordseg_c2_crf.crfsuite),用于基于音节的词标记化;3) pos_data/目录下的词性标注数据(myspellcheck_pos.csv),包含49,681个缅甸语单词的词性标注信息,用于语法检查。数据集还详细描述了数据集的来源、技术说明、使用方法和缓存位置等信息。
创建时间:
2025-12-16
原始信息汇总
myspellchecker-resources 数据集概述
数据集基本信息
- 数据集名称: myspellchecker-resources
- 许可证: Apache-2.0
- 语言: 缅甸语 (my)
- 标签: myanmar, burmese, spell-checker, nlp, tokenization, word-segmentation
- 数据规模: 100M<n<1B
- 描述: 为缅甸语拼写检查工具 myspellchecker 提供的构建时资源。
主要内容
segmentation/
- segmentation.mmap (100MB): 包含用于缅甸语分词(基于Viterbi算法)的单字和双字对数概率的内存映射字典。
models/
- wordseg_c2_crf.crfsuite (3.2MB): 用于基于音节的词语切分的条件随机场模型。
pos_data/
- myspellcheck_pos.csv: 用于语法检查的词性标注缅甸语词汇表,包含49,681个条目。
词性标注分布
| 标签 | 描述 | 数量 |
|---|---|---|
| N | 名词 | 26,871 |
| V | 动词 | 11,770 |
| ADJ | 形容词 | 7,157 |
| ADV | 副词 | 3,013 |
| P | 助词 | 195 |
| NUM | 数词 | 165 |
| CONJ | 连词 | 163 |
| PRO | 代词 | 137 |
| P_MOD | 修饰助词 | 73 |
| ABB | 缩写 | 56 |
| INT | 感叹词 | 50 |
| P_SENT | 句末助词 | 19 |
| P_LOC | 方位助词 | 7 |
| P_SUBJ | 主语助词 | 3 |
| P_OBJ | 宾语助词 | 2 |
| 总计 | 49,681 |
技术说明
.bin 到 .mmap 的转换
分词字典已从基于pickle的.bin文件转换为内存映射的.mmap格式,以实现:
- 内存效率: 惰性加载,无需将整个文件载入RAM。
- 分叉安全: 为多进程处理提供写时复制语义。
- 更快启动: 无需pickle反序列化开销。
- 安全性: 消除了pickle任意代码执行漏洞。
- 减小体积: 合并后为100MB,而单独的.bin文件为315MB。
致谢与来源
myWord 项目
分词字典 (segmentation.mmap) 源自 myWord 项目:
- 仓库: https://github.com/ye-kyaw-thu/myWord
- 作者: Ye Kyaw Thu
- 描述: 使用统计方法和Viterbi算法进行缅甸语分词。
myTokenize 项目
CRF模型和分词框架基于 myTokenize 库:
- 仓库: https://github.com/ye-kyaw-thu/myTokenize
- 作者: Ye Kyaw Thu
词性标注数据来源
词性标注词汇表 (myspellcheck_pos.csv) 是多个来源的组合:
- Ornagai 词典
- 网站: https://www.ornagai.com
- 描述: 带有词性标注的综合性缅英词典。
- 缅甸语词汇列表
- 仓库: https://github.com/myanmartools/myanmar-words
- 描述: 开源的缅甸语词汇集合。
- myPOS 语料库
- 仓库: https://github.com/ye-kyaw-thu/myPOS
- 作者: Ye Kyaw Thu
- 描述: 缅甸语词性标注语料库(版本3.0)。
使用方式
资源由myspellchecker自动下载: python from myspellchecker import SpellChecker
资源在首次使用时自动下载
checker = SpellChecker()
缓存位置
下载的资源缓存于:~/.cache/myspellchecker/resources/
许可证
这些资源按照原始项目的相同许可证条款提供。请参考原始仓库以获取具体的许可证信息。
搜集汇总
数据集介绍
构建方式
该数据集作为缅甸语拼写检查工具myspellchecker的构建资源,其核心内容整合了多个开源项目的数据成果。词频词典来源于myWord项目的统计模型,通过Viterbi算法计算单字与双字对数概率,并优化为内存映射格式以提升效率。词性标注数据则融合了Ornagai词典、Myanmar Words词表及myPOS语料库的标注结果,经过系统化整合形成统一的词性标记集合。分词模型基于myTokenize库的条件随机场框架训练而成,专为音节级分词任务设计。整个构建过程注重数据格式的统一与存储优化,将原始分散的二进制文件转换为高效、安全且易于加载的结构化资源。
使用方法
使用该数据集时,开发者无需手动下载或配置资源文件。通过导入myspellchecker库并初始化拼写检查器对象,系统会自动从远程仓库获取所需的词典、模型及标注数据,并缓存于用户主目录的特定路径下。这种设计使得集成过程极为简洁,用户只需关注拼写检查功能的应用逻辑,而无需处理底层数据的存储与加载细节。缓存机制确保了后续使用的快速响应,同时允许用户根据需要清理或更新资源。数据集的使用完全遵循原始项目的许可协议,为缅甸语文本处理任务提供了即插即用的基础设施支持。
背景与挑战
背景概述
缅甸语作为低资源语言,其自然语言处理研究长期面临工具与数据稀缺的挑战。myspellchecker-resources数据集由缅甸语研究者Ye Kyaw Thu及其合作者于近年构建,旨在为缅甸语拼写检查器提供核心资源支持。该数据集整合了来自myWord项目的分词词典、myTokenize库的音节分词模型,以及融合Ornagai词典与myPOS语料库的词性标注数据,共计包含约五万个标注词条。其创建聚焦于解决缅甸语文本处理中的自动分词、词性标注及拼写纠错等基础性问题,为缅甸语信息处理系统的开发奠定了关键的数据基础,显著推动了该语言在计算语言学领域的研究进展。
当前挑战
在领域问题层面,缅甸语拼写检查需克服其语言特有的挑战:文本为连续书写,缺乏显式词边界,使得自动分词成为首要难题;同时,语言形态复杂且公开标注语料稀缺,导致词性标注与语法错误检测模型训练困难。在构建过程中,数据集整合面临多重挑战:需将分散的原始数据(如.pickle格式的分词概率文件)高效转换为内存映射格式以优化加载性能与安全性;必须协调多源数据(如不同词典与语料库)的许可协议与标注标准,确保合并后的一致性;此外,处理大规模二进制文件(如100MB的.mmap文件)的分发与自动缓存机制,也对工程实现提出了较高要求。
常用场景
经典使用场景
在缅甸语自然语言处理领域,该数据集为文本预处理提供了关键支持。其核心应用场景在于缅甸语拼写检查系统的构建,通过整合词频统计、条件随机场模型及词性标注数据,实现了对缅甸语文本的自动分词、语法纠错和拼写验证。这一过程不仅提升了文本处理的准确性,还为后续的语言分析任务奠定了坚实基础,尤其在处理缅甸语这种资源稀缺语言时,展现了显著的技术价值。
解决学术问题
该数据集有效解决了缅甸语自然语言处理中的若干核心学术问题。首先,它通过内存映射词典和统计模型,缓解了缅甸语因缺乏标准分词规范而导致的文本分割难题。其次,基于条件随机场的音节级分词模型,优化了复杂语言结构的处理精度。此外,丰富的词性标注数据为语法分析和语义理解研究提供了可靠标注,推动了低资源语言处理技术的理论进展,填补了该领域的数据空白。
实际应用
在实际应用中,该数据集支撑了多种缅甸语文本处理工具的开发和优化。例如,它被集成到拼写检查器中,用于文档编辑、教育辅助和内容审核场景,帮助用户检测并纠正拼写错误。同时,其分词和词性标注功能可应用于搜索引擎、机器翻译系统和社交媒体分析,提升信息检索的准确性和语言服务的智能化水平,为缅甸语数字生态的建设提供了技术基础设施。
数据集最近研究
最新研究方向
在缅甸语自然语言处理领域,低资源语言的智能化工具开发正成为前沿焦点。myspellchecker-resources数据集整合了基于统计方法的词分割字典、条件随机场音节标记模型及词性标注数据,为缅甸语拼写检查与语法分析提供了核心支持。当前研究热点集中于利用此类资源优化多任务学习框架,以提升缅甸语文本处理的准确性与效率,尤其在社交媒体文本纠错、教育技术应用及跨语言信息检索中展现出重要价值。该数据集的开放共享不仅推动了缅甸语NLP工具链的标准化进程,也为全球低资源语言技术发展提供了可借鉴的范例。
以上内容由遇见数据集搜集并总结生成


