CoralVQA
收藏arXiv2025-07-15 更新2025-08-15 收录
下载链接:
https://huggingface.co/datasets/CoralReefData/CoralVQA
下载链接
链接失效反馈官方服务:
资源简介:
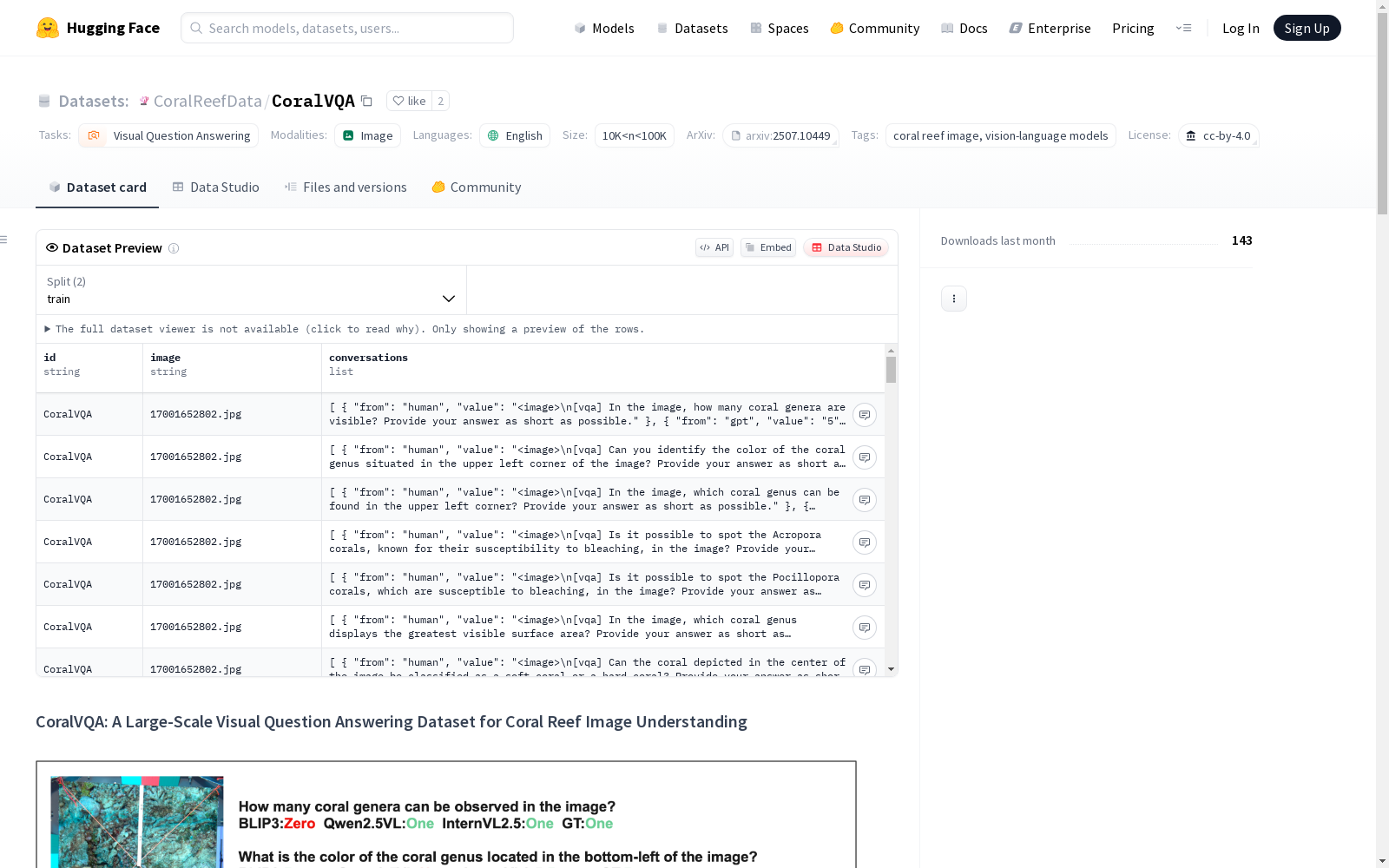
CoralVQA是一个大规模的视觉问答数据集,旨在帮助理解珊瑚礁图像。该数据集包含了来自三个海洋的67种珊瑚属的12805张真实世界珊瑚图像,以及277653个问答对,这些问答对全面评估了生态和健康相关的条件。为了构建这个数据集,我们开发了一个半自动的数据构建流程,与海洋生物学家合作,以确保数据的质量和可扩展性。CoralVQA为研究视觉语言推理在珊瑚礁图像背景下的应用提供了全面的标准。通过评估几个最先进的LVLMs,我们发现了一些关键的局限性和机会。这些见解为未来的LVLM发展奠定了基础,特别是支持珊瑚保护工作。
CoralVQA is a large-scale visual question answering (VQA) dataset developed to advance the understanding of coral reef imagery. This dataset includes 12,805 real-world coral images covering 67 coral genera across three oceans, paired with 277,653 question-answer pairs that comprehensively assess ecological and health-related conditions. To construct this dataset, we devised a semi-automated data pipeline and collaborated with marine biologists to ensure data quality and scalability. CoralVQA offers a comprehensive benchmark for researching visual-language reasoning in the context of coral reef images. After evaluating several state-of-the-art large vision-language models (LVLMs), we uncovered several key limitations and opportunities. These findings lay a solid foundation for future LVLM development, especially to support coral conservation efforts.
提供机构:
北京邮电大学
创建时间:
2025-07-15
搜集汇总
数据集介绍
构建方式
CoralVQA数据集的构建采用了一种半自动化的流程,结合了海洋生物学家的专业知识以确保数据的专业性和可扩展性。首先,从多个来源收集了12,805张真实的珊瑚礁图像,覆盖了3个海洋区域的67个珊瑚属。随后,通过系统的标签清理和重新注释过程,去除非珊瑚类别并统一注释标准。接着,提取了丰富的视觉和生态属性,并利用GPT-4o API自动生成问题-答案对。最后,通过人工验证、交叉检查和专家抽样检查三个阶段的严格质量控制,确保了数据集的准确性和多样性。
特点
CoralVQA数据集包含12,805张高质量的珊瑚礁图像和277,653个问题-答案对,覆盖了16个不同维度的问题类型。其特点在于广泛的海洋区域覆盖和丰富的珊瑚属多样性,使其成为迄今为止分类学上最为多样化的珊瑚数据集。此外,数据集中的问题分为基本视觉属性和生态及健康相关属性两大类,既有开放式问题也有封闭式问题,为视觉语言模型在珊瑚礁分析中的性能评估提供了全面的基准。
使用方法
CoralVQA数据集可用于评估和提升视觉语言模型在珊瑚礁图像理解中的性能。研究人员可以通过该数据集进行多种任务,如珊瑚属识别、健康状态评估和生态分析。数据集分为训练集、测试集和跨区域数据集,便于进行标准性能测试和模型泛化能力评估。此外,数据集还包含一个专门用于评估珊瑚白化覆盖率的子集,可用于复杂推理任务的性能测试。使用该数据集时,建议结合提供的详细实验设置和评估指标,以确保实验的可重复性和结果的可靠性。
背景与挑战
背景概述
CoralVQA数据集由北京邮电大学等机构的研究团队于2025年创建,旨在通过视觉问答技术解决珊瑚礁生态监测中的专业壁垒问题。作为首个面向珊瑚礁图像理解的大规模VQA数据集,它整合了来自三大洋67个属的12,805张真实珊瑚图像及277,653个多维问答对,覆盖16个生态健康评估维度。该数据集创新性地采用海洋生物学家参与的半自动构建流程,突破了传统珊瑚数据集仅支持分类/分割任务的局限,为跨模态推理在海洋保护领域的应用建立了新基准。其跨区域采集策略和精细的属级生物分类体系,显著提升了珊瑚研究数据的 taxonomic 多样性和地理代表性。
当前挑战
领域适应性方面,珊瑚图像存在形态多样性高、遮挡复杂等特性,现有视觉语言模型在珊瑚属识别(准确率81.69%)、数量统计(35.54%)等开放性问题表现显著劣于通用图像任务。数据构建过程中需解决两大核心难题:一是标注标准不统一问题,需清理50,200个非珊瑚标注并按林奈分类体系重新标注97,395个实例;二是多维问题生成的专业性要求,需设计16类生态评估维度并通过GPT-4o多模态API实现视觉-文本对齐,最终经三阶段人工验证使错误率低于5%。模型跨区域测试性能下降超30%,凸显域外泛化挑战。
常用场景
经典使用场景
CoralVQA数据集在珊瑚礁生态监测与保护研究中具有重要应用价值。该数据集通过视觉问答(VQA)任务,为研究人员提供了一个多维度评估珊瑚礁健康状况的平台。其经典使用场景包括珊瑚属种识别、健康状态评估(如白化程度)、生长状况分析以及共生关系检测等。数据集涵盖的16个问题维度能够全面覆盖珊瑚礁监测中的关键科学问题,为跨学科研究提供了标准化评估框架。
衍生相关工作
该数据集已衍生出多个重要研究方向:基于跨海域泛化能力的模型优化研究揭示了地理分布对珊瑚特征识别的影响;针对白化覆盖率估算的专用子集推动了复杂视觉推理方法的发展;其半自动标注流程被拓展应用于红树林等海洋生态系统。相关工作发表在CVPR等顶级会议,其中InternVL2.5等模型在基准测试中展现的局限性,直接促进了领域自适应预训练技术的创新。
数据集最近研究
最新研究方向
随着全球气候变化对珊瑚礁生态系统的影响日益加剧,CoralVQA数据集的推出为珊瑚礁监测与保护研究开辟了新的技术路径。该数据集通过整合多海域、多属种的珊瑚图像与多维生态问题,为视觉语言模型在海洋生态领域的专业化应用建立了首个基准测试平台。近期研究聚焦于三个前沿方向:一是探索跨海域珊瑚形态特征的迁移学习机制,以解决模型在印度洋与太平洋等未训练区域的泛化难题;二是开发基于层次化注意力机制的健康状态评估模型,针对白化覆盖率等复杂生态指标进行细粒度推理;三是构建融合海洋生物学知识的提示工程框架,通过注入珊瑚分类学先验知识来提升属种识别准确率。这些研究不仅推动了计算机视觉在生态保护中的深度应用,更为《联合国海洋科学促进可持续发展十年》计划中的智能监测目标提供了关键技术支撑。
相关研究论文
- 1CoralVQA: A Large-Scale Visual Question Answering Dataset for Coral Reef Image Understanding北京邮电大学 · 2025年
以上内容由遇见数据集搜集并总结生成


