Marker
收藏Hugging Face2025-08-27 更新2025-08-28 收录
下载链接:
https://huggingface.co/datasets/Just-ln-Case/Marker
下载链接
链接失效反馈官方服务:
资源简介:
Marker是一个多模态基准数据集,用于评估AI模型在俄罗斯学校水平任务上的表现。它涵盖了七个学科:历史、艺术、地理、位置、数学、物理(选择题)和物理(开放式)。每个任务都结合了教科书、地图和图表中的图像与俄语中的问题和答案选项。Marker旨在用于跨模态理解、视觉问答和教育人工智能的研究。
创建时间:
2025-08-26
原始信息汇总
MARKER 数据集概述
数据集基本信息
- 数据集名称:MARKER(Multimodal Assessment of Russian Knowledge in Educational Realms)
- 许可证:MIT
- 语言:俄语(ru)
- 标签:历史、艺术、物理、数学、位置、地理、EGE、OGE、学校、大学、VLM
- 数据规模:1K < n < 10K
数据集配置与结构
数据集包含7个配置(config),每个配置对应一个学科主题:
配置详情
-
art
- 特征:Image(图像)、IAnswer(图像)、ITask(字符串)、TTask(字符串)、TAnswer(字符串)、column_type(字符串)、TChoices(字符串列表)
- 评估集:621个样本,大小357.86 MB
-
geo
- 特征:Image(二进制列表)、TAnswer(字符串)、TTask(字符串)、TChoices(字符串)
- 评估集:321个样本,大小33.57 MB
-
history
- 特征:Image(图像)、class(int64)、TTask(字符串)、TAnswer(字符串)、column_type(字符串)、TChoices(字符串列表)
- 评估集:1638个样本,大小698.01 MB
-
locations
- 特征:Coords(float64列表)、TTask(字符串)、TAnswer(字符串)、Image(图像)、TChoices(字符串列表)
- 评估集:344个样本,大小251.51 MB
-
math
- 特征:Image(二进制列表)、TTask(字符串)、TAnswer(字符串)、TChoices(字符串列表)
- 评估集:458个样本,大小38.36 MB
-
physics
- 特征:IAnswer(图像)、Image(图像)、ITask(图像)、TAnswer(字符串)、TTask(字符串)、TChoices(字符串列表)
- 评估集:195个样本,大小23.42 MB
-
physics-open-ended
- 特征:IAnswer(图像)、Image(图像)、ITask(图像)、TTask(字符串)、TAnswer(字符串)
- 评估集:67个样本,大小55.28 MB
共享数据字段
所有配置均包含以下字段:
TTask:任务描述(俄语字符串)Image:单图像为PIL.Image对象,多图像为base64编码字符串列表TChoices:答案选项列表(多选题任务,开放题不存在)TAnswer:正确答案(字符串)
支持的任务与评估
任务类型
| 学科 | 任务类型 | 任务描述 | 评估指标 |
|---|---|---|---|
| 历史 | 多选题 | 从图像识别世纪/人物/事件 | 准确率 |
| 艺术 | 多选题 | 分类艺术品风格/作者/标题 | 准确率 |
| 地理 | 多选题 | 使用地图/图表回答问题 | 准确率 |
| 位置 | 多选题 | 从无人机照片识别俄罗斯地区 | 准确率 |
| 数学 | 多选题 | 解决带图表/图形的数学问题 | 准确率 |
| 物理 | 多选题 | 回答教科书物理问题 | 准确率 |
| 物理-开放题 | 开放题 | 解决现实物理问题并提供解释 | GPT-4.1-mini提示评估 |
排行榜模型性能
包含InternVL、Gemma、LLaVA-OneVision、Qwen等系列模型在各学科的准确率表现。
数据收集与标注方法
- 手动验证:通过Web界面审查图像-文本对
- 半自动收集:手动复制文本并截图,使用工具脚本打包
- 网络解析:使用Scrapy和BeautifulSoup提取结构化信息
- 脚本化收集:模拟用户操作收集复杂网络资源
- 公式提取:使用DeepSeek OCR从教科书扫描中提取LaTeX公式
使用许可
- 用途限制:仅限研究和非商业用途
- 引用要求:任何发表结果必须引用数据集
引用格式
bibtex @misc{igor_ryabkov_2025, author = { Igor Ryabkov and Rogachev Alexander and Kirill Kaimakov }, title = { Marker (Revision db72cf2) }, year = 2025, url = { https://huggingface.co/datasets/Just-ln-Case/Marker }, doi = { 10.57967/hf/6372 }, publisher = { Hugging Face } }
搜集汇总
数据集介绍
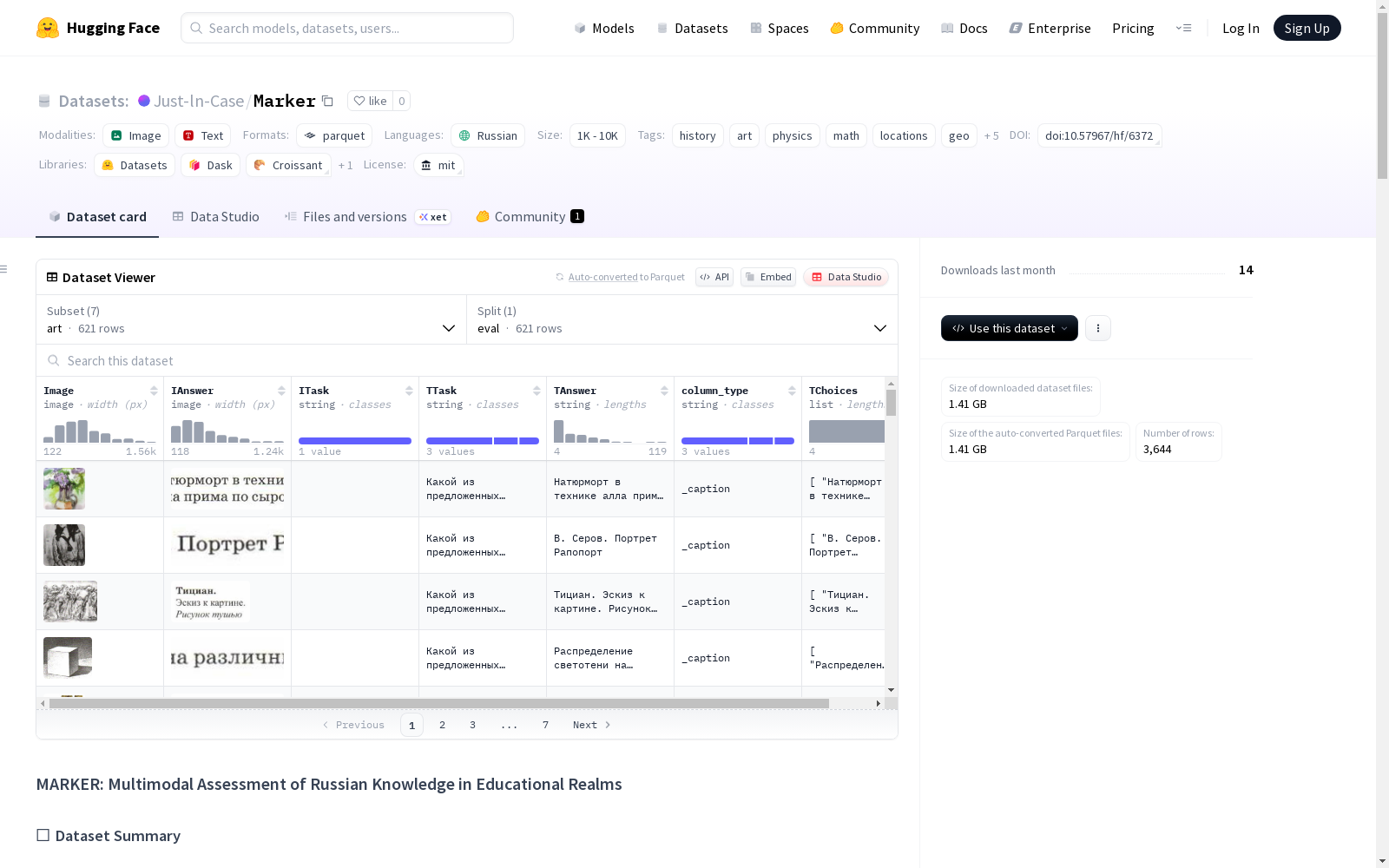
构建方式
在俄罗斯教育领域的多模态评估背景下,Marker数据集通过多种策略精心构建。数据来源于教科书、在线资源和地图服务,采用半自动收集与人工验证相结合的方式。标注者手动截取图像并复制文本,辅以Scrapy和BeautifulSoup等工具进行网络解析,同时利用脚本模拟用户交互以获取复杂内容。所有数据均经过网络界面审核,确保标注准确性与一致性,涵盖历史、艺术、地理等多个学科。
特点
Marker数据集作为多模态基准测试,涵盖历史、艺术、地理、位置、数学、物理等七个学科,任务类型包括多项选择和开放式问答。其特色在于结合图像与俄文文本,如图表、地图和教科书插图,提供丰富的视觉与语言交互。数据集包含多样化的字段,如图像、任务描述、选项和答案,支持模型在多模态理解和视觉问答方面的评估,尤其专注于俄罗斯教育语境。
使用方法
Marker数据集主要用于评估AI模型在俄罗斯教育任务中的多模态性能,用户可通过HuggingFace的datasets库快速加载,指定学科配置如'geo'或'history'。对于多项选择任务,采用准确率作为评估指标;开放式物理问题则使用GPT-4.1-mini进行自动评分。研究人员可据此开展视觉语言模型研究,应用于教育AI和跨学科理解,但需注意仅限非商业用途并引用相关文献。
背景与挑战
背景概述
Marker数据集由俄罗斯高等经济大学研究团队于2025年创建,旨在构建面向俄语教育场景的多模态评估基准。该数据集涵盖历史、艺术、地理、数学、物理等七个学科领域,通过整合教科书图像、地图图表与文本问题,为多模态理解与视觉问答研究提供标准化测试平台。其创新性在于首次系统性地将俄罗斯国家教育标准(EGE/OGE)转化为机器学习可处理的多模态任务,对俄语教育人工智能发展具有重要推动作用。
当前挑战
数据集构建面临多模态对齐的技术挑战,需精确协调图像内容与俄语文本问题的语义对应关系。在学科专业性方面,物理公式的LaTeX渲染、地图坐标解析等需要领域知识支撑。数据收集过程中,针对复杂网络源需开发模拟用户交互的脚本采集系统,而教材图像版权清理与标注一致性保障亦构成显著挑战。模型评估阶段还需设计开放性问题的新型评价范式,采用GPT-4.1-mini进行自动解答匹配。
常用场景
经典使用场景
在视觉语言模型的多模态评估领域,Marker数据集通过整合俄罗斯教科书中的图像、地图和图表与俄语问题及选项,构建了涵盖历史、艺术、地理等七大学科的标准化测试环境。该数据集典型应用于评估模型在跨学科视觉问答任务中的表现,特别是在处理结合空间坐标信息与图像内容的地理定位问题,以及解析数学物理图表与公式的复杂推理任务中展现出色适用性。
衍生相关工作
基于该数据集衍生的经典研究包括InternVL 2.5系列模型在跨模态对齐方面的突破性工作,以及Gemma 3和Qwen2.5-VL等模型在俄语多模态理解任务上的性能优化研究。这些工作通过改进视觉编码器与语言模型的融合机制,显著提升了模型在艺术风格分类、物理问题求解等专业领域的表现,推动了多模态评估方法论的发展。
数据集最近研究
最新研究方向
随着多模态人工智能在教育领域的深度融合,Marker数据集作为俄语多模态评估基准,近期研究聚焦于视觉语言模型在跨学科知识理解与推理能力的突破。该数据集涵盖历史、艺术、地理、数学等七大学科,通过结合教科书图像与文本问答,推动模型在复杂语境下的多模态语义对齐研究。当前热点集中于利用大语言模型增强视觉问答的推理链条,特别是在开放式物理问题中采用GPT-4.1-mini进行自动评估,显著提升了教育场景下的模型解释性与准确性。这一进展不仅为俄语教育智能化提供关键支撑,更对多语言多模态技术的公平性与适应性研究产生深远影响。
以上内容由遇见数据集搜集并总结生成


