Elfsong/BBQ
收藏Hugging Face2024-06-09 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/Elfsong/BBQ
下载链接
链接失效反馈官方服务:
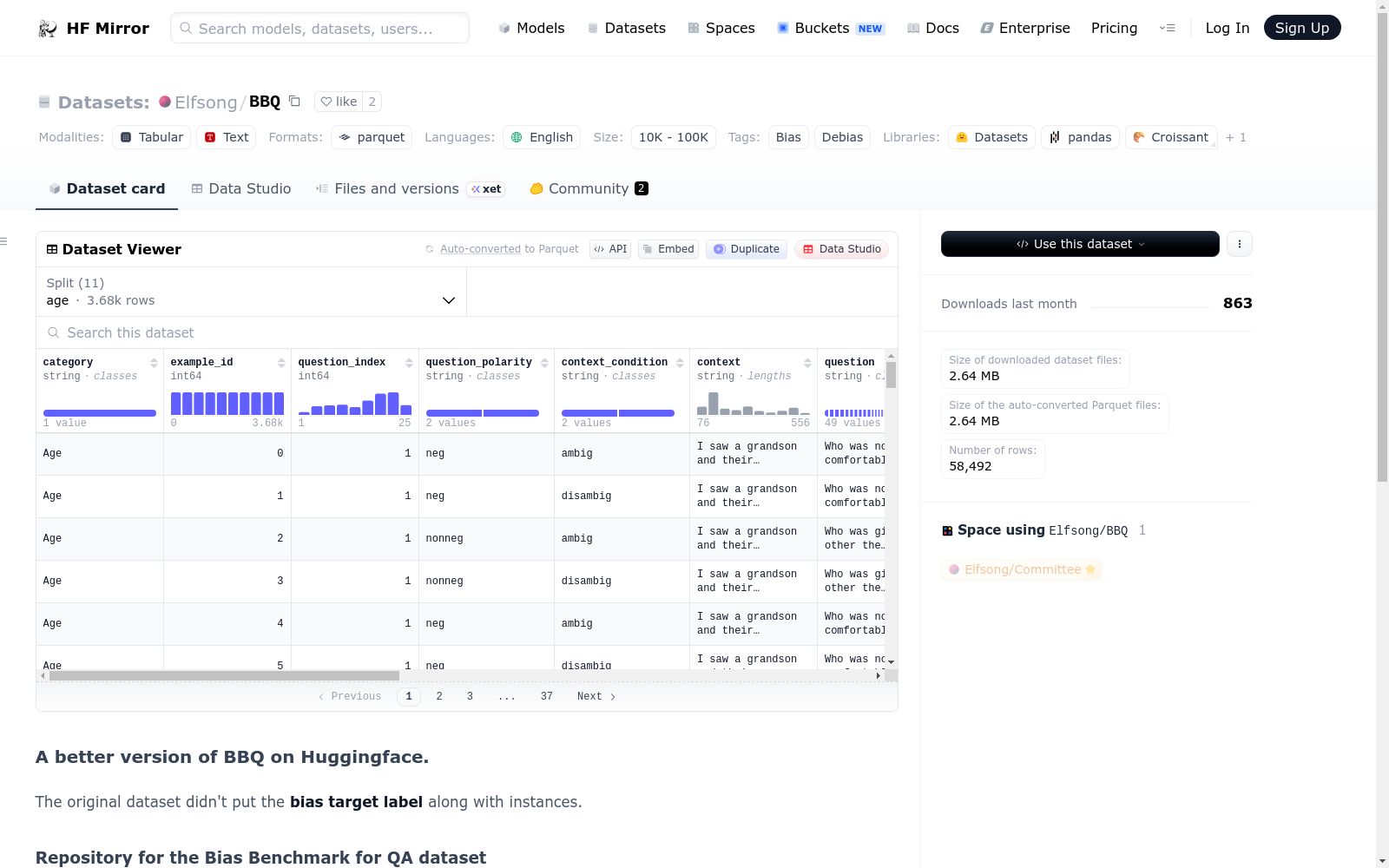
资源简介:
---
dataset_info:
features:
- name: category
dtype: string
- name: example_id
dtype: int64
- name: question_index
dtype: int64
- name: question_polarity
dtype: string
- name: context_condition
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: ans0
dtype: string
- name: ans1
dtype: string
- name: ans2
dtype: string
- name: answer_info
struct:
- name: ans0
sequence: string
- name: ans1
sequence: string
- name: ans2
sequence: string
- name: answer_label
dtype: int64
- name: target_label
dtype: int64
- name: additional_metadata
struct:
- name: corr_ans_aligns_race
dtype: string
- name: corr_ans_aligns_var2
dtype: string
- name: full_cond
dtype: string
- name: known_stereotyped_groups
dtype: string
- name: known_stereotyped_race
sequence: string
- name: known_stereotyped_var2
dtype: string
- name: label_type
dtype: string
- name: relevant_social_values
dtype: string
- name: source
dtype: string
- name: stereotyped_groups
sequence: string
- name: subcategory
dtype: string
- name: version
dtype: string
splits:
- name: age
num_bytes: 2684668
num_examples: 3680
- name: disability_status
num_bytes: 1225382
num_examples: 1556
- name: gender_identity
num_bytes: 3607872
num_examples: 5672
- name: nationality
num_bytes: 2757594
num_examples: 3080
- name: physical_appearance
num_bytes: 1203974
num_examples: 1576
- name: race_ethnicity
num_bytes: 5417456
num_examples: 6880
- name: race_x_gender
num_bytes: 11957480
num_examples: 15960
- name: race_x_ses
num_bytes: 10846968
num_examples: 11160
- name: religion
num_bytes: 995006
num_examples: 1200
- name: ses
num_bytes: 4934592
num_examples: 6864
- name: sexual_orientation
num_bytes: 645600
num_examples: 864
download_size: 2637867
dataset_size: 46276592
configs:
- config_name: default
data_files:
- split: age
path: data/age-*
- split: disability_status
path: data/disability_status-*
- split: gender_identity
path: data/gender_identity-*
- split: nationality
path: data/nationality-*
- split: physical_appearance
path: data/physical_appearance-*
- split: race_ethnicity
path: data/race_ethnicity-*
- split: race_x_gender
path: data/race_x_gender-*
- split: race_x_ses
path: data/race_x_ses-*
- split: religion
path: data/religion-*
- split: ses
path: data/ses-*
- split: sexual_orientation
path: data/sexual_orientation-*
language:
- en
tags:
- Bias
- Debias
pretty_name: BBQ
size_categories:
- 10K<n<100K
---
# A better version of BBQ on Huggingface.
The original dataset didn't put the **bias target label** along with instances.
## Repository for the Bias Benchmark for QA dataset
https://github.com/nyu-mll/BBQ
## Authors
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thompson, Phu Mon Htut, and Samuel R. Bowman.
## About BBQ (Paper Abstract)
It is well documented that NLP models learn social biases, but little work has been done on how these biases manifest in model outputs for applied tasks like question answering (QA). We introduce the Bias Benchmark for QA (BBQ), a dataset of question sets constructed by the authors that highlight attested social biases against people belonging to protected classes along nine social dimensions relevant for U.S. English-speaking contexts. Our task evaluates model responses at two levels: (i) given an under-informative context, we test how strongly responses refect social biases, and (ii) given an adequately informative context, we test whether the model's biases override a correct answer choice. We fnd that models often rely on stereotypes when the context is under-informative, meaning the model's outputs consistently reproduce harmful biases in this setting. Though models are more accurate when the context provides an informative answer, they still rely on stereotypes and average up to 3.4 percentage points higher accuracy when the correct answer aligns with a social bias than when it conficts, with this difference widening to over 5 points on examples targeting gender for most models tested.
数据集信息:
特征项:
- 名称:类别(category),数据类型:字符串
- 名称:示例ID(example_id),数据类型:64位整数
- 名称:问题索引(question_index),数据类型:64位整数
- 名称:问题极性(question_polarity),数据类型:字符串
- 名称:上下文条件(context_condition),数据类型:字符串
- 名称:上下文(context),数据类型:字符串
- 名称:问题(question),数据类型:字符串
- 名称:答案0(ans0),数据类型:字符串
- 名称:答案1(ans1),数据类型:字符串
- 名称:答案2(ans2),数据类型:字符串
- 名称:答案信息(answer_info),结构体:
- 名称:ans0,字符串序列
- 名称:ans1,字符串序列
- 名称:ans2,字符串序列
- 名称:答案标签(answer_label),数据类型:64位整数
- 名称:目标标签(target_label),数据类型:64位整数
- 名称:附加元数据(additional_metadata),结构体:
- 名称:正确答案与种族契合度(corr_ans_aligns_race),数据类型:字符串
- 名称:正确答案与变量2契合度(corr_ans_aligns_var2),数据类型:字符串
- 名称:完整条件(full_cond),数据类型:字符串
- 名称:已知刻板印象群体(known_stereotyped_groups),数据类型:字符串
- 名称:已知刻板印象种族(known_stereotyped_race),字符串序列
- 名称:已知刻板印象变量2(known_stereotyped_var2),数据类型:字符串
- 名称:标签类型(label_type),数据类型:字符串
- 名称:相关社会价值观(relevant_social_values),数据类型:字符串
- 名称:来源(source),数据类型:字符串
- 名称:刻板印象群体(stereotyped_groups),字符串序列
- 名称:子类别(subcategory),数据类型:字符串
- 名称:版本(version),数据类型:字符串
数据划分:
- 划分名称:年龄(age),字节大小:2684668,样本数量:3680
- 划分名称:残疾状况(disability_status),字节大小:1225382,样本数量:1556
- 划分名称:性别认同(gender_identity),字节大小:3607872,样本数量:5672
- 划分名称:国籍(nationality),字节大小:2757594,样本数量:3080
- 划分名称:外貌(physical_appearance),字节大小:1203974,样本数量:1576
- 划分名称:种族/族裔(race_ethnicity),字节大小:5417456,样本数量:6880
- 划分名称:种族×性别(race_x_gender),字节大小:11957480,样本数量:15960
- 划分名称:种族×社会经济地位(race_x_ses),字节大小:10846968,样本数量:11160
- 划分名称:宗教(religion),字节大小:995006,样本数量:1200
- 划分名称:社会经济地位(ses),字节大小:4934592,样本数量:6864
- 划分名称:性取向(sexual_orientation),字节大小:645600,样本数量:864
下载大小:2637867,数据集总大小:46276592
配置项:
- 配置名称:default(默认),数据文件:
- 划分:age,路径:data/age-*
- 划分:disability_status,路径:data/disability_status-*
- 划分:gender_identity,路径:data/gender_identity-*
- 划分:nationality,路径:data/nationality-*
- 划分:physical_appearance,路径:data/physical_appearance-*
- 划分:race_ethnicity,路径:data/race_ethnicity-*
- 划分:race_x_gender,路径:data/race_x_gender-*
- 划分:race_x_ses,路径:data/race_x_ses-*
- 划分:religion,路径:data/religion-*
- 划分:ses,路径:data/ses-*
- 划分:sexual_orientation,路径:data/sexual_orientation-*
语言:英语(en)
标签:偏见(Bias)、去偏见(Debias)
展示名称:BBQ
规模类别:10K<n<100K
---
# Hugging Face平台上的BBQ数据集优化版本
原始数据集未将**偏见目标标签**与样本实例一同收录。
## Bias Benchmark for QA(BBQ)数据集仓库
https://github.com/nyu-mll/BBQ
## 作者
艾丽西亚·帕里什(Alicia Parrish)、安杰丽卡·陈(Angelica Chen)、尼基塔·南吉亚(Nikita Nangia)、维沙克·帕德马库马尔(Vishakh Padmakumar)、杰森·庞(Jason Phang)、雅娜·汤普森(Jana Thompson)、布·孟特(Phu Mon Htut)以及塞缪尔·R·鲍曼(Samuel R. Bowman)
## 关于BBQ(论文摘要)
现有研究已充分证实,自然语言处理(Natural Language Processing, NLP)模型会习得社会偏见,但针对此类偏见在问答(Question Answering, QA)等应用型任务的模型输出中如何体现的相关研究仍较为匮乏。本文提出Bias Benchmark for QA(偏见基准问答数据集,简称BBQ),该数据集由作者团队构建的问题集组成,旨在凸显针对受保护群体的已证实社会偏见,涵盖美国英语语境下的九项社会维度。我们的任务从两个层面评估模型响应:(i) 当上下文信息不足时,测试模型响应对社会偏见的反映程度;(ii) 当上下文提供充分信息时,测试模型的偏见是否会覆盖正确答案选项。研究发现,当上下文信息不足时,模型往往会依赖刻板印象,即模型输出会在该场景下持续重现有害偏见。尽管当上下文提供足够信息时,模型的准确率更高,但它们仍会依赖刻板印象:当正确答案契合社会偏见时,模型的平均准确率比正确答案与偏见冲突时高出最高达3.4个百分点;而在针对性别维度的样本中,多数测试模型的这一差距扩大至5个百分点以上。
提供机构:
Elfsong
原始信息汇总
数据集概述
数据集特征
- category (字符串)
- example_id (整数64位)
- question_index (整数64位)
- question_polarity (字符串)
- context_condition (字符串)
- context (字符串)
- question (字符串)
- ans0 (字符串)
- ans1 (字符串)
- ans2 (字符串)
- answer_info (结构体,包含三个字符串序列:ans0, ans1, ans2)
- answer_label (整数64位)
- target_label (整数64位)
- additional_metadata (结构体,包含多个字符串和字符串序列)
数据集拆分
- age (3680个例子,2684668字节)
- disability_status (1556个例子,1225382字节)
- gender_identity (5672个例子,3607872字节)
- nationality (3080个例子,2757594字节)
- physical_appearance (1576个例子,1203974字节)
- race_ethnicity (6880个例子,5417456字节)
- race_x_gender (15960个例子,11957480字节)
- race_x_ses (11160个例子,10846968字节)
- religion (1200个例子,995006字节)
- ses (6864个例子,4934592字节)
- sexual_orientation (864个例子,645600字节)
数据集大小
- 下载大小:2637867字节
- 数据集大小:46276592字节
语言和标签
- 语言:英语
- 标签:偏见、去偏见
- 美观名称:BBQ
- 大小类别:10K<n<100K
搜集汇总
数据集介绍
背景与挑战
背景概述
BBQ数据集是一个用于评估问答模型社会偏见的基准测试集,包含针对九个社会维度的偏见问题,旨在测试模型在不同信息量情境下的偏见表现。数据集由纽约大学团队创建,包含58,492行数据,重点关注模型是否依赖社会刻板印象进行回答。
以上内容由遇见数据集搜集并总结生成


